
Databricks : Unity Catalog - Découverte - Partie 2 - Gestion des données
Nous allons découvrir la gestion des données par la solution Unity Catalog et plus précisément la gestion des droits (Groupes et Utilisateurs) et la gestion du stockage (Tables).
Nous allons utiliser un Account Databricks sur AWS pour réaliser cette démonstration.
Note : Nous allons garder des termes techniques en anglais pour faciliter la compréhension
Note : Les travaux se basent sur l’état de la solution Unity Catalog à la fin du 1er trimestre 2023 sur AWS et Azure.
Unity Catalog et la hiérarchie des objets
Unity Catalog est la solution de Databricks permettant d’avoir une gouvernance unifiée et centralisée pour l’ensemble des données gérées par les ressources Databricks ainsi que de sécuriser et faciliter la gestion et le partage des données à l’ensemble des acteurs internes et externes d’une organisation.
Vous pourrez avec une vue d’ensemble plus complète en parcourant la documentation officielle
Rappel concernant la hiérarchie des objets :
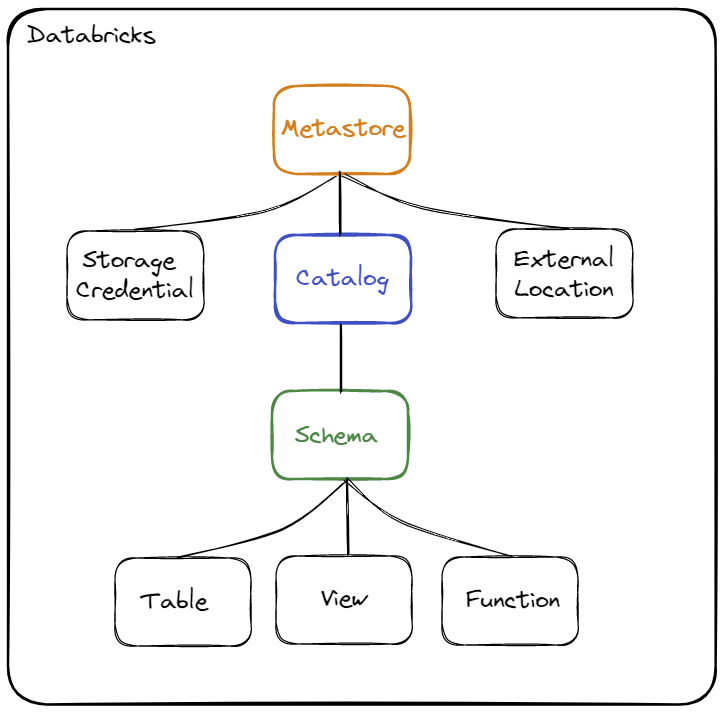
Les différents objets sont :
- Storage Credential : Cet objet est associé directement au Metastore et permet de stocker les accès à un cloud provider (par exemple AWS S3) permettant à la solution Unity Catalog de gérer les droits sur les données.
- External Location : Cet objet est associé au Metastore et permet de stocker le chemin vers un cloud provider (par exemple une ressource AWS S3) en combinaison avec un Storage Credential pour gérer les accès aux données
- Metastore : Objet du plus haut niveau pouvant contenir des métadonnées
- Catalog (Catalogue) : Objet de 1er niveau permettant d’organiser les données par schéma (aussi nommé Base de données)
- Schema (Schéma) : Objet de 2ème et dernier niveau permettant d’organiser les données (contient les tables, les vues et les fonctions)
- Table : Objet permettant de définir la structure et le stockage des données.
- View : Objet permettant d’encapsuler une requête utilisant un ou plusieurs objets (table ou vue)
- Function : Objet permettant de définir des opérations sur les données
Lorsque vous souhaitez accéder à un objet (par exemple une table), il sera nécessaire de renseigner le nom du catalogue et le nom du schéma où est défini l’objet.
Exemple : select * from catalog.schema.table
Préparation des éléments
Pour cette découverte, nous allons mettre en place un certain nombre d’éléments permettant de manipuler les différents concepts.
Synthèse
Concernant les ressources Databricks :
- La solution Unity Catalog doit être activée au niveau de l’Account Databricks
- Un Metastore Unity Catalog doit être rattaché au Workspace Databricks
- Un SQL Warehouse doit exister dans le Workspace Databricks
Concernant les groupes et utilisateurs,
Nous allons reproduire les éléments suivants :
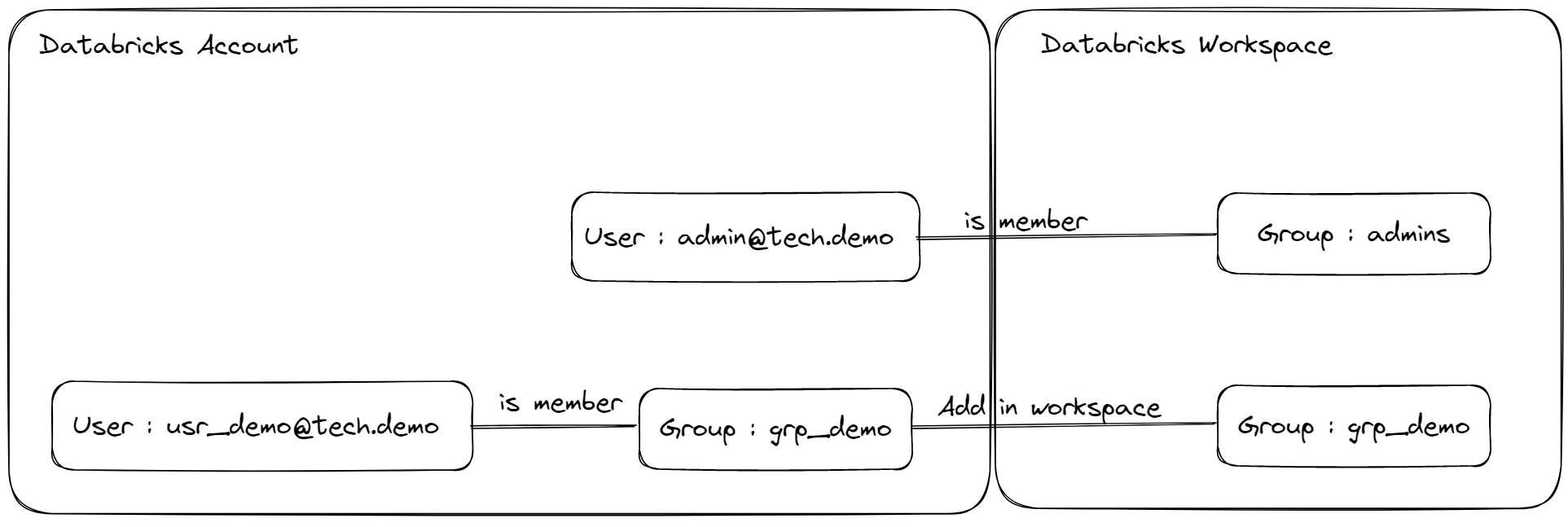
Pré-requis :
- Un utilisateur avec les droits d’administration sur l’Account Databricks et sur le Workspace Databricks
- Il ne doit pas exister de groupe nommé
grp_demoau niveau de l’Account Databricks et au niveau du Workspace Databricks - Il ne doit pas exister d’utilisateur nommé
john.do.dbx@gmail.comau niveau de l’Account Databricks et au niveau du Workspace Databricks
Synthèse des actions qui seront réalisées :
- Création d’un groupe nommé
grp_demoau niveau de l’Account Databricks. - Création d’un utilisateur nommé
john.do.dbx@gmail.comau niveau de l’Account Databricks. - Ajout du groupe
grp_democréé au niveau de l’Account Databricks dans le Workspace Databricks - Ajout des droits sur le Workspace Databricks sur le groupe
grp_demo - Ajout des droits nécessaires sur les objets de l’Unity Catalog au niveau du Workspace Databricks sur le groupe
grp_demo
Concernant les objets d’Unity Catalog,
Nous allons reproduire les éléments suivants :
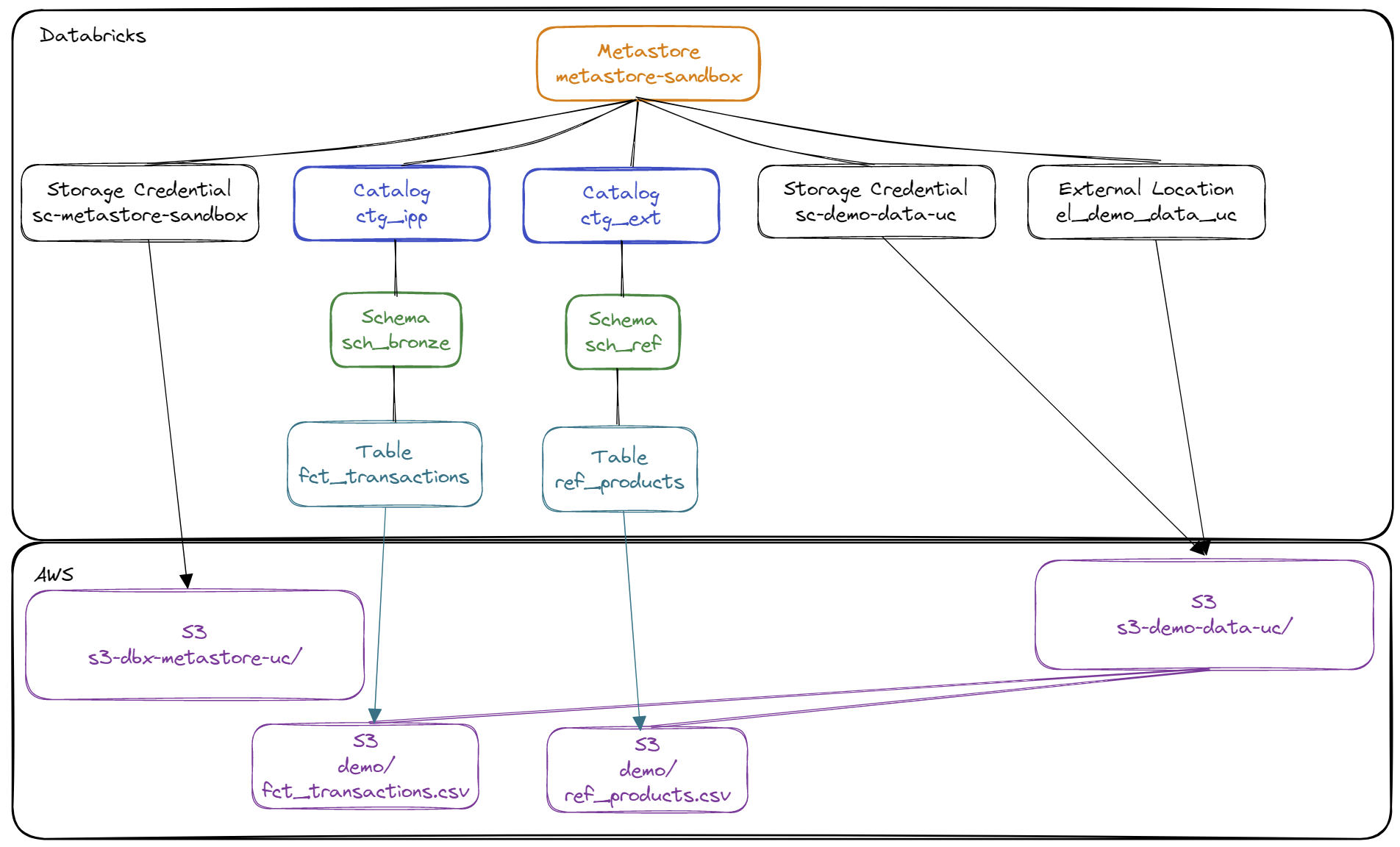
Pré-requis :
- Existence d’un Metastore nommé
metastore-sandboxavec le Storage Credential nommésc-metastore-sandboxpermettant de stocker les données par défaut dans la ressource AWS S3 nommés3-dbx-metastore-uc - Création d’une ressource AWS S3 nommée
s3-demo-data-uc - Création d’un rôle AWS IAM nommé
role-databricks-demo-data-ucet d’une politique AWS IAM nomméepolicy-databricks-demo-data-ucpermettant au rôle global Databricks de gérer l’accès à la ressource AWS S3s3-demo-data-uc - Création d’un Storage Credential nommé
sc-demo-data-ucpermettant au rôle global Databricks de gérer l’accès à la ressource AWS S3s3-demo-data-uc
Synthèse des actions qui seront réalisées :
- Création d’un External Storage pour pouvoir accéder avec Unity Catalog aux données de la ressource AWS S3 nommée
s3-demo-data-uc - Création du catalogue
ctg_ippqui contiendra l’ensemble des éléments managés (stockés sur la ressource AWS S3 nommées3-dbx-metastore-ucassociée au Metastoremetastore-sandbox) - Création du catalogue
ctg_extqui contiendra l’ensemble des éléments externes (stockés sur la ressource AWS S3 nommées3-demo-data-uc) - Création du schéma
ctg_ipp.sch_bronzequi permettra de créer les objets managés par Unity Catalog pour accéder aux données stockées sur la ressource AWS S3 nommées3-dbx-metastore-uc(au format Delta uniquement) - Création du schéma
ctg_ext.sch_refqui permettra de créer les objets pour accéder aux données stockées sur la ressource AWS S3 nommées3-demo-data-uc(sous forme de fichier CSV ou de fichier Delta)
Mise en place
Mise en place d’un jeu de données sur la ressource AWS S3
Contenu du fichier ref_products.csv:
1id,lib,brand,os,last_maj
21,Pixel 7 Pro,Google,Android,2023-01-01 09:00:00
32,Iphone 14,Apple,IOS,2023-01-01 09:00:00
43,Galaxy S23,Samsung,Android,2023-01-01 09:00:00
Contenu du fichier fct_transactions.csv :
1id_trx,ts_trx,id_product,id_shop,id_client,quantity
21,2023-04-01 09:00:00,1,2,1,1
32,2023-04-01 11:00:00,1,1,1,3
43,2023-04-03 14:00:00,1,2,1,1
54,2023-04-05 08:00:00,3,1,2,9
65,2023-04-06 10:00:00,1,2,1,3
76,2023-04-06 12:00:00,2,2,1,1
87,2023-04-10 18:30:00,2,1,2,11
98,2023-04-10 18:30:00,3,1,2,2
Réalisation de la copie des données vers le répertoire demode la ressource AWS S3 nommée s3-demo-data-uc avec l’outil AWS CLI:
1aws s3 cp ref_products.csv s3://s3-demo-data-uc/demo/ref_products.csv
2aws s3 cp fct_transactions.csv s3://s3-demo-data-uc/demo/fct_transactions.csv
Mise en place des contenants sur le Metastore Unity Catalog
Les étapes sont les suivantes : Note : Utilisation d’un utilisateur avec les droits d’administration sur le Metastore
- Création d’un External Location pour permettre aux utilisateurs de stocker des données dans la ressource AWS S3 nommée
s3-demo-data-uc - Création des catalogues
ctg_ippetctg_ext - Création des schémas
ctg_ipp.sch_bronzeetctg_ext.sch_ref
1-- 1. Create external location to access data from s3-demo-data-uc resource
2CREATE EXTERNAL LOCATION IF NOT EXISTS el_demo_data_uc
3URL 's3://s3-demo-data-uc'
4WITH (STORAGE CREDENTIAL `sc-demo-data-uc`)
5COMMENT 'External Location to access demo data';
6
7-- 2. Create Catalog ctg_ipp
8CREATE CATALOG IF NOT EXISTS ctg_ipp
9 COMMENT 'Catalog for managed data';
10
11-- 2. Create Catalog ctg_ext (for external data)
12CREATE CATALOG IF NOT EXISTS ctg_ext
13 COMMENT 'Catalog for external data'
14;
15
16-- 3. Create Schema sch_bronze in the Catalog ctg_ipp to store managed data
17CREATE SCHEMA IF NOT EXISTS ctg_ipp.sch_bronze
18 COMMENT 'Schema for Bronze Data'
19;
20
21-- 3. Create Schema sch_ref in the Catalog ctg_ext to store external data
22CREATE SCHEMA IF NOT EXISTS ctg_ext.sch_ref
23 COMMENT 'Schema for External Data'
24;
Gestion des groupes
Synthèse
Un groupe est un objet permettant de gérer les droits d’accès et de regrouper des utilisateurs ou d’autres groupes. Cela permet de mettre en place une organisation des accès par rapport à des équipes ou des profils plutôt qu’en passant directement par des utilisateurs.
Il existe deux types de groupes :
- Un groupe au niveau Account Databricks permet de gérer les accès aux données en utilisant la solution Unity Catalog (centralisation)
- Un groupe local au niveau Workspace Databricks permet de gérer les accès au niveau du workspace uniquement et n’est pas compatible avec Unity Catalog (cela est principalement utilisé avec Hive Metastore et pour les droits liés au Workspace Databricks)
Quota : On peut avoir jusqu’à une combinaison de 10 000 utilisateurs et 5 000 groupes dans un Account Databricks
Lorsqu’un Metastore Unity Catalog est rattaché à un Workspace Databricks, il n’est plus possible de créer un groupe local directement à partir de l’interface du Workspace Databricks.
Dans le cadre de la gestion des accès avec Unity Catalog, les recommandations sont les suivantes :
- Gérer l’ensemble des droits en s’appuyant sur les groupes définis au niveau de l’Account Databricks
- La création d’un groupe doit se faire au niveau de l’Account Databricks pour être ajouté au niveau d’un Workspace Databricks
- L’ajout et la suppression d’un membre (utilisateur ou groupe) d’un groupe doit se faire au niveau de l’Account Databricks
- La création d’un utilisateur peut se faire au niveau du Workspace Databricks. Il sera automatiquement ajouté au niveau de l’Account Databricks (Attention : il est fortement recommandé de gérer les utilisateurs et groupes en se basant sur un IdP (Identity provider) (Azure Active Directory, AWS IAM, …) pour avoir une gestion centralisée et sécurisée des comptes Databricks)
- La gestion des accès aux données se fait au niveau du Workspace Databricks (par l’administrateur du Workspace Databricks ou le propriétaire des objets)
- Il est recommandé de toujours appliquer des droits au niveau des groupes et non pas des utilisateurs pour faciliter la gestion des droits dans le temps
- Vous pouvez gérer des groupes sur plusieurs niveaux pour organiser les droits et les utilisateurs
- Lors de l’import (création) d’un groupe au niveau du Workspace Databricks, l’administrateur du Workspace doit définir les droits (Entitlements) du groupe sur le Workspace Databricks
- Si vous voulez donner les même droits que l’utilisateur
john.do.dbx@gmail.comà un autre utilisateur, il suffira d’ajouter cet autre utilisateur dans les mêmes groupes que l’utilisateurjohn.do.dbx@gmail.com
Concernant la suppression d’un groupe :
- Si vous supprimez le groupe du Workspace Databricks, il existera toujours au niveau de l’Account Databricks
- Si vous supprimez le groupe de l’Account Databricks, il sera automatiquement supprimé de l’ensemble des Workspace Databricks
Mise en pratique
Pré-requis :
- Avoir un compte ayant le rôle/droit d’administration de l’Account Databricks
- Avoir un compte ayant le rôle/droit d’administration du Workspace Databricks
- Avoir un SQL Warehouse existant sur le Workspace Databricks (pour que les utilisateurs puissent exécuter des requêtes SQL sur Databricks)
Pour la création du groupe et de l’utilisateur, il faut réaler les actions suivantes au niveau de l’Account Databricks :
- Création d’un utilisateur nommé
john.do.dbx@gmail.com - Création d’un groupe nommé
grp_demoet ajout de l’utilisateurjohn.do.dbx@gmail.comdans le groupegrp_demo
Pour que l’utilisateur puisse accéder aux ressources du Workspace Databricks, il faut réaliser les actions suivantes au niveau du Workspace Databricks :
3. Import du groupe grp_demo dans le Workspace Databricks
4. Ajout des droits au niveau du Workspace Databricks sur le groupe
Détail des actions à réaliser :
- Etape n°1
- Allez dans
Account Administration page > User Management > Users - Cliquez sur
Add User - Renseignez les informations
Email,First nameetLast nameet cliquez surSend invite
- Allez dans
- Etape n°2
- Allez dans
Account Administration page > User Management > Groups - Cliquez sur
Add Group - Renseignez les informations
Group nameet cliquez sursave - Cliquez sur
Add memberspour ajouter l’utilisateurjohn.do.dbx@gmail.com
- Allez dans
- Etape n°3
- Allez dans
Workspace page > username > Admin Settings > Groups - Cliquez sur
Add Group - Choisissez le groupe (parmi la liste des groupes qui existent au niveau de l’Account Databricks) et cliquez sur
Add
- Allez dans
- Etape n°4 :
- Allez sur
Workspace page > username > Admin Settings > Groups - Cliquez sur le groupe
- Cliquez sur
Entitlements- Cochez l’option
Workspace accesspour donner l’accès au Workspace Databricks à l’ensemble des utilisateurs du groupe - Cochez l’option
Databricks SQL accesspour donner l’accès aux ressources SQL du Workspace Databricks à l’ensemble des utilisateurs du groupe
- Cochez l’option
- Allez sur
Si vous voulez donner l’accès à un SQL Warehouse à un groupe, il faut suivre les étapes suivantes :
- Allez sur
Workspace page > SQL > SQL Warehouses - Cliquez sur le bouton sous forme de 3 points and choisissez l’option
Permissions - Ajoutez le groupe et choisissez l’option
Can use
Note : Il est aussi possible d’ajouter le groupe au niveau du Workspace Databricks avec l’outil Databricks CLI
1# Add a group in the Workspace Databricks (the group must exist at the Account Databricks level)
2databricks groups create --group-name "grp_demo"
Gestion des droits
Synthèse
La gestion des droits se fait en s’appuyant sur la syntaxe SQL ANSI et plus spécifiquement avec les instructions GRANT et REVOKE.
Vous trouverez une liste exhaustive des droits pouvant être gérer avec Unity Catalog sur la documentation officielle
Pour donner un droit à un groupe ou un utilisateur, la syntaxe est la suivante :
1GRANT <Rights with comma separator> ON <Type Object> <Name Object> TO <Group or User>;
Pour supprimer un droit à un groupe ou un utilisateur, la syntaxe est la suivante :
1REVOKE <Rights with comma separator> ON <Type Object> <Name Object> FROM <Group or User>;
Point d’attention : Il est indispensable d’avoir le droit de USE/USAGE sur le catalogue et le schéma pour accéder à une table même si on a déjà le droit de SELECT dessus sinon l’utilisateur (ou le groupe) n’aura pas la possible de voir le contenu du catalogue et du schéma par défaut.
Par exemple : Si le propriétaire de la table ctg_ext.sch_ref.tbl_demo donne le droit de SELECTau groupe grp_demo alors les utilisateurs du groupe grp_demone pourront pas lire les données de la table tbl_demo tant qu’ils n’auront pas le droit USE sur le catalogue ctg_ext et sur le schéma sch_ref.
Il est possible de gérer les droits au niveau de chaque objet (table/vue) mais il est recommandé d’organiser les données et les droits au niveau des schémas lorsque l’organisation le permet pour faciliter la gestion des droits d’accès aux données aux différentes équipes et profils de l’organisation.
Mise en pratique
Nous avons déjà créé les catalogues et les schémas avec un compte d’administration et nous voulons donner la possibilité à l’utilisateur john.do.dbx@gmail.com de gérer les objets dans les différents catalogues et schémas.
Par défaut, le groupe grp_demo n’a aucun droit sur les catalogue du Metastore (et ne peut pas les visualiser).
Nous allons faire les actions nécessaires pour nous assurer que les droits seront suffisants pour pouvoir faire les manipulations suivantes :
- Création des nouveaux schémas dans le atalogue
ctg_ipp - Création des tables dans l’ensemble des schémas des catalogues
ctg_ippetctg_ext
Les actions à réaliser sont les suivantes :
- Donner les droits de visualisation sur les catalogues
1-- Right to view the Catalog ctg_ipp
2GRANT USAGE ON CATALOG ctg_ipp TO grp_demo;
3-- Right to view the Catalog ctg_ext
4GRANT USAGE ON CATALOG ctg_ext TO grp_demo;
- Donner les droits de création de schéma au niveau du catalogue
ctg_ipp
1-- Right to create new Schema in Catalog ctg_ipp
2GRANT USE SCHEMA, CREATE SCHEMA ON CATALOG ctg_ipp TO grp_demo;
- Donner les droits d’accès et de création des objets dans le schéma
ctg_ext.sch_refainsi que les droits d’accès pour créer des tables externes (External Table) en se basant sur le stockage défini dans l’objet External Location nomméel_demo_data_uc:
1-- Rights to create objects in the Schema ctg_ext.sch_ref
2GRANT USE SCHEMA, SELECT , MODIFY, CREATE TABLE ON SCHEMA ctg_ext.sch_ref TO grp_demo;
3-- Right to create External tables with the External Location
4GRANT CREATE EXTERNAL TABLE ON EXTERNAL LOCATION `el_demo_data_uc` TO grp_demo;
- Donner tous les droits sur le schéma
ctg_ipp.sch_bronze
1-- All privileges on the Schema ctg_ipp.sch_bronze
2GRANT ALL PRIVILEGES ON SCHEMA ctg_ipp.sch_bronze TO grp_demo;
Si on souhaite qu’un utilisateur puisse créer lui même l’objet External Location pour mettre en place les accès vers une nouvelle ressource AWS S3, il faut lui donner les droits suivants :
1-- Right on the Metastore for the group
2GRANT CREATE EXTERNAL LOCATION ON METASTORE TO grp_demo;
3-- Right on the Storage Credential to the group
4GRANT CREATE EXTERNAL LOCATION ON STORAGE CREDENTIAL `sc-demo-data-uc` TO grp_demo;
Exemple de requête permettant de récupérer l’ensemble des droits données au groupe grp_demo sur les objets des catalogues ctg_ippet ctg_ext :
1-- How to get all the existing privileges for a group ?
2-- Get privileges from Catalog
3select 'GRANT '||replace(privilege_type,'_',' ')||' ON CATALOG '||catalog_name||' TO '||grantee||';' as grant_query
4from system.INFORMATION_SCHEMA.CATALOG_PRIVILEGES
5where grantee='grp_demo'
6 and grantor <> 'System user'
7 and catalog_name in ('ctg_ipp','ctg_ext')
8 and inherited_from = 'NONE'
9order by catalog_name,privilege_type
10;
11
12-- Get privileges from Schema
13select 'GRANT '||replace(privilege_type,'_',' ')||' ON SCHEMA '||catalog_name||'.'||schema_name||' TO '||grantee||';' as grant_query
14from system.INFORMATION_SCHEMA.SCHEMA_PRIVILEGES
15where grantee='grp_demo'
16 and grantor <> 'System user'
17 and catalog_name in ('ctg_ipp','ctg_ext')
18 and inherited_from = 'NONE'
19order by catalog_name, schema_name,privilege_type;
20
21-- Get privileges from Table
22select 'GRANT '||replace(privilege_type,'_',' ')||' ON TABLE '||table_catalog||'.'||table_schema||'.'||table_name||' TO '||grantee||';' as grant_query
23from system.INFORMATION_SCHEMA.TABLE_PRIVILEGES
24where grantee = 'grp_demo'
25 and grantor <> 'System user'
26 and table_catalog in ('ctg_ipp','ctg_ext')
27 and inherited_from = 'NONE'
28order by table_catalog,table_schema,table_name,privilege_type;
Gestion du stockage
Synthèse
L’objet Table permet de définir la structure et le stockage des données.
La création des tables et des vues se font obligatoirement dans un schéma.
Par défaut, si l’on ne précise rien lors de la création des catalogues et des schémas, l’ensemble des données seront gérées par Unity Catalog en se basant sur le stockage (ressource AWS S3) défini au niveau du Metastore.
Si l’option MANAGED LOCATION est définie au niveau du catalogue alors l’ensemble des éléments (schéma et table) utilisera cette option de stockage par défaut au lieu du stockage défini au niveau du Metastore.
Si l’option MANAGED LOCATION est définie au niveau du schéma alors l’ensemble des éléments (table) utilisera cette option de stockage par défaut au lieu du stockage défini au niveau du Metastore.
Exemple de syntaxe :
1-- Catalog creation
2CREATE CATALOG XXX
3 MANAGED LOCATION 's3://YYYYYYYYY'
4 COMMENT 'ZZZZZZZZ'
5;
6
7-- Schema creation
8CREATE SCHEMA XXX
9 MANAGED LOCATION 's3://YYYYYYYYY'
10 COMMENT 'ZZZZZZZZ'
11;
Le schéma et le catalogue ne sont que des enveloppes logiques pour organiser les données. Il n’y a pas de création de répertoire lors de la création de ces objets.
Il existe deux types de tables :
- Managed Table (table managée) : Les métadonnées et les données sont gérées par Unity Catalog et le format de stockage utilisé est le format Delta.
- External Table (table externe) : Uniquement les métadonnées sont gérées par Unity Catalog. Le format de stockage peut être l’un des formats suivants “Delta, CSV, JSON, Avro, Parquet, ORC ou Texte”
Concernant les tables managées (Managed Table) :
- Lorsque l’on crée une Managed Table, les données sont créées dans un sous répertoire du stockage défini au niveau du Metastore (dans le cas ou l’option “MANAGED LOCATION” n’est pas défini au niveau du catalogue ou du schéma parent)
- Le chemin sera la suivante
<Metastore S3 Path>/<Metastore ID>/tables/<table ID>,- Exemple :
s3://s3-dbx-metastore-uc/metastore-sandbox/13a746fa-c056-4b32-b6db-9d31c0d1eecf/tables/5c725019-fe8f-4778-a97c-c640eaf9b13e- Metastore S3 Path :
s3-dbx-metastore-uc - Metastore ID :
13a746fa-c056-4b32-b6db-9d31c0d1eecf - Table ID :
5c725019-fe8f-4778-a97c-c640eaf9b13e
- Metastore S3 Path :
- Du point de vue du stockage, l’ensemble des données des Managed Table au niveau du Metastore sera stocké par défaut dans le sous-répertoire
tables/avec un identifiant unique défini lors de leur création.
- Exemple :
- Lors de la suppression de la table, les métadonnées ainsi que les données (fichiers) seront supprimées
Concernant les tables externes (External Table) :
- Lorsque l’on crée une External Table, on doit indiquer le chemin complet d’accès aux données (Unity Catalog gère les droits en se basant sur un objet Storace Credential et un objet External Location)
- Si des fichiers existent déjà, alors il faut que la définition de la table (format de données sources, schéma, etc …) soit compatible avec la donnée existante
- Si aucun fichier n’existe, alors les éléments de log du format Delta seront créés dans le sous répertoire
_log_deltadu chemin défini et les fichiers de données seront créés lors de l’ajout de données dans la table.
- Lors de la suppression de la table, uniquement les métadonnées sont supprimées. Les données (fichiers) ne sont pas impactées par la suppression.
- Quelques restrictions :
- Si la table se source à partir d’un fichier csv, aucune autre action que la lecture ne sera permise
- Si la table se source à partir des données (fichiers) de type CSV (ou autres format hors Delta) (écrit par un traitement spark par exemple), il sera possible de faire des insertions mais pas de mise à jour ou de suppression
- Si la table se source à partir des données au format Delta alors il sera possible de faire exactement les mêmes actions qu’avec une Managed Table
- Il n’est pas possible de définir deux tables externes différentes utilisant exactement les mêmes fichiers de données comme stockage externe
Mise en pratique
Création d’une External Table et d’une Managed Table :
- Création d’une table externe (External Table) nommée
ref_productsdans le schémasch_refdu cataloguectg_extà partir d’un fichier csv nomméref_products.csv - Création d’une talbe managée (Managed Table) nommée
fct_transactionsdans le schémasch_bronzedu cataloguectg_ipp - Insertion des données dans la table
fct_transactionsà partir d’un fichier CSV nomméfct_transactions.csv
1-- 1. Creation of external table ref_products
2CREATE TABLE ctg_ext.sch_ref.ref_products (
3 id int
4 ,lib string
5 ,brand string
6 ,os string
7 ,last_maj timestamp
8)
9USING CSV
10OPTIONS (path "s3://s3-demo-data-uc/demo/ref_products.csv",
11 delimiter ",",
12 header "true")
13COMMENT 'Product referential (external)'
14;
15
16
17-- 2. Creation of managed table fct_transactions
18CREATE TABLE ctg_ipp.sch_bronze.fct_transactions (
19 id_trx string
20 ,ts_trx string
21 ,id_product string
22 ,id_shop string
23 ,id_client string
24 ,quantity string
25)
26COMMENT 'Bronze Transactions Data'
27;
28
29
30-- 3. Insert data from CSV files into the fct_transactions table
31COPY INTO ctg_ipp.sch_bronze.fct_transactions
32 FROM 's3://s3-demo-data-uc/demo/fct_transactions.csv'
33 FILEFORMAT = CSV
34 FORMAT_OPTIONS ('encoding' = 'utf8'
35 ,'inferSchema' = 'false'
36 ,'nullValue' = 'N/A'
37 ,'mergeSchema' = 'false'
38 ,'delimiter' = ','
39 ,'header' = 'true'
40 ,'mode' = 'failfast')
41;
Exemple d’erreur lors de la mise à jour des données d’une External Table basée sur un fichier CSV
4. Mise à jour des données de la table ref_products en erreur
5. Suppression d’une données de la table ref_products en erreur
1-- 4. Error : Try to update the data in the ref_products table
2UPDATE ctg_ext.sch_ref.ref_products
3SET last_maj = current_timestamp()
4WHERE id = 1;
5-- Result : UPDATE destination only supports Delta sources
6
7
8-- 5. Error : Try to delete the data from ref_products table
9DELETE FROM ctg_ext.sch_ref.ref_products
10WHERE id = 1;
11-- Result : Could not verify permissions for DeleteFromTable
Exemple de la gestion du stockage des données pour une External Table (au format Delta) lors de sa création et de sa suppression :
6. Création d’une table externe avec la propriété appendOnly
7. Vérification de l’existence des fichiers sur la ressource AWS S3
8. Insertion d’une donnée en passant par le Metastore Unity Catalog
9. Vérification de la liste des fichiers sur la ressource AWS S3
10. Visualisation de l’historique des données Delta
11. Suppression des données sans utiliser la table du Metastore Unity Catalog (la propriété appendOnly bloque la réalisation de cette action)
12. Suppression de la table externe
13. Vérification de l’existence des fichiers avec S3
1
2-- 6. Create an external table named "ext_tbl" in schema "ctg_ext.sch_ref" in the location "s3://s3-demo-data-uc/demo/ext_tbl" with the delta properties "appendOnly"
3CREATE TABLE ctg_ext.sch_ref.ext_tbl (
4 col1 int
5 ,col2 timestamp
6)
7COMMENT 'Test External Table with TBLProperties'
8LOCATION 's3://s3-demo-data-uc/demo/ext_tbl'
9TBLPROPERTIES('delta.appendOnly' = 'true')
10;
11
12
13-- 7. Check if the file exists on AWS S3 (with AWS CLI)
14-- aws s3 ls s3://s3-demo-data-uc/demo/ --recursive | grep "ext_tbl" | sed 's/[[:space:]][[:space:]]*/|/g' | cut -d "|" -f 4
15/* Result :
16demo/ext_tbl/_delta_log/
17demo/ext_tbl/_delta_log/.s3-optimization-0
18demo/ext_tbl/_delta_log/.s3-optimization-1
19demo/ext_tbl/_delta_log/.s3-optimization-2
20demo/ext_tbl/_delta_log/00000000000000000000.crc
21demo/ext_tbl/_delta_log/00000000000000000000.json
22*/
23
24
25-- 8. Insert Data into the "ext_tbl" table
26INSERT INTO ctg_ext.sch_ref.ext_tbl VALUES (1,current_timestamp());
27
28-- 9. Check if the file exists on AWS S3 (with AWS CLI)
29-- aws s3 ls s3://s3-demo-data-uc/demo/ --recursive | grep "ext_tbl" | sed 's/[[:space:]][[:space:]]*/|/g' | cut -d "|" -f 4
30/* Result :
31demo/ext_tbl/_delta_log/
32demo/ext_tbl/_delta_log/.s3-optimization-0
33demo/ext_tbl/_delta_log/.s3-optimization-1
34demo/ext_tbl/_delta_log/.s3-optimization-2
35demo/ext_tbl/_delta_log/00000000000000000000.crc
36demo/ext_tbl/_delta_log/00000000000000000000.json
37demo/ext_tbl/_delta_log/00000000000000000001.crc
38demo/ext_tbl/_delta_log/00000000000000000001.json
39demo/ext_tbl/part-00000-097fb1f5-1d7e-464a-a65b-1303bd06e2b0.c000.snappy.parquet
40*/
41
42-- 10. Check Delta History
43DESCRIBE HISTORY ctg_ext.sch_ref.ext_tbl;
44/* Result :
45Version 1 : WRITE
46Version 0 : CREATE TABLE
47*/
48
49-- 11. Delete data without using the Unity Catalog Table
50DELETE FROM DELTA.`s3://s3-demo-data-uc/demo/ext_tbl` WHERE col1 = 1;
51/* Result : This table is configured to only allow appends.*/
52
53
54-- 12. Delete the table "ext_tbl"
55DROP TABLE ctg_ext.sch_ref.ext_tbl;
56
57-- 13. Check if the file exists on AWS S3 (with AWS CLI)
58-- aws s3 ls s3://s3-demo-data-uc/demo/ --recursive | grep "ext_tbl" | sed 's/[[:space:]][[:space:]]*/|/g' | cut -d "|" -f 4
59/* Result :
60demo/ext_tbl/_delta_log/
61demo/ext_tbl/_delta_log/.s3-optimization-0
62demo/ext_tbl/_delta_log/.s3-optimization-1
63demo/ext_tbl/_delta_log/.s3-optimization-2
64demo/ext_tbl/_delta_log/00000000000000000000.crc
65demo/ext_tbl/_delta_log/00000000000000000000.json
66demo/ext_tbl/_delta_log/00000000000000000001.crc
67demo/ext_tbl/_delta_log/00000000000000000001.json
68demo/ext_tbl/part-00000-097fb1f5-1d7e-464a-a65b-1303bd06e2b0.c000.snappy.parquet
69*/
Remarques :
- Lors de la création de la table, uniquement le sous-répertoire
_delta_logest créé pour contenir les informations de la version n°0 - Lorsque l’on positionne une propriété avec l’option “TBLPROPERTIES” sur la table externe, elle est aussi enregistrée sur le stockage.
- Après la suppression de la table, les données ne sont plus accessibles en passant par la table mais sont toujours accessibles en passant par le chemin sur la ressource AWS S3
Concernant les propriétés pouvant être utilisées avec le format Delta : Vous pourrez trouver plus d’information dans la documentation officielle
Suppression des éléments
Vous trouverez ci-dessous l’ensemble des instructions nécessaires pour nettoyer l’environnement.
Suppression des éléments de Unity Catalog en utilisant les instructions SQL :
1-- Delete the Catalog with CASCADE option (to delete all objects)
2DROP CATALOG IF EXISTS ctg_ipp CASCADE;
3DROP CATALOG IF EXISTS ctg_ext CASCADE;
4
5-- Delete the External Location
6DROP EXTERNAL LOCATION IF EXISTS el_demo_data_uc force;
Note concernant la suppression de l’objet External Location :
- Il faut obligatoirement en être le propriétaire
- Il ne faut pas qu’il soit déjà utilisé par une table, sinon il faut utiliser l’option
force
Suppression des données utilisées sur la ressource AWS S3 :
1# Delete all files stored in the AWS S3 resource
2aws s3 rm "s3://s3-demo-data-uc/demo/" --recursive
Suppression du groupe à partir de l’Account Databricks (cela supprimera automatiquement le groupe au niveau du Workspace Databricks) :
- Allez sur
Account Databricks page > User management > Groups - Utilisez la barre de recherche pour trouver le groupe voulu
- Cliquez sur le bouton avec les 3 points associés au groupe et sélectionnez l’option
Delete - Cliquez sur
Confirm Delete
Suppression de l’utilisateur au niveau de l’Account Databricks :
- Allez sur
Account Databricks page > User management > Users - Utilisez la barre de recherche pour trouver l’utilisateur voulu
- Cliquez sur le nom de l’utilisateur
- Cliquez sur le bouton avec les 3 points et sélectionnez l’option
Delete user - Cliquez sur
Confirm Delete
Conclusion
Nous avons pu voir un premier aperçu de quelques fonctionnalités de la solution Unity Catalog, concernant principalement la gestion des droits et du stockage avec External Table (tables externes) et Managed Table (tables managées).
La gestion des droits est simplifiée par l’usage de la syntaxe SQL ANSI, l’utilisation des groupes d’utilisateurs et la centralisation de la gestion des accès au sein d’Unity Catalog.
La gestion des groupes nécessite d’être Administrateur sur l’Account Databricks (création et suppression des groupes, ajout et suppression des utilisateurs dans les groupes) et Administrateur sur le Workspace Databricks pour ajouter ou supprimer des groupes existant au niveau de l’Account Databricks dans le Workspace Databricks.
Point d’attention : La gestion des droits et des groupes n’est pas compatible entre Unity Catalog et Hive Metastore, il est recommandé de migrer les éléments de Hive Metastore vers Unity Catalog en recréant les accès/éléments nécessaires.
Si l’on souhaite mettre en place un fonctionnement ouvert des données en minimisant l’utilisation de Databricks, il est possible d’utiliser Unity Catalog avec des tables externes au format Delta pour pouvoir utiliser le maximum de fonctionnalité tout en utilisant d’autres outils pour accéder directement aux données Delta (AWS EMR, AWS Glue, AWS Athena, …).
Néanmoins, si l’on souhaite utiliser la solution Unity Catalog, il est fortement recommandé de centraliser l’ensemble de la gouvernance des données afin de pouvoir gérer l’ensemble des accès au sein de la solution Unity Catalog.
A partir de la solution Unity Catalog, il est possible d’accéder aux données en utilisant des Clusters, des SQL Warehouse ou la fonctionnalité de Delta Sharing pour multiplier les usages possibles des données.
Ressources
Creation d’un SQL Warehouse
Databricks CLI ne permet pas de gérer les SQL Warehouses pour le moment, par conséquent nous pouvons utiliser Databricks API REST pour le faire.
Pré-requis :
- Avoir l’outil
Curlinstallé
Réalisation des actions :
- Création d’un fichier
.netrcpermettant de gérer les accès à l’API REST :
1# Create the folder where the .netrc file will be stored
2mkdir ~/.databricks
3
4# Create the .netrc file
5echo "machine <url workspace databricks without https://>
6login token
7password <token user databricks>
8" > ~/.databricks/.netrc
9
10# Create an alias to use the tool curl with .netrc file
11echo "alias dbx-api='curl --netrc-file ~/.databricks/.netrc'" >> ~/.alias
- Création d’un warehouse
1
2export DBX_API_URL="<url workspace databricks>"
3
4# Get the list of the existing SQL Warehouses (check if the SQL Warehouse exists)
5dbx-api -X GET ${DBX_API_URL}/api/2.0/sql/warehouses/ | jq .
6
7# Create the temporary config file for the SQL Warehouse
8cat > tmp_databricks_create_warehouse.json <<EOF
9{
10 "name": "DEMO_WH_XXS",
11 "cluster_size": "2X-Small",
12 "min_num_clusters": 1,
13 "max_num_clusters": 1,
14 "auto_stop_mins": 20,
15 "auto_resume": true,
16 "tags": {
17 "custom_tags": [
18 {
19 "key": "owner",
20 "value": "admin@tech.demo"
21 },
22 {
23 "key": "project",
24 "value": "databricks-demo"
25 }
26 ]
27 },
28 "spot_instance_policy":"COST_OPTIMIZED",
29 "enable_photon": "true",
30 "enable_serverless_compute": "false",
31 "warehouse_type": "CLASSIC",
32 "channel": {
33 "name": "CHANNEL_NAME_CURRENT"
34 }
35}
36EOF
37
38
39# Creation of the SQL Warehouse
40dbx-api -X POST -H "Content-Type: application/json" -d "@tmp_databricks_create_warehouse.json" ${DBX_API_URL}/api/2.0/sql/warehouses/
41
42# Delete the temporary config file
43rm tmp_databricks_create_warehouse.json
Quelques actions pouvant être utiles :
1# Export the SQL Warehouse ID
2export SQL_WH_ID="<SQL Warehouse ID>"
3
4# Check the state of the SQL Warehouse
5dbx-api -X GET ${DBX_API_URL}/api/2.0/sql/warehouses/${SQL_WH_ID} | jq '.state'
6
7# Stop the SQL Warehouse (by default, it starts at creation)
8dbx-api -X POST ${DBX_API_URL}/api/2.0/sql/warehouses/${SQL_WH_ID}/stop
9
10# Start the SQL Warehouse
11dbx-api -X POST ${DBX_API_URL}/api/2.0/sql/warehouses/${SQL_WH_ID}/start
12
13# Delete the SQL Warehouse
14dbx-api -X DELETE ${DBX_API_URL}/api/2.0/sql/warehouses/${SQL_WH_ID}