
Databricks : Unity Catalog - Découverte - Partie 1 - Mise en place
Nous allons découvrir la solution Unity Catalog de Databricks et plus particulièrement comment la mettre en place sur un workspace existant.
Nous allons utiliser un Account Databricks sur AWS pour réaliser cette démonstration.
Note : Nous allons garder des termes techniques en anglais pour faciliter la compréhension
Note : Les travaux se basent sur l’état de la solution Unity Catalog à la fin du 1er trimestre 2023 sur AWS et Azure.
Introduction
En décembre 2021, Databricks a annoncé la disponibilité générale du SQL Warehouse. Cela représente une étape importante dans le développement de la plateforme Lakehouse afin de multiplier les usages des données stockées au format Delta. La gestion des données se faisait principalement en s’appuyant sur Hive Metastore, ce qui avait pour inconvénient d’être par défaut local à un Workspace Databricks. Cela signifiait qu’il fallait redéfinir les différents objets et la gestion des droits sur les différents Workspace Databricks nécessitant d’accéder aux données de la plateforme Lakehouse si on voulait utiliser un SQL Warehouse sur les différents Workspace Databricks.
Afin d’utiliser au mieux la plateforme Lakehouse et surtout de pouvoir gérer la gouvernance des données, nous attendions une solution de Databricks pour centraliser l’ensemble des métadonnées au niveau de l’Account Databricks et pouvoir faciliter le partage des informations entre Workspace Databricks.
A la fin de l’été 2022, Databricks a annoncé la disponibilité générale de la solution Unity Catalog sur AWS et sur Azure puis fin du 1er trimestre 2023, l’annonce a été faite sur GCP. Avec ces annonces, Unity Catalog est devenu la solution par défaut pour la gouvernance de données pour la plateforme Lakehouse de Databricks (aussi bien sur AWS, Azure et GCP).
A la fin de l’été 2022, Databricks a aussi annoncé la disponibilité générale du Delta Sharing qui est une solution ouverte ayant pour objectif de partager de manière efficace, simple et sécurisée les données gérées par la plateforme Lakehouse avec des outils/technologies tierces (Python, Java, Scala, Power BI, et bien d’autres) mais aussi avec d’autres Account Databricks (utilisant ou non la solution Unity Catalog).
A la fin de l’année 2022, Databricks a annoncé la disponibilité générale de la fonctionnalité Data Lineage. Cette fonctionnalité étant très importante pour pouvoir suivre le cycle de vie de l’ensemble des données sur la plateforme Lakehouse.
Afin de pouvoir rendre accessible au plus grand nombre la solution Unity Catalog qui est une solution clé dans l’utilisation et la gestion de la plateforme Lakehouse de Databricks, une série de 5 articles a été rédigée dans un esprit de découverte (pédagogique) pour mettre en place et utiliser les différents fonctionnalités de la solution Unity Catalog.
Les 5 articles ont été organisé de la manière suivante :
- Databricks : Unity Catalog - Découverte - Partie 1 - Mise en place
- Databricks : Unity Catalog - Découverte - Partie 2 - Gestion des données
- Databricks : Unity Catalog - Découverte - Partie 3 - Data Lineage
- Databricks : Unity Catalog - Découverte - Partie 4 - Delta Sharing
- Databricks : Unity Catalog - Découverte - Partie 5 - Delta Live Tables
Attention : Les travaux se basent sur l’état de la solution Unity Catalog à la fin du 1er trimestre 2023 sur AWS et Azure.
Nous allons utiliser les outils suivants :
Qu’est-ce qu’un métastore
Un métastore est un référentiel permettant de stocker un ensemble de métadonnées liés aux données (stockage, usage, options).
Une métadonnée est une information sur une donnée permettant de définir son contexte (description, droits, date et heure technique de création ou mise à jour, créateur, …) et son usage (stockage, structure, accès, …).
Un métastore peut être local à une instance d’une ressource (un cluster, un workspace) ou central à l’ensemble des ressources gérant des données.
Dans une entreprise ayant une gouvernance de données basée sur un modèle Data Lake, Datawarehouse ou Lakehouse par exemple, nous allons conseiller de mettre en place un métastore centralisé permettant de stocker l’ensemble des métadonnées des données de l’entreprise pour pouvoir faciliter la gouvernance, l’usage et le partage des données à l’ensemble des équipes.
Qu’est ce que la solution Unity Catalog
Unity Catalog est la solution de Databricks permettant d’avoir une gouvernance unifiée et centralisée pour l’ensemble des données gérées par les ressources Databricks ainsi que de sécuriser et faciliter la gestion et le partage des données à l’ensemble des acteurs internes et externes d’une organisation.
L’utilisation interne se fait en partageant un métastore d’Unity Catalog sur l’ensemble des workspaces Databricks.
L’utilisation externe se fait en utilisant la fonctionnalité “Delta Sharing” de l’Unity Catalog ou par l’usage de la fonctionnalité SQL Warehouse par un outil externe (connecteur JDBC, ODC ou partenaires databricks).
Quelques exemples de fonctionnalités proposées par la solution Unity Catalog :
- Gestion des droits sur les objets par des groupes et des utilisateurs en utilisant une syntaxe SQL ANSI
- Gestion des objets permettant d’être créés dans un workspace Databricks et utilisés par l’ensemble des workspaces Databricks utilisant Unity Catalog
- Possibilité de partager les données de manière simple et sécurisée en passant par la fonctionnalité Delta Sharing
- Permet de capturer des informations sur le cycle de vie et la provenance des données (Data Lineage)
- Permet de capturer l’ensemble des logs pour être en capacité de faire l’audit des accès et de l’utilisation des données
Vous pourrez avec une vue d’ensemble plus complète en parcourant la documentation officielle
Hiérarchie des objets
Avant d’aller plus loin, nous allons introduire la hiérarchie des objets au sein de la solution Unity Catalog. Nous allons nous concentrer uniquement sur les éléments nécessaires à la mise en place de la solution Unity Catalog.
Schématisation de la hiérarchie des objets :
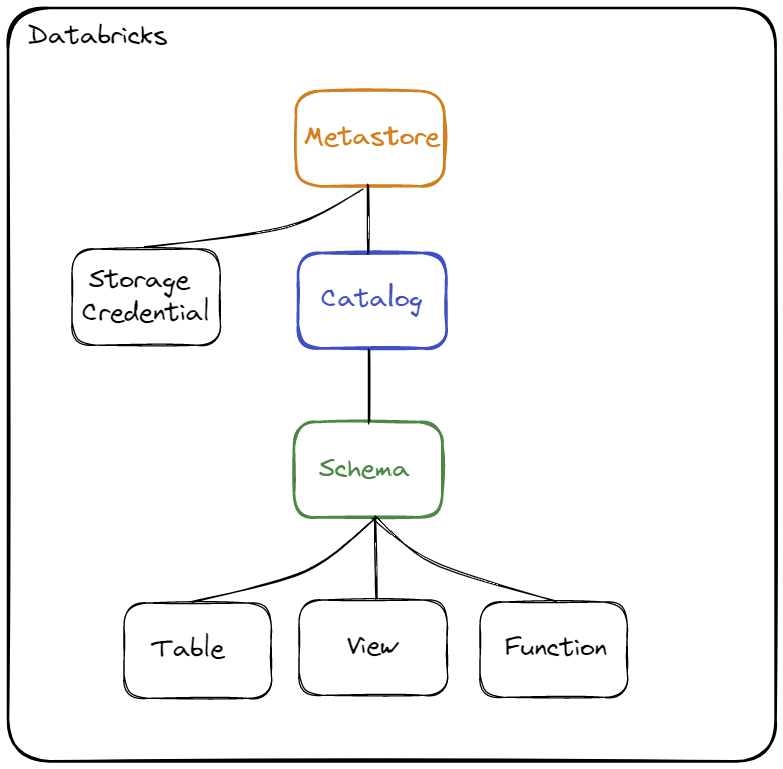
La hiérarchie des objets est constituée des trois niveaux suivants :
- Metastore (métastore) :
- C’est l’objet le plus haut niveau pouvant contenir des métadonnées
- Il ne peut y avoir qu’un seul Metastore par région
- Un Metastore doit être rattaché à un Workspace pour pouvoir être utilisé
- Le Metastore doit avoir la même région que le Workspace auquel il est rattaché
- Catalog (catalogue) :
- C’est le 1er niveau de la hiérarchie permettant d’organiser les données
- Il permet d’organiser les objets (données) par Schéma (aussi nommé Base de données)
- Si l’on souhaite pouvoir avoir plusieurs environnements dans un même Metastore (dans une même région) alors on pourra créer un Catalog par environnement
- Schema (schéma ou base de données) :
- C’est le 2ème et dernier niveau de la hiérarchie permettant d’organiser les données
- Ce niveau permet de stocker l’ensemble des métadonnées sur les objets de type Table, Vue ou Fonction
Lorsque vous souhaitez accéder à un objet (par exemple une table), il sera nécessaire de renseigner le catalogue et le schéma où est défini l’objet.
Exemple : select ... from catalog.schema.table
Objet utilisé par la solution Unity Catalog pour gérer l’accès global aux données :
- Storage Credential : Cet objet est associé directement au Metastore et permet de stocker les accès à un cloud provider (par exemple AWS S3) permettant à la solution Unity Catalog de gérer les droits sur les données.
Objets utilisés par la solution Unity Catalog pour stocker et gérer les métadonnées (usage des données):
- Table : Objet permettant de définir la structure et le stockage des données.
- Managed Table : Table dont la donnée est directement gérée par la solution Unity Catalog et dont le format est Delta
- External Table : Table dont la donnée n’est pas directement gérée par la solution Unity Catalog (l’utilisateur défini le chemin d’accès à la donnée) et dont le format peut être Delta, CSV, JSON, Avro, Parquet, ORC ou Texte
- View (Vue) : Objet permettant d’encapsuler une requête utilisant un ou plusieurs objets (table ou vue)
- Function (Fonction) : Objet permettant de définir des opérations sur les données
Quelques informations concernant les quotas des objets sur la solution Unity Catalog :
- Un Metastore peut contenir jusqu’à 1000 catalogues
- Un Metastore peut contenir jusqu’à 200 objets Storage Credential
- Un catalogue peut contenir jusqu’à 10000 schémas
- Un schéma peut contenir jusqu’à 10000 tables (ou vues) et 10000 fonctions
Contexte
Pour cette démonstration, nous allons nous concentrer uniquement sur la mise en place d’un Metastore de la solution Unity Catalog sur un Account Databricks sur AWS.
Dans un contexte projet/entreprise, il est recommandé d’utiliser l’outil Terraform afin de pouvoir gérer l’infrastructure avec du code (IaC) et rendre reproductible les éléments.
Dans le contexte de cette démonstration, nous allons volontairement utiliser des lignes de commandes pour rendre plus clair et didactique notre démarche.
Nous allons utiliser principalement les deux outils suivants :
- Databricks CLI : Interface de ligne de commande permettant de faciliter l’utilisation et la configuration des ressources Databricks
- AWS CLI : Interface de ligne de commande permettant de faciliter l’utilisation et la configuration des ressources AWS
Schématisation
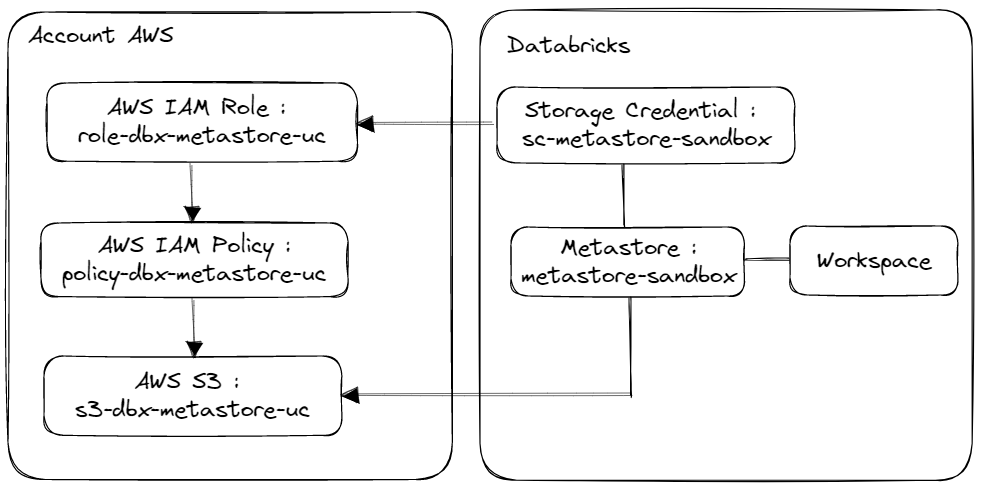
Schéma de l’ensemble des éléments que nous allons mettre en place pour pouvoir utiliser la solution Unity Catalog avec un Workspace Databricks.
Prérequis
Les éléments suivants sont nécessaires avant de démarrer les actions :
- Le Workspace doit être dans un plan Premium ou supérieur
- Vous devez avoir un Account Databricks sur AWS
- Vous devez avoir un Workspace Databricks basé sur la région “eu-west-1”
- Vous devez avoir un compte utilisateur Databricks avec les droits d’administration sur l’Account Databricks
- Vous devez avoir un compte utilisateur AWS avec les droits d’administration sur les ressources AWS S3 et AWS IAM
Afin d’utiliser les outils Databricks CLI et AWS CLI vous devez avoir créé les éléments suivants :
- Un Token Utilisateur pour Databricks pour utiliser Databricks CLI
- Un Token Utilisateur AWS pour utiliser AWS CLI Note : Vous trouverez la démarche pour la configuration des outils AWS CLI et Databricks CLI dans les ressources de cette article
Information concernant le rôle global Databricks pour la gestion des accès AWS par Unity Catalog :
- AWS IAM Role Unity Catalog :
arn:aws:iam::414351767826:role/unity-catalog-prod-UCMasterRole-14S5ZJVKOTYTL
Information concernant le Databricks Workspace ID :
- En se basant sur l’URL du Workspace Databricks
https://<databricks-instance>.com/o=XXXXX, le Databricks Workspace ID est le numéro représenté parXXXXX.
Les étapes à réaliser
Pour mettre en place la solution Unity Catalog et créer le Metastore nécessaire, nous allons réaliser les étapes suivantes :
- Création d’une ressource AWS S3
- Création d’une Politique (Policy) et d’un Rôle (AWS IAM) pour gérer l’accès à la ressource AWS S3 avec la ressource AWS IAM
- Création d’un Metastore
- Création d’un Storage Credential
- Association d’un Storage Credential à un Metastore
- Association d’un Metastore avec un Workspace Databricks
Mise en place
Étape n°0 : Initialisation des variables d’environnement
Création des variables d’environnement permettant de définir les nommage et de faciliter la rédaction des commandes
1# AWS Variables
2export AWS_S3_DBX_UC="s3-dbx-metastore-uc"
3export AWS_IAM_ROLE_DBX_UC="role-dbx-metastore-uc"
4export AWS_IAM_POLICY_DBX_UC="policy-dbx-metastore-uc"
5export AWS_TAGS='{"TagSet": [{"Key": "owner","Value": "admin"},{"Key": "project","Value": "databricks"}]}'
6
7# Databricks Variables
8export DBX_WORKSPACE_ID="0000000000000000"
9export DBX_METASTORE_NAME="metastor-sandbox"
10export DBX_METASTORE_SC="sc-metastore-sandbox"
11
12
13# AWS Variables to define during the steps executions
14export AWS_IAM_ROLE_DBX_UC_ARN=""
15export AWS_IAM_POLICY_DBX_UC_ARN=""
16
17# Databricks Variables to define during the steps executions
18export DBX_METASTORE_ID=""
19export DBX_METASTORE_SC_ID=""
Étape n°1 : Création de la ressource AWS S3
Cette ressource AWS S3 sera utilisée par Unity Catalog pour stocker les données des objets “Managed” et les métadonnées.
Exécution des commandes suivantes en s’appuyant sur AWS CLI :
1# Bucket creation
2aws s3api create-bucket --bucket ${AWS_S3_DBX_UC} --create-bucket-configuration LocationConstraint=eu-west-1
3# Add Encryption information
4aws s3api put-bucket-encryption --bucket ${AWS_S3_DBX_UC} --server-side-encryption-configuration '{"Rules": [{"ApplyServerSideEncryptionByDefault": {"SSEAlgorithm": "AES256"},"BucketKeyEnabled": true}]}'
5# Revoke public access
6aws s3api put-public-access-block --bucket ${AWS_S3_DBX_UC} --public-access-block-configuration '{"BlockPublicAcls": true,"IgnorePublicAcls": true,"BlockPublicPolicy": true,"RestrictPublicBuckets": true}'
7# Add ownership controls information
8aws s3api put-bucket-ownership-controls --bucket ${AWS_S3_DBX_UC} --ownership-controls '{"Rules": [{"ObjectOwnership": "BucketOwnerEnforced"}]}'
9# Add tags
10aws s3api put-bucket-tagging --bucket ${AWS_S3_DBX_UC} --tagging ${AWS_TAGS}
Étape n°2 : Création d’une politique et d’un rôle avec la ressource AWS IAM
La politique et le rôle vont permettre de donner les droits d’administration à la solution Unity Catalog pour gérer les accès aux données.
Exécution des commandes suivantes en s’appuyant sur AWS CLI :
1
2# Create JSON config file for role creation (init)
3cat > tmp_role_document.json <<EOF
4{
5 "Version": "2012-10-17",
6 "Statement": [
7 {
8 "Effect": "Allow",
9 "Principal": {
10 "AWS": [
11 "arn:aws:iam::414351767826:role/unity-catalog-prod-UCMasterRole-14S5ZJVKOTYTL"
12 ]
13 },
14 "Action": "sts:AssumeRole",
15 "Condition": {
16 "StringEquals": {
17 "sts:ExternalId": "<AWS Account Databricks ID>"
18 }
19 }
20 }
21 ]
22}
23EOF
24
25
26
27# Role creation
28aws iam create-role --role-name ${AWS_IAM_ROLE_DBX_UC} --assume-role-policy-document file://tmp_role_document.json
29# Get the role ARN
30export AWS_IAM_ROLE_DBX_UC_ARN=`aws_ippon_dtl iam get-role --role-name ${AWS_IAM_ROLE_DBX_UC} | jq '.Role.Arn'`
31
32
33
34# Create JSON config file for role update
35cat > tmp_role_document_update.json <<EOF
36{
37 "Version": "2012-10-17",
38 "Statement": [
39 {
40 "Effect": "Allow",
41 "Principal": {
42 "AWS": [
43 ${AWS_IAM_ROLE_DBX_UC_ARN},
44 "arn:aws:iam::414351767826:role/unity-catalog-prod-UCMasterRole-14S5ZJVKOTYTL"
45 ]
46 },
47 "Action": "sts:AssumeRole",
48 "Condition": {
49 "StringEquals": {
50 "sts:ExternalId": "<AWS Account Databricks ID>"
51 }
52 }
53 }
54 ]
55}
56EOF
57
58# Add reference on himself
59aws iam update-assume-role-policy --role-name ${AWS_IAM_ROLE_DBX_UC} --policy-document file://tmp_role_document_update.json
60# Add tags
61aws iam tag-role --role-name ${AWS_IAM_ROLE_DBX_UC} --tags ${AWS_TAGS}
62# Add description
63aws iam update-role-description --role-name ${AWS_IAM_ROLE_DBX_UC} --description 'This role is used for storing Databricks Unity Catalog metadata to S3 Resources'
64
65
66
67
68# Create JSON config file for policy creation
69cat > tmp_policy_document.json <<EOF
70{
71 "Version": "2012-10-17",
72 "Statement": [
73 {
74 "Action": [
75 "s3:GetObject",
76 "s3:PutObject",
77 "s3:DeleteObject",
78 "s3:ListBucket",
79 "s3:GetBucketLocation",
80 "s3:GetLifecycleConfiguration",
81 "s3:PutLifecycleConfiguration"
82 ],
83 "Resource": [
84 "arn:aws:s3:::${AWS_S3_DBX_UC}/*",
85 "arn:aws:s3:::${AWS_S3_DBX_UC}"
86 ],
87 "Effect": "Allow"
88 },
89 {
90 "Action": [
91 "sts:AssumeRole"
92 ],
93 "Resource": [
94 ${AWS_IAM_ROLE_DBX_UC_ARN}
95 ],
96 "Effect": "Allow"
97 }
98 ]
99}
100EOF
101
102# Policy creation
103aws iam create-policy --policy-name ${AWS_IAM_POLICY_DBX_UC} --policy-document file://tmp_policy_document.json > tmp_result_creation_policy.json
104# Get Policy ARN
105export AWS_IAM_POLICY_DBX_UC_ARN=`cat tmp_result_creation_policy.json | jq '.Policy.Arn'`
106# Add tags
107aws iam tag-policy --policy-arn ${AWS_IAM_POLICY_DBX_UC_ARN} --tags ${AWS_TAGS}
108
109
110# Attach Policy to the Role
111aws iam attach-role-policy --role-name ${AWS_IAM_ROLE_DBX_UC} --policy-arn ${AWS_IAM_POLICY_DBX_UC_ARN}
112
113
114# Delete temporary JSON files
115rm tmp_role_document_update.json
116rm tmp_role_document.json
117rm tmp_policy_document.json
118rm tmp_result_creation_policy.json
Step n°3 : Création d’un Metastore
Création d’un Metastore Unity Catalog dans la même région que le Workspace avec lequel nous voulons l’utiliser.
Exécution des commandes suivantes en s’appuyant sur Databricks CLI :
1# Create metastore
2databricks unity-catalog metastores create --name ${DBX_METASTORE_NAME} \
3 --storage-root s3://${AWS_S3_DBX_UC}/${DBX_METASTORE_NAME}
4
5
6# Get the metastore ID
7export DBX_METASTORE_ID=`databricks unity-catalog metastores get-summary | jq 'select(.name == $ENV.DBX_METASTORE_NAME) | .metastore_id'`
8
9# Check the metastore ID (it must not be empty)
10echo ${DBX_METASTORE_ID}
Étape n°4 : Création d’un Storage Credential
Création d’un Storage Credential pour stocker les accès pour le rôle global Databricks sur la ressource AWS S3 utilisée pour stocker les données du Metastore.
Exécution des commandes suivantes en s’appuyant sur Databricks CLI :
1# Create JSON config file
2cat > tmp_databricks_metastore_storagecredential.json <<EOF
3{
4 "name": ${DBX_METASTORE_SC},
5 "aws_iam_role": {
6 "role_arn": ${AWS_IAM_ROLE_DBX_UC_ARN}
7 },
8 "comment" : "Storage Credential for Unity Catalog Storage"
9}
10EOF
11
12# Create Storage Credential
13databricks unity-catalog storage-credentials create --json-file tmp_databricks_metastore_storagecredential.json
14
15# Get Storage Credential ID
16export DBX_METASTORE_SC_ID=`databricks unity-catalog storage-credentials get --name ${DBX_METASTORE_SC} | jq '.id'`
17
18# Delete temporary files
19rm tmp_databricks_metastore_storagecredential.json
Étape n°5 : Association d’un Storage Credential avec un Metastore
Afin que le Metastore puisse utiliser le Storage Credential pour accéder à la ressource AWS S3 et pour pouvoir gérer les accès sur les données pour l’ensemble des utilisateurs, nous devons associer le Storage Credential au Metastore.
Exécution des commandes suivantes en s’appuyant sur Databricks CLI :
1# Create JSON config file
2cat > tmp_databricks_metastore_update_sc.json <<EOF
3{
4 "default_data_access_config_id": ${DBX_METASTORE_SC_ID},
5 "storage_root_credential_id": ${DBX_METASTORE_SC_ID}
6}
7EOF
8
9# Update Metastore with the Storage Credential
10databricks unity-catalog metastores update --id ${DBX_METASTORE_ID} \
11 --json-file tmp_databricks_metastore_update_sc.json
12
13# Delete temporary files
14rm tmp_databricks_metastore_update_sc.json
Étape n°6 : Association d’un Metastore à un Workspace Databricks
Pour pouvoir utiliser le Metastore avec un Workspace Databricks, il est nécessaire d’assigner le Metastore au Workspace Databricks au niveau de l’account Databricks. Note : il est possible de définir le nom du catalogue par défaut pour les utilisateurs du Workspace.
Exécution des commandes suivantes en s’appuyant sur Databricks CLI :
1databricks unity-catalog metastores assign --workspace-id ${DBX_WORKSPACE_ID} \
2 --metastore-id ${DBX_METASTORE_ID} \
3 --default-catalog-name main
Étape n°7 : Nettoyage des variables d’environnements
Nous pouvons supprimer l’ensemble des variables d’environnements utilisées lors de la mise en place d’Unity Catalog.
1# Clean the AWS & Databricks Attributes
2unset AWS_S3_DBX_UC
3unset AWS_IAM_ROLE_DBX_UC
4unset AWS_IAM_POLICY_DBX_UC
5unset AWS_TAGS
6unset DBX_WORKSPACE_ID
7unset DBX_METASTORE_NAME
8unset DBX_METASTORE_SC
9unset AWS_IAM_ROLE_DBX_UC_ARN
10unset AWS_IAM_POLICY_DBX_UC_ARN
11unset DBX_METASTORE_ID
12unset DBX_METASTORE_SC_ID
Conclusion
A l’aide des outils Databricks CLI et AWS CLI, nous avons pu très facilement mettre en place un Metastore sur notre Workspace Databricks afin de pouvoir utiliser la solution Unity Catalog.
Cela nous a permis de mettre en place simplement une solution permettant de gérer notre référentiel centralisé de métadonnées pour l’ensemble des données gérées et manipulées par nos ressources Databricks (Cluster et SQL Warehouse).
Les avantages de l’utilisation de la solution Unity Catalog :
- Unity Catalog permet de simplifier et centraliser la gestion des droits sur l’ensemble des objets gérés.
- Unity Catalog permet de sécuriser, faciliter et multiplier les usages sur les données grâce aux nombreux connecteurs pour SQL Warehouse ainsi que la possibilité d’exporter les informations vers d’autres outils de gestion de catalogue de données.
- Unity Catalog est un outil qui s’améliore régulièrement et qui devrait devenir la référence pour la gouvernance des données pour tous ceux qui utilisent Databricks.
Quelques informations concernant les limitations sur la solution Unity Catalog :
- Le Workspace Databricks doit être au moins au niveau premium pour pouvoir utiliser la solution Unity Catalog
- Un Metastore doit contenir l’ensemble des éléments concernant une région.
- Il est recommandé d’utiliser un cluster avec le Databricks Runtime en version 11.3 LTS (DBR) ou supérieur
- La création d’un Storage Credential n’est possible qu’avec un rôle AWS IAM lorsque l’Account Databricks est sur AWS
- Une partie de la gestion des utilisateurs et groupes doit se faire au niveau de l’Account Databricks et non plus seulement au niveau du Workspace Databricks
- Les groupes définis localement dans un Workspace Databricks ne peuvent pas être utilisés avec Unity Catalog, il est nécessaire de les recréer au niveau de l’Account Databricks pour pouvoir les utiliser avec la solution Unity Catalog (Migration).
Ressources
Glossaire
- Account Databricks : Niveau le plus haut pour l’administration de Databricks
- Cluster Databricks : Ensemble de ressources de calcul permettant d’exécuter des traitements Spark avec Databricks
- Workspace Databricks : Espace de travail dans Databricks
- Databricks Workspace ID : Identifiant du workspace Databricks
- Storage Credential : Objet permettant le stockage des accès par la solution Unity Catalog
- Data Lake : Lac de données permettant de stocker des données structurée, semi-structurée ou non structurée
- Data Warehouse : Entrepôt de données permettant de stocker des données structurées (Base de données relationnelle)
- Lakehouse : Architecture de gestion des données qui combine les avantages d’un lac de données et les fonctionnalités de gestion d’un entrepôt de données
- Metastore : un métastore dans la solution Unity Catalog
- Catalog (Catalgoue) : Objet de la solution Unity Catalog permettant d’organiser les données (objets) par Schéma
- External Table (Table externe) : Table dont la donnée n’est pas directement géré par la solution Unity Catalog (l’utilisateur défini le chemin d’accès à la donnée)
- Managed Table (Table managée) : Table dont la donnée est directement géré par la solution Unity Catalog
- Databricks CLI : Interface de ligne de commande permettant de faciliter l’utilisation et la configuration des ressources Databricks
- AWS CLI : Interface de ligne de commande permettant de faciliter l’utilisation et la configuration des ressources AWS
- AWS S3 : Service AWS Simple Storage permettant de stocker des données/objets
- AWS IAM : Service AWS Identity and Access Management permettant de contrôler l’accès aux services et aux ressources AWS.
- AWS IAM Policy : Politique de droit sur AWS IAM
Gestion de la connexion pour l’outil AWS CLI
Installez l’outil
AWS CLIsur macOS avec l’outil Homebrew :brew install awscliDéfinissez un utilisateur spécifique pour AWS CLI : (pour l’exemple, nous avons pris le nom
usr_adm_cli)- Allez sur
AWS IAM > Users - Cliquez sur
Add users - Renseigner l’information “User Name” :
usr_adm_cliet cliquez surNext - Si vous avez un groupe d’administration (AWS IAM Group) déjà défini :
- Sélectionnez
Add user to group - Sélectionnez le groupe souhaité :
FullAdminet cliquez surNext
- Sélectionnez
- Si vous avez une politique d’administration (AWS IAM Policy) déjà définie :
- Sélectionnez
Attach policies directly - Sélectionnez la politique souhaitée :
AdministratorAccesset cliquez surNext
- Sélectionnez
- Si vous souhaitez définir des tags : Cliquez sur
Add new taget ajoutez les informations souhaités - Cliquez sur
Create user - Sélectionnez l’utilisateur créé
usr_adm_cli - Cliquez sur
Security credentials - Cliquez sur
Create access key - Sélectionnez
Command Line Interface (CLI), cochez sur l’optionI understand the above .... to proceed to create an access keyet cliquez surNext - Renseignez l’information
Description tag value:administrationet cliquez surCreate access key - Copiez les informations
Access keyetSecret access keypour pouvoir les utiliser avec l’outil AWS CLI (ces informations ne seront plus accessibles après avoir quitté la page)
- Allez sur
Configurez l’outil AWS CLI avec le nouvel utilisateur créé :
- Exécutez la commande :
aws configure- Renseignez l’information
AWS Access Key IDavec l’informationAccess keydu nouvel utilisateurusr_adm_cli - Renseignez l’information
AWS Secret Access Keyavec l’informationSecret access keydu nouvel utilisateurusr_adm_cli - Renseignez l’information
Default region nameavec la région par défaut :eu-west-1 - Renseignez l’information
Default output formatavec le format de sortie par défautjson
- Renseignez l’information
- Exécutez la commande :
Vérification de la configuration de l’outil AWS CLI
- Exécutez la commande
aws s3api list-buckets - Résultat :
- Exécutez la commande
1{
2 "Buckets": [
3 {...}
4 ]
5}
Gestion de la connexion pour l’outil Databricks CLI
Installez l’outil
Databricks CLIavecpip(nécessite d’avoir python3)- Exécutez la commande :
pip install databricks-cli - Vérifiez le résultat avec la commande :
databricks --version(Résultat possible :Version 0.17.6)
- Exécutez la commande :
Créez un Token Utilisateur sur Databricks
- Allez sur le workspace Databricks
- Cliquez sur votre nom d’utilisateur et cliquez sur l’option
User Settings - Cliquez sur
Access tokens - Cliquez sur
Generate new token - Renseignez les parties
commentetdefine the token life timeavec les valeurs souhaitées - Cliquez sur
Generate - Copiez le Token Databricks généré pour pouvoir l’utiliser avec l’outil Databricks CLI (vous ne pourrez plus le voir après avoir quitté la page)
Configurez Databricks CLI
- Exécutez la commande :
databricks configure --token - Renseignez l’information
Databricks Host (should begin with https://):avec l’URL de votre workspace Databricks :https://dbc-XXXXXXXX-XXXX.cloud.databricks.com - Renseignez l’information
Access Tokenavec le Token Databricks récupéré lors de l’étape précédente :dapi2c0000aa000a0r0a00e000000000000
- Exécutez la commande :
Vous pouvez voir les informations enregistrées avec la commande : cat ~/.databrickscfg