
Databricks : Unity Catalog - Découverte - Partie 3 - Data Lineage
Nous allons découvrir la fonctionnalité Data Lineage proposée par la solution Unity Catalog.
Nous allons utiliser un Account Databricks sur AWS pour réaliser cette découverte.
Note : Nous allons garder des termes techniques en anglais pour faciliter la compréhension
Note : Les travaux se basent sur l’état de la solution Unity Catalog à la fin du 1er trimestre 2023 sur AWS et Azure.
Qu’est ce qu’est le Data Lineage
Le Data Lineage consiste à cartographier l’ensemble des objets et leur utilisation afin de pouvoir visualiser le cycle de vie des données.
Lorsque l’on souhaite mettre en place une gouvernance de données, le Data Lineage apporte des informations extrêmement utiles.
Un Lineage fonctionnel consiste à mettre en place les éléments et outils pour cartographier les objets fonctionnels et leur usage dans les différentes applications et projets de l’entreprise afin de visualiser l’usage des données dans l’ensemble de l’organisation (équipes, applications, projets) Cela permet de faciliter les travaux de rationalisation de l’usage global des données ainsi que la mise en place d’un langage fonctionnel commun à l’entreprise.
Un Lineage technique consiste à mettre en place les éléments et outils pour cartographier les objets techniques et l’utilisation des données par les différents outils techniques. Cela permet de visualiser la relation entre les différents objets et de pouvoir identifier rapidement la provenance des données d’un objet ainsi que les éléments impactés par les changements d’un objet.
Certain outils de gouvernance de données permettant d’automatiser la capture des métadonnées pour centraliser les informations de type Data Lineage comme par exemple Apache Atlas, Azure Purview ou AWS Glue (et bien d’autres)
Dans notre cas, nous allons nous appuyer sur la solution Unity Catalog proposée par Databricks et plus précisément sur la capture des informations mis en place par cette solution pour cartographier l’ensemble des éléments liés au Data Lineage.
Remarque : Il est aussi possible de mettre en place cette cartographie de manière manuelle avec l’utilisation d’un support de type Wiki alimenté manuellement ou à l’aide de scripts pour extraire les métadonnées des différents outils lorsque cela est possible. Cela nécessite énormément de temps et d’énergie pour rédiger, maintenir, extraire et valider les informations dans le temps (évolution des outils, évolution des applications, évolution des données, …)
Unity Catalog et la hiérarchie des objets
Synthèse
Unity Catalog est la solution de Databricks permettant d’avoir une gouvernance unifiée et centralisée pour l’ensemble des données gérées par les ressources Databricks ainsi que de sécuriser et faciliter la gestion et le partage des données à l’ensemble des acteurs internes et externes d’une organisation.
Vous pourrez avec une vue d’ensemble plus complète en parcourant la documentation officielle
Rappel concernant la hiérarchie des objets :

Les différents objets sont :
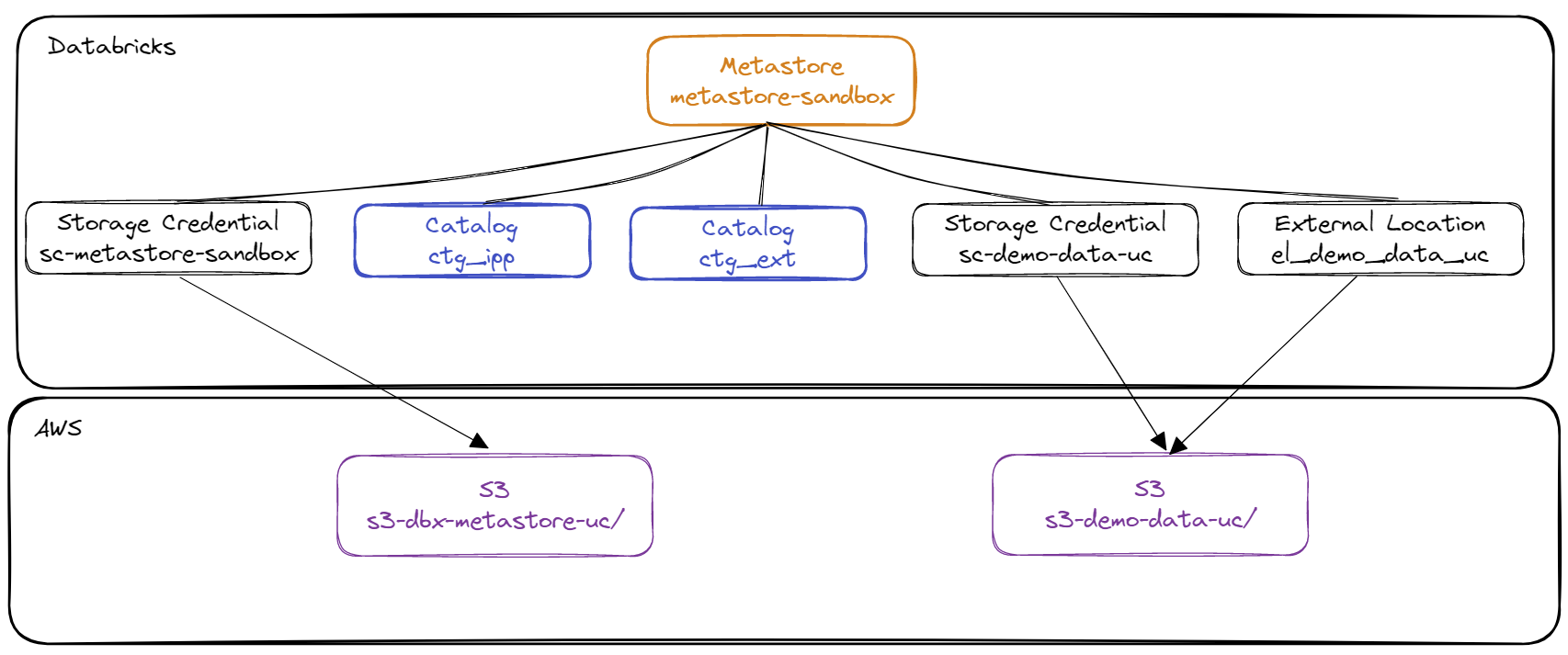
- Storage Credential : Cet objet est associé directement au Metastore et permet de stocker les accès à un cloud provider (par exemple AWS S3) permettant à la solution Unity Catalog de gérer les droits sur les données.
- External Location : Cet objet est associé au Metastore et permet de stocker le chemin vers un cloud provider (par exemple une ressource AWS S3) en combinaison avec un Storage Credential pour gérer les accès aux données
- Metastore : Objet du plus haut niveau pouvant contenir des métadonnées
- Catalog (Catalogue) : Objet de 1er niveau permettant d’organiser les données par schéma (aussi nommé Base de données)
- Schema (Schéma) : Objet de 2ème et dernier niveau permettant d’organiser les données (contient les tables, les vues et les fonctions)
- Table : Objet permettant de définir la structure et le stockage des données.
- View (Vue) : Objet permettant d’encapsuler une requête utilisant un ou plusieurs objets (table ou vue)
- Function (Fonction) : Objet permettant de définir des opérations sur les données
Lorsque vous souhaitez accéder à un objet (par exemple une table), il sera nécessaire de renseigner le nom du catalogue et le nom du schéma où est défini l’objet.
Exemple : select * from catalog.schema.table
Préparation de l’environnement
Nous allons mettre en place un ensemble d’éléments nous permettant de découvrir plus en détail la fonctionnalité de Data Lineage de la solution Unity Catalog.
Contexte
Pré-requis :
- Création du groupe
grp_demo - Création de l’utilisateur
john.do.dbx@gmail.comet ajout de l’utilisateur dans le groupegrp_demo - Création d’un SQL Warehouse et donner le droit d’utilisation au groupe
grp_demo - Existence d’un Metastore nommé
metastore-sandboxavec le Storage Credential nommésc-metastore-sandboxpermettant de stocker les données par défaut dans la ressource AWS S3 nommées3-dbx-metastore-uc - Création d’une ressource AWS S3 nommée
s3-demo-data-uc - Création d’un rôle AWS IAM nommé
role-databricks-demo-data-ucet d’une politique AWS IAM nomméepolicy-databricks-demo-data-ucpermettant au rôle global Databricks de gérer l’accès à la ressource AWS S3 nommées3-demo-data-uc - Création d’un Storage Credential nommé
sc-demo-data-ucet d’un External Location nomméel_demo_data_ucpermettant au rôle global Databricks de gérer l’accès à la ressource AWS S3 nommées3-demo-data-uc
Mise en place des droits pour le groupe grp_demo :
- Donner le droit de créer des catalogues au niveau du Metastore pour le groupe
grp_demo - Donner le droit de lire les fichiers externes à partir de l’objet External Location nommé
el_demo_data_uc
1-- 1. Give Create Catalog right on Metastore to grp_demo
2GRANT CREATE CATALOG ON METASTORE TO grp_demo;
3
4-- 2. Give Read Files right on el_demo_data_uc location to grp_demo
5GRANT READ FILES ON EXTERNAL LOCATION `el_demo_data_uc` TO grp_demo;
Schématisation de l’environnement
Schématisation des éléments de 1er niveau du Metastore correspondant au pré-requis :
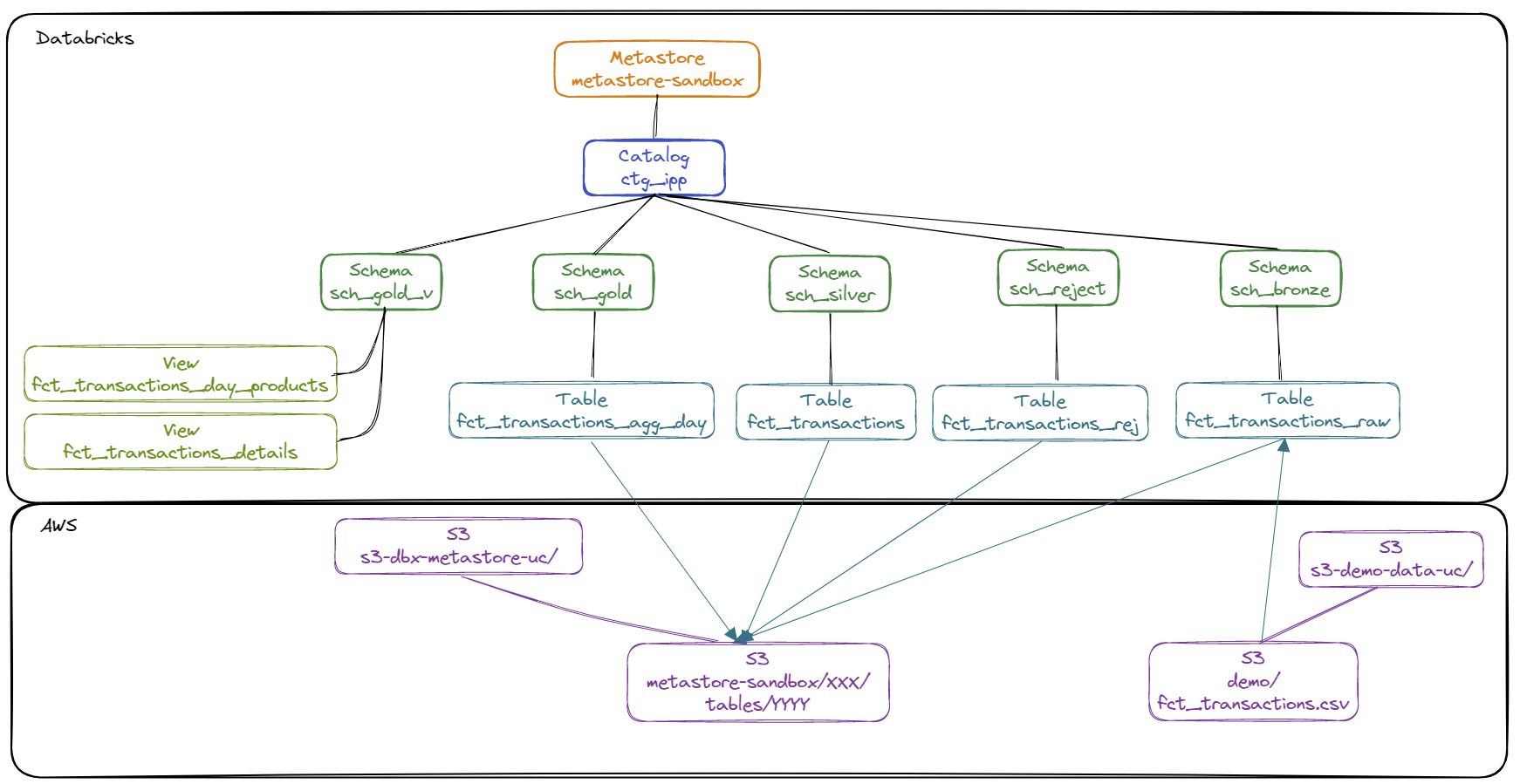
Schématisation du contenu du catalogue ctg_ipp :
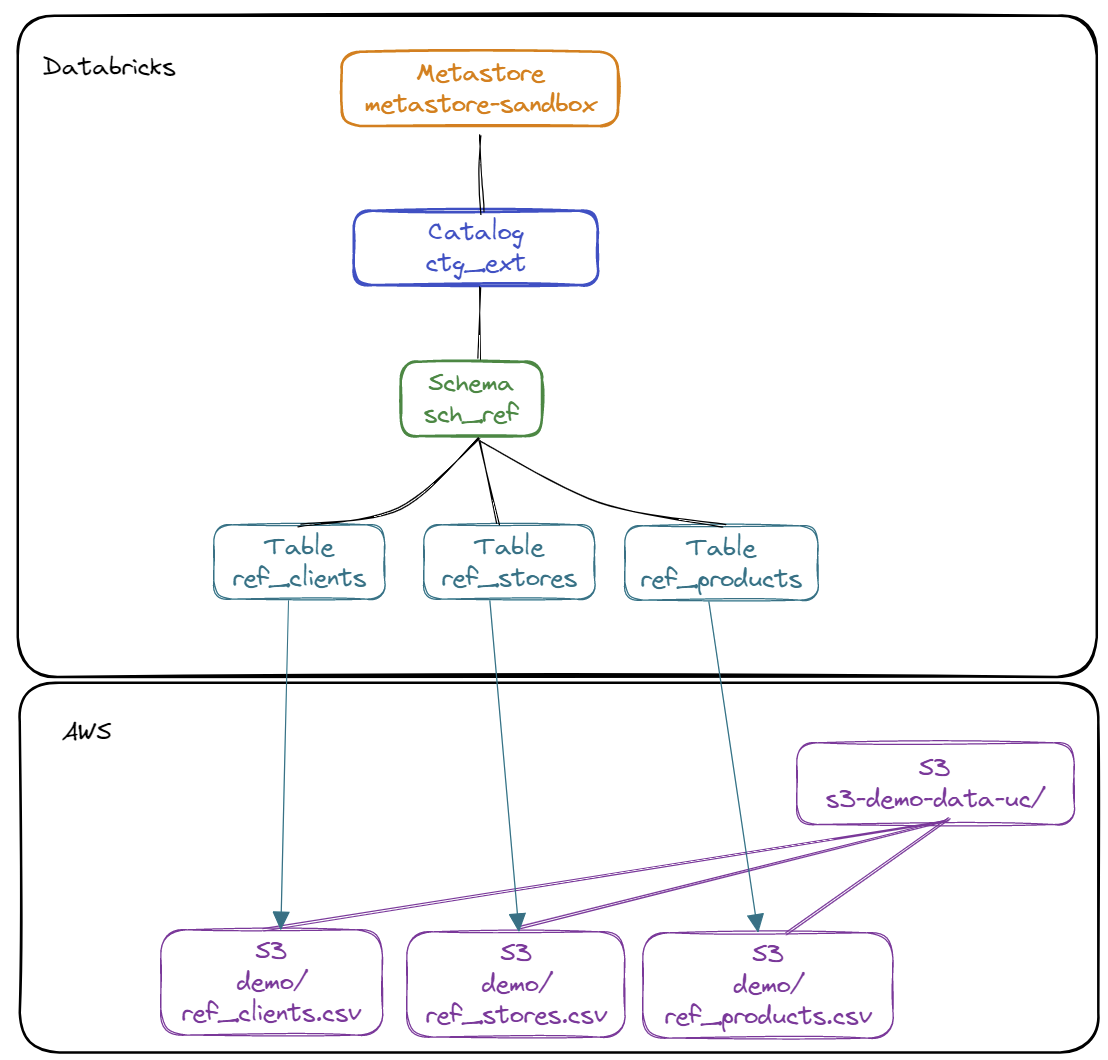
Schématisation du contenu du catalogue ctg_ext :
Schématisation de l’alimentation des données entre les différents objets :

Mise en place d’un jeu de données sur la ressource AWS S3
Contenu du fichier ref_stores.csv :
1id,lib,postal_code,surface,last_maj
21,BustaPhone One,75001,120,2022-01-01 00:00:00
32,BustaPhone Two,79002,70,2022-01-01 00:00:00
Contenu du fichier ref_clients.csv :
1id,lib,age,contact,phone,is_member,last_maj
21,Maxence,23,max1235@ter.tt,+33232301123,No,2023-01-01 11:01:02
32,Bruce,26,br_br@ter.tt,+33230033155,Yes,2023-01-01 13:01:00
43,Charline,40,ccccharline@ter.tt,+33891234192,Yes,2023-03-02 09:00:00
Contenu du fichier ref_products.csv :
1id,lib,brand,os,last_maj
21,Pixel 7 Pro,Google,Android,2023-01-01 09:00:00
32,Iphone 14,Apple,IOS,2023-01-01 09:00:00
43,Galaxy S23,Samsung,Android,2023-01-01 09:00:00
Contenu du fichier fct_transactions.csv :
1id_trx,ts_trx,id_product,id_shop,id_client,quantity
21,2023-04-01 09:00:00,1,2,1,1
32,2023-04-01 11:00:00,1,1,1,3
43,2023-04-03 14:00:00,1,2,1,1
54,2023-04-05 08:00:00,3,1,2,9
65,2023-04-06 10:00:00,1,2,1,3
76,2023-04-06 12:00:00,2,2,1,1
87,2023-04-10 18:30:00,2,1,2,11
98,2023-04-10 18:30:00,3,1,2,2
Réalisation de la copie des données vers le répertoire demode la ressource AWS S3 nommée s3-demo-data-uc avec l’outil AWS CLI:
1aws s3 cp ref_stores.csv s3://s3-demo-data-uc/demo/ref_stores.csv
2aws s3 cp ref_clients.csv s3://s3-demo-data-uc/demo/ref_clients.csv
3aws s3 cp ref_products.csv s3://s3-demo-data-uc/demo/ref_products.csv
4aws s3 cp fct_transactions.csv s3://s3-demo-data-uc/demo/fct_transactions.csv
Mise en place des objets dans le Metastore Unity Catalog
Note : Utilisation d’un utilisateur du groupe grp_demo
- Création des catalogues
ctg_ipp: Catalogue permettant de gérer les éléments managés par Unity Catalogctg_ext: Catalogue permettant de gérer les éléments externes
1-- Create Catalog (for managed data)
2CREATE CATALOG IF NOT EXISTS ctg_ipp
3 COMMENT 'Catalog for managed data';
4
5-- Create Catalog (for external data)
6CREATE CATALOG IF NOT EXISTS ctg_ext
7 COMMENT 'Catalog for external data';
- Création des schémas La liste des schémas est la suivante :
ctg_ext.sch_ref: Schéma permettant de regrouper les tables externes pour l’accès aux données référentielsctg_ipp.sch_bronze: Schéma permettant de stocker les données brutesctg_ipp.sch_silver: Schéma permettant de stocker les données raffinéesctg_ipp.sch_gold: Schéma permettant de stocker les données agrégéesctg_ipp.sch_gold_v: Schéma permettant de définir les vues pour l’exposition des donnéesctg_ipp.sch_reject: Schéma permettant de stocker les données rejetées
1-- Create Schema for external data
2CREATE SCHEMA IF NOT EXISTS ctg_ext.sch_ref
3 COMMENT 'Schema for external referential data';
4
5-- Create Schema for managed data
6CREATE SCHEMA IF NOT EXISTS ctg_ipp.sch_bronze
7 COMMENT 'Schema for Bronze Data';
8CREATE SCHEMA IF NOT EXISTS ctg_ipp.sch_silver
9 COMMENT 'Schema for Silver Data';
10CREATE SCHEMA IF NOT EXISTS ctg_ipp.sch_gold
11 COMMENT 'Schema for Gold Data';
12CREATE SCHEMA IF NOT EXISTS ctg_ipp.sch_gold_v
13 COMMENT 'Schema for Gold Views';
14CREATE SCHEMA IF NOT EXISTS ctg_ipp.sch_reject
15 COMMENT 'Schema for Reject Data';
- Création des tables externes (External Table) pour accéder aux données des référentiels
1-- Create external table (referential)
2CREATE TABLE ctg_ext.sch_ref.ref_clients (
3 id int
4 ,lib string
5 ,age int
6 ,contact string
7 ,phone string
8 ,is_member string
9 ,last_maj timestamp
10)
11USING CSV
12OPTIONS (path "s3://s3-demo-data-uc/demo/ref_clients.csv",
13 delimiter ",",
14 header "true");
15
16CREATE TABLE ctg_ext.sch_ref.ref_products (
17 id int
18 ,lib string
19 ,brand string
20 ,os string
21 ,last_maj timestamp
22)
23USING CSV
24OPTIONS (path "s3://s3-demo-data-uc/demo/ref_products.csv",
25 delimiter ",",
26 header "true");
27
28CREATE TABLE ctg_ext.sch_ref.ref_shops (
29 id int
30 ,lib string
31 ,postal_code string
32 ,surface int
33 ,last_maj timestamp
34)
35USING CSV
36OPTIONS (path "s3://s3-demo-data-uc/demo/ref_shops.csv",
37 delimiter ",",
38 header "true")
39 ;
40
41
42-- Create managed table
43CREATE TABLE ctg_ipp.sch_bronze.fct_transactions_raw (
44 id_trx string
45 ,ts_trx string
46 ,id_product string
47 ,id_shop string
48 ,id_client string
49 ,quantity string
50)
51COMMENT 'Bronze Transactions Data';
52
53
54CREATE TABLE ctg_ipp.sch_reject.fct_transactions_rej (
55 id_rej int
56 ,ts_rej timestamp
57 ,id_trx string
58 ,ts_trx string
59 ,id_product string
60 ,id_shop string
61 ,id_client string
62 ,quantity string
63)
64COMMENT 'Reject Transactions Data';
65
66
67CREATE TABLE ctg_ipp.sch_silver.fct_transactions (
68 id_trx integer
69 ,ts_trx timestamp
70 ,id_product integer
71 ,id_shop integer
72 ,id_client integer
73 ,quantity integer
74 ,ts_tech timestamp
75)
76COMMENT 'Silver Transactions Data';
77
78
79CREATE TABLE ctg_ipp.sch_gold.fct_transactions_agg_day (
80 dt_trx date
81 ,id_product integer
82 ,is_member boolean
83 ,quantity integer
84 ,ts_tech timestamp
85)
86COMMENT 'Gold Transactions Data Agg Day';
- Alimentation des tables managées
1-- Insert Bronze Data
2COPY INTO ctg_ipp.sch_bronze.fct_transactions_raw
3 FROM 's3://s3-demo-data-uc/demo/fct_transactions.csv'
4 FILEFORMAT = CSV
5 FORMAT_OPTIONS ('encoding' = 'utf8'
6 ,'inferSchema' = 'false'
7 ,'nullValue' = 'N/A'
8 ,'mergeSchema' = 'false'
9 ,'delimiter' = ','
10 ,'header' = 'true'
11 ,'mode' = 'failfast')
12;
13
14
15-- Insert Reject Data
16INSERT INTO ctg_ipp.sch_reject.fct_transactions_rej (
17 id_rej
18 ,ts_rej
19 ,id_trx
20 ,ts_trx
21 ,id_product
22 ,id_shop
23 ,id_client
24 ,quantity
25)
26SELECT 1 as id_rej
27 ,current_timestamp() as ts_rej
28 ,id_trx
29 ,ts_trx
30 ,id_product
31 ,id_shop
32 ,id_client
33 ,quantity
34FROM ctg_ipp.sch_bronze.fct_transactions_raw
35WHERE TRY_CAST(quantity AS integer) IS NULL
36 OR TRY_CAST(quantity AS integer) < 1 ;
37
38
39
40-- Insert Silver Data
41INSERT INTO ctg_ipp.sch_silver.fct_transactions (
42 id_trx
43 ,ts_trx
44 ,id_product
45 ,id_shop
46 ,id_client
47 ,quantity
48 ,ts_tech
49)
50SELECT
51 case when (id_trx = 'N/A') then -1 else cast(id_trx as integer) end as id_trx
52 ,case when (ts_trx='N/A') then cast('1900-01-01 00:00:00' as timestamp) else cast(ts_trx as timestamp) end as ts_trx
53 ,case when (id_product = 'N/A') then -1 else cast(id_product as integer) end as id_product
54 ,case when (id_shop = 'N/A') then -1 else cast(id_shop as integer) end as id_shop
55 ,case when (id_client = 'N/A') then -1 else cast(id_client as integer) end as id_client
56 ,case when (quantity = 'N/A') then 0 else cast(quantity as integer) end as quantity
57 ,current_timestamp() as ts_tech
58FROM ctg_ipp.sch_bronze.fct_transactions_raw
59WHERE case when (quantity = 'N/A') then 0 else cast(quantity as integer) end > 0 ;
60
61
62
63-- Insert Gold Data
64INSERT INTO ctg_ipp.sch_gold.fct_transactions_agg_day (
65 dt_trx
66 ,id_product
67 ,is_member
68 ,quantity
69 ,ts_tech
70)
71SELECT cast(trx.ts_trx as date) as dt_trx
72 ,trx.id_product
73 ,case when (rc.is_member = 'Yes') then true else false end is_member
74 ,sum(trx.quantity) as quantity
75 ,current_timestamp() as ts_tech
76FROM ctg_ipp.sch_silver.fct_transactions trx
77INNER JOIN ctg_ext.sch_ref.ref_clients rc
78ON (rc.id = trx.id_client)
79GROUP BY dt_trx
80 ,trx.id_product
81 ,rc.is_member;
- Création des vues
1-- Create Views
2CREATE OR REPLACE VIEW ctg_ipp.sch_gold_v.fct_transactions_day_products
3AS
4SELECT atd.dt_trx
5 ,rp.lib as lib_product
6 ,atd.quantity
7 ,atd.ts_tech
8FROM ctg_ipp.sch_gold.fct_transactions_agg_day atd
9LEFT OUTER JOIN ctg_ext.sch_ref.ref_products rp
10ON (rp.id = atd.id_product)
11where is_member = true;
12
13
14CREATE OR REPLACE VIEW ctg_ipp.sch_gold_v.fct_transactions_detail
15AS SELECT trx.id_trx
16 ,trx.ts_trx
17 ,rp.lib as lib_product
18 ,rp.brand as brand_product
19 ,rp.os as os_product
20 ,rs.lib as lib_shop
21 ,rs.postal_code as postal_code_shop
22 ,rc.lib as name_client
23 ,case when is_member('admins') then rc.contact else 'XXX@XXX.XX' end as contact_client
24 ,trx.ts_tech
25FROM ctg_ipp.sch_silver.fct_transactions trx
26INNER JOIN ctg_ext.sch_ref.ref_clients rc
27ON (trx.id_client = rc.id)
28LEFT OUTER JOIN ctg_ext.sch_ref.ref_shops rs
29ON (trx.id_shop = rs.id)
30LEFT OUTER JOIN ctg_ext.sch_ref.ref_products rp
31ON (trx.id_product = rp.id);
Data Explorer
L’outil Data Explorer permet d’avoir une interface utilisateur pour l’exploration et la gestion des données (Catalogue, Schéma, Tables, Vues, Droits) et permet d’avoir de nombreuses informations sur les différents objets ainsi que sur leur utilisation.
Cet outil est accessible dans toutes les vues du Workspace Databricks (Data Science & Engineering, Machine Learning, SQL) en cliquant sur l’option Data du menu latéral.
Cet outil utilise les droits d’accès de l’utilisateur du Workspace Databricks, par conséquent il est nécessaire d’avoir les droits suffisants sur les objets.
Pour pouvoir explorer les éléments sans avoir le droit de lire les données, il faut avoir le droit USE sur les différents objets (Catalogue, Schéma, Table, Vue)
Pour pouvoir accéder à un échantillon des données ou à l’historique d’une table au format Delta, il faut avoir le droit SELECT en plus du droit USE.
Il est possible d’accéder aux métadonnées de l’ensemble des éléments de l’Unity Catalog sans utiliser un SQL Warehouse. Pour les actions suivantes, il est nécessaire d’avoir un SQL Warehouse actif pour lire les données nécessaires :
- Accès au catalogue
hive_metastore - Accès à un échantillon des données d’une table
- Accès à l’historique d’une table Delta
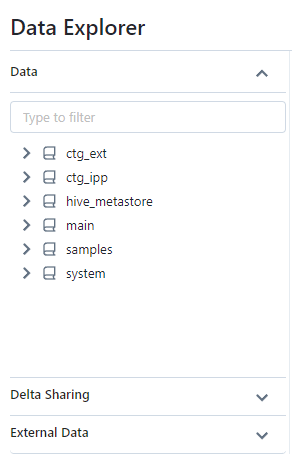
Le menu Explorer (barre latérale) permet d’accéder aux éléments suivants :
- Option
Data: Permet de naviguer dans la hiérarchie des éléments du Metastore (Catalogues, Schémas, Tables, Vues, …) - Option
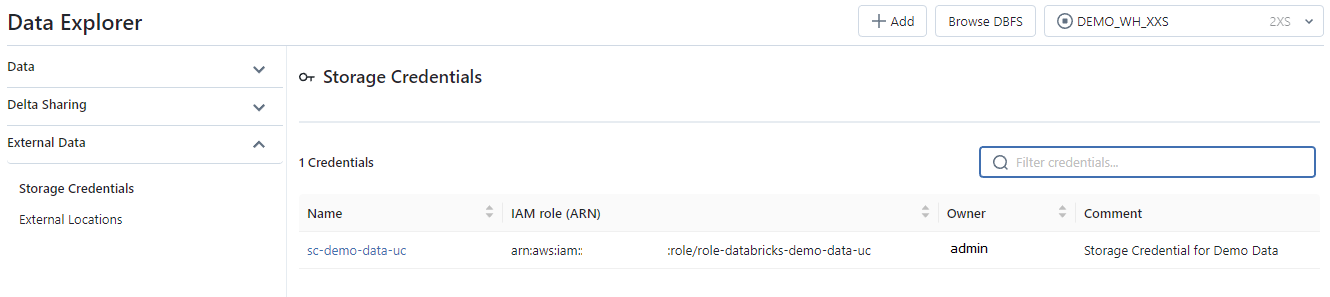
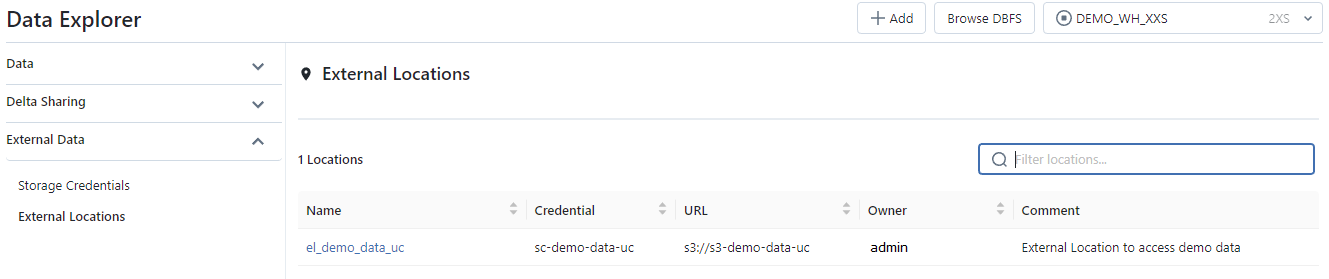
External Data: Contient la liste des éléments concernant les Storage Credential et les External Location.
Écran de l’option Data :
Écran de l’option External Data :
L’interface Principale permet d’accéder aux éléments suivants :
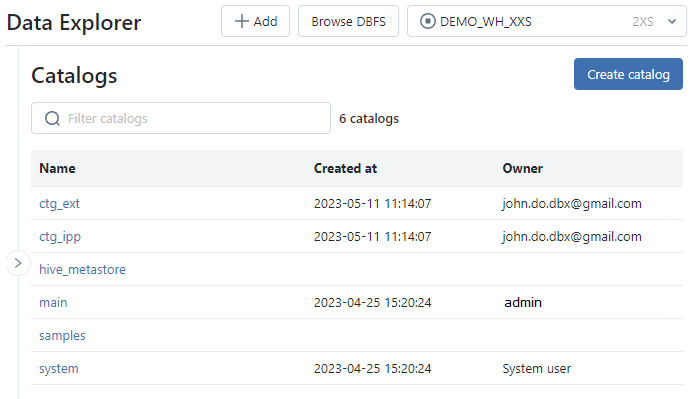
- Affichage de la liste des catalogues, visibles par l’utilisateur, avec pour chaque catalogue le timestamp de création et le propriétaire (créateur par défaut)
- Permet de créer, renommer ou supprimer un catalogue
Écran de l’interface Principale :
L’interface Catalog :
- Onglet
Schemas: Affichage de la liste des schémas, visibles par l’utilisateurs, dans le catalogue avec pour chaque schéma le timestamp de création et le propriétaire (créateur par défaut) - Onglet
Detail: Affichage du détail des informations concernant le catalogue (Metastore Id, …) - Onglet
Permissions: Gestion des droits sur le catalogue
Écran de l’onglet Schemas de l’interface Catalog :
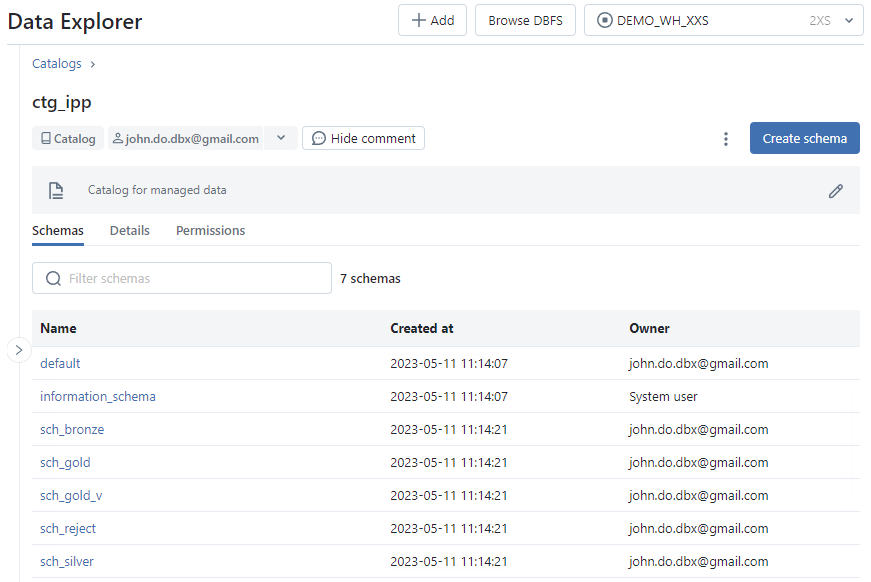
Écran de l’onglet Details de l’interface Catalog :
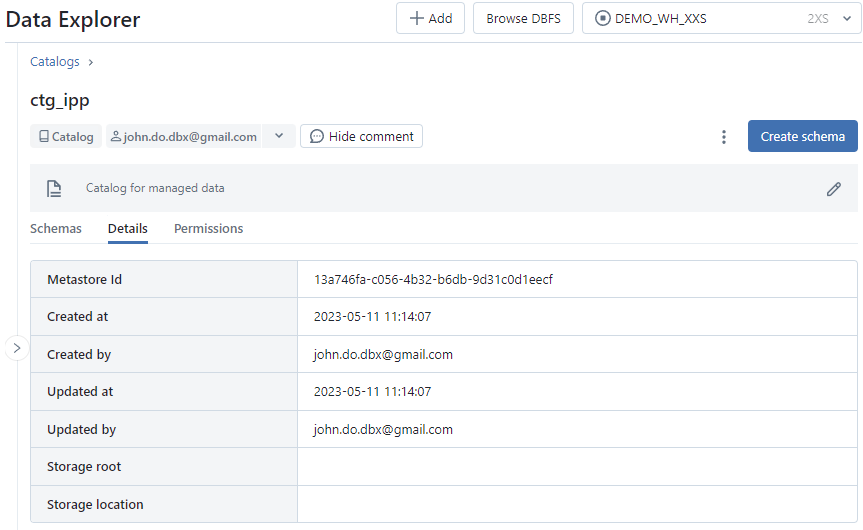
L’interface Schema d’un catalogue :
- Onglet
Tables: Affichage de la liste des objets (tables et vues), visibles de l’utilisateur, dans le schéma avec leur timestamp de création et le propriétaire (créateur par défaut) - Onglet
Details: Détail des informations concernant le schéma - Onglet
Permissions: Gestion des droits sur le schéma
Écran de l’onglet Tables de l’interface Schema :
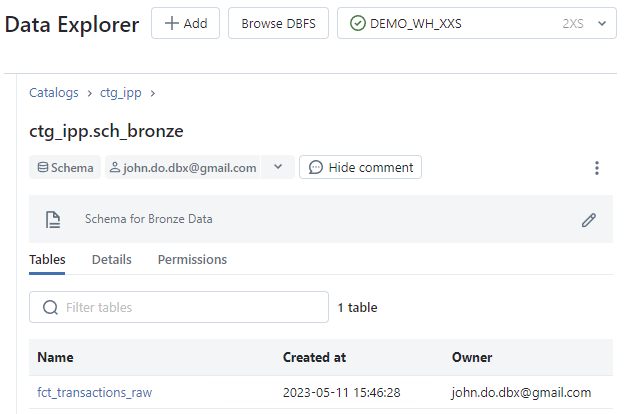
Écran de l’onglet Details de l’interface Schema :
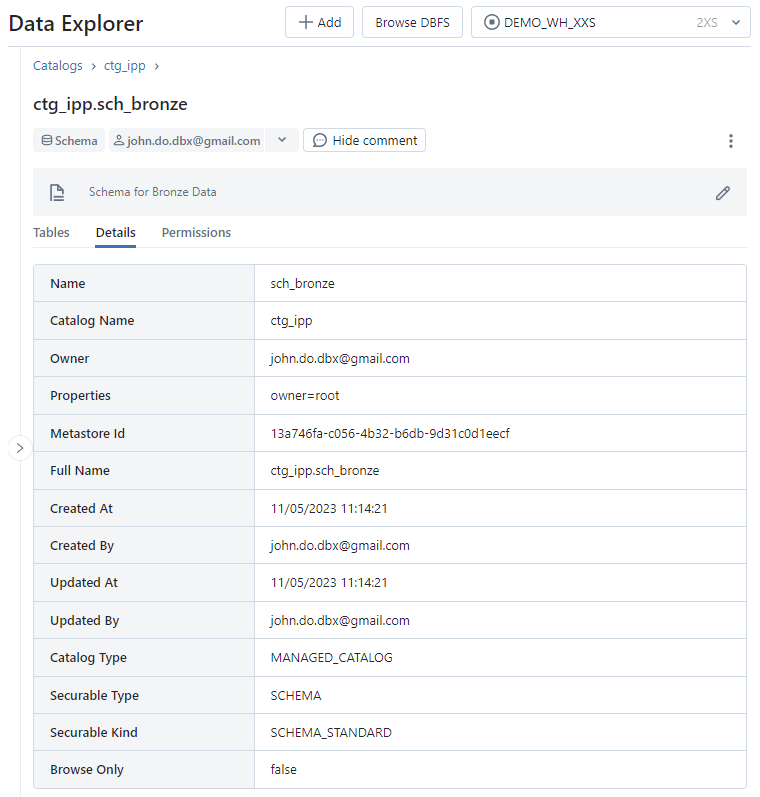
L’interface Table d’un schéma :
- Onglet
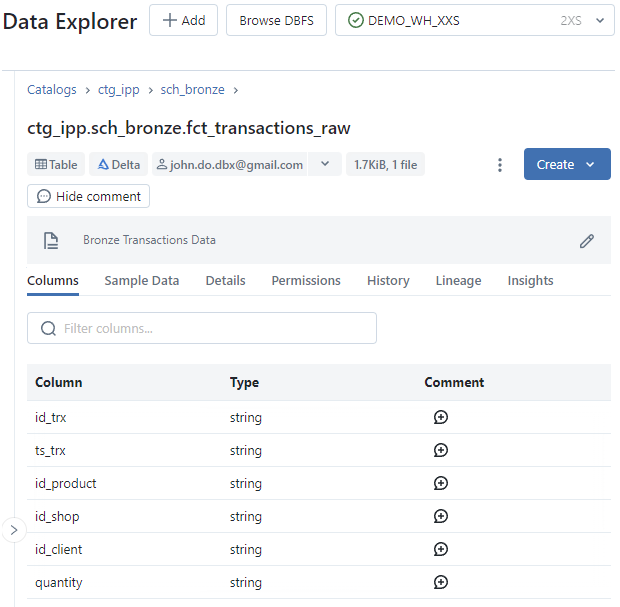
Columns: Affichage de la liste des colonnes (nom et type des données) et gestion des commentaires sur les colonnes - Onglet
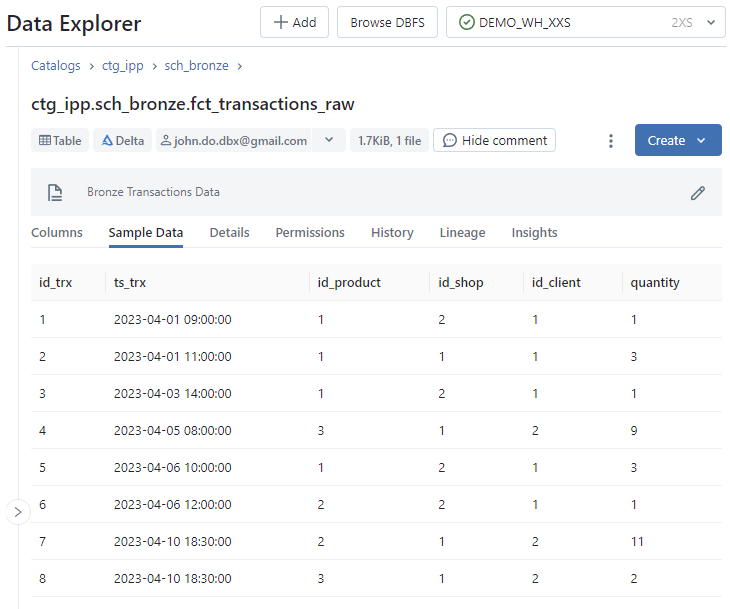
Sample Data: Affichage d’un échantillon des données de l’objet - Onglet
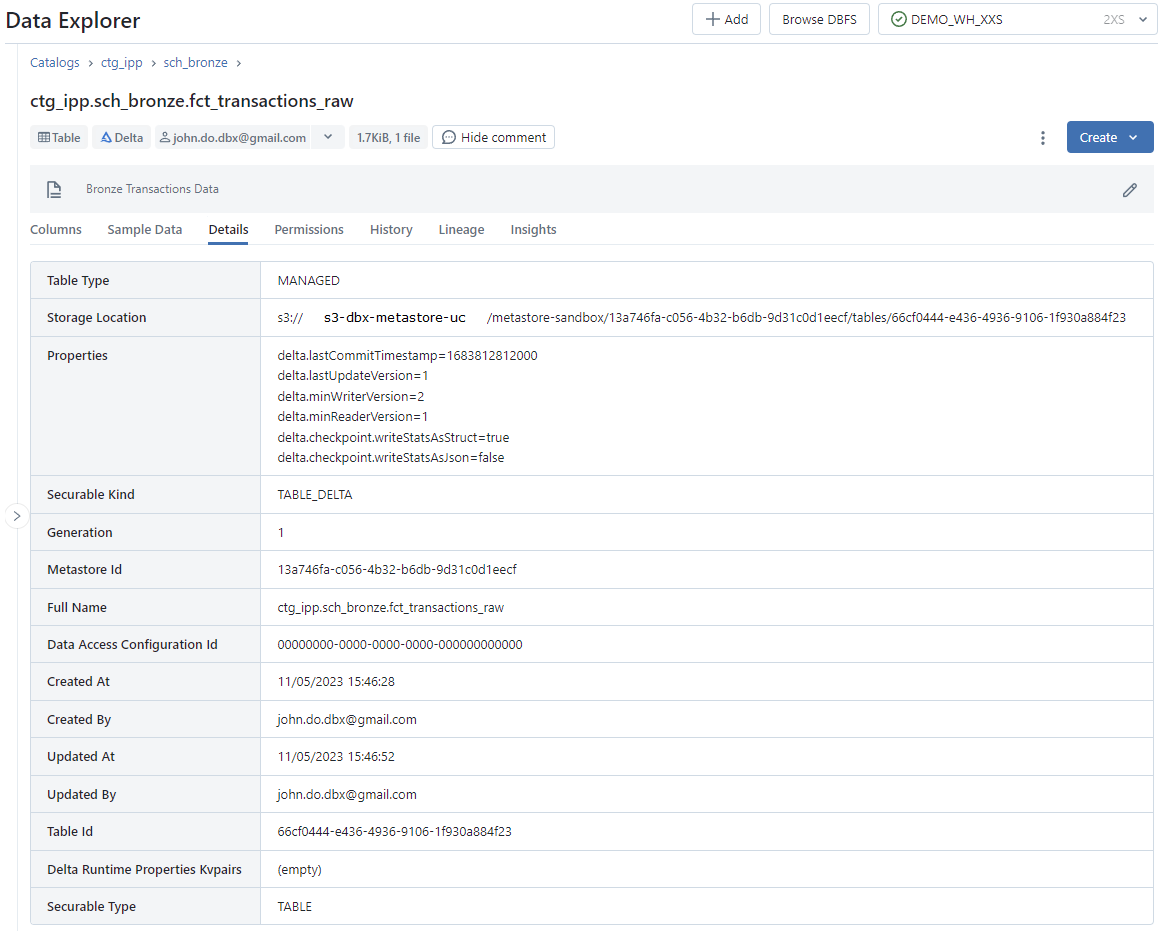
Detail: Affichage du détail des informations concernant l’objet - Onglet
Permissions: Gestion des droits sur l’objet - Onglet
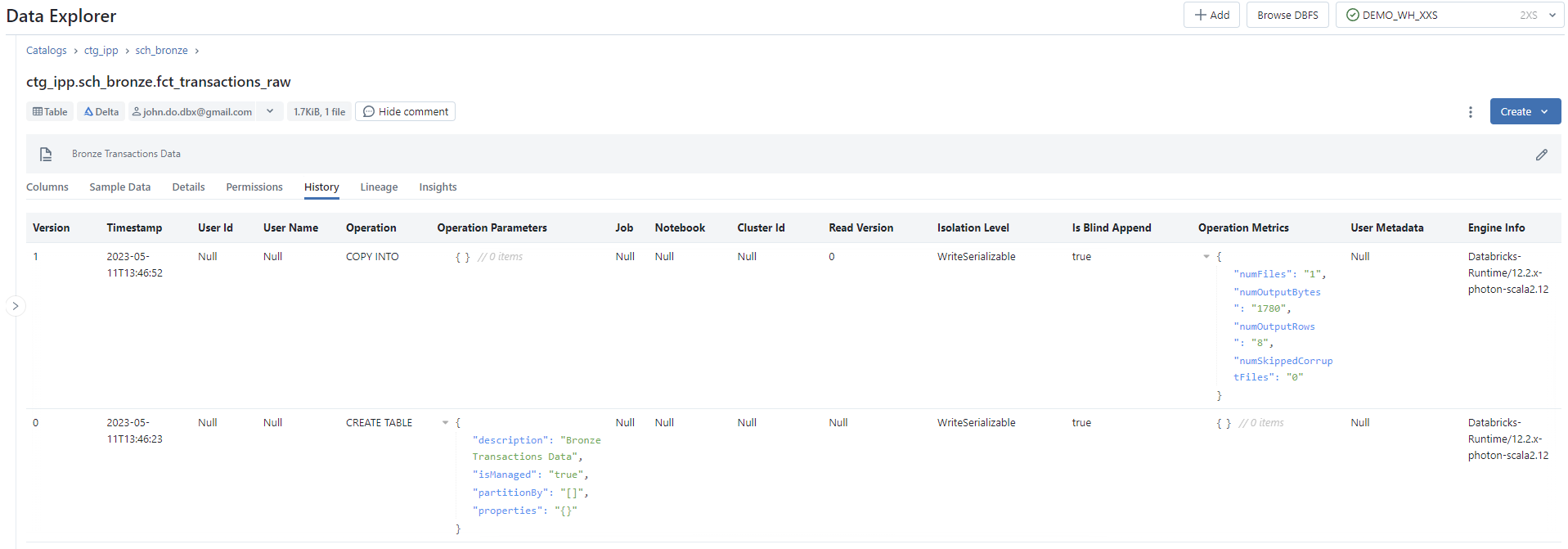
History: Affichage de l’historique des versions de l’objet (lorsque c’est une table au format Delta uniquement) - Onglet
Lineage: Affichage des informations de Data Lineage liées à l’objet - Informations supplémentaires :
- Il est possible de créer une requête ou un dashboard directement à partir de Data Explorer en cliquant sur
Createet en sélectionnant l’une des options (QueryouQuick dashboard) - Il est possible de renommer ou supprimer un objet en cliquant sur le bouton avec les 3 points et en sélectionnant l’une des options (
RenameouDelete) - L’en-tête de l’écran permet d’afficher des informations sur l’objet comme le type, le format des données, le nom du propriétaire, le poids des données et le commentaire
- Il est possible de créer une requête ou un dashboard directement à partir de Data Explorer en cliquant sur
Écran de l’onglet Columns de l’interface Table :
Écran de l’onglet Sample Data de l’interface Table :
Écran de l’onglet Detail de l’interface Table :
Écran de l’onglet History de l’interface Table :
Data Lineage
Synthèse
Cette fonctionnalité est activée par défaut lors de la mise en place de la solution Unity Catalog.
L’accès aux données de la fonctionnalité Data Lineage proposée par la solution Unity Catalog peut se faire de 3 façons différentes :
- Accéder à l’onglet
Lineaged’un objet (Table ou Vue) avec l’outil Data Explorer - Utilisation de Databricks REST API pour extraire des informations à partir de la solution Unity Catalog
- Utilisation d’un outil de gouvernance de données qui à un connecteur Databricks permettant d’extraire les informations de la solution Unity Catalog vers une application tierce
Nous allons nous concentrer sur l’utilisation de l’outil Data Explorer pour découvrir quelles sont les informations capturées par défaut par la solution Unity Catalog. Pour accéder aux informations de la fonctionnalité Data Lineage :
- Allez sur
Workspace Databricks page > Data - Cliquez sur le catalogue souhaité
- Cliquez sur le schéma souhaité
- Cliquez sur l’objet (table ou vue) souhaité
- Cliquez sur l’option
Lineage
Contrainte pour que les informations de Data Lineage soient capturées pour un objet :
- L’objet doit être défini dans un catalogue du Metastore
- Les requêtes doivent utiliser l’API Dataframe de Spark ou l’interface Databricks SQL
- La capture des informations se basant sur les traitements utilisant l’API Structured Streaming entre les tables Delta n’est supportée qu’à partir du Runtime 11.3 LTS (DBR)
- Pour accéder aux informations de Data Lineage sur les objets (tables ou vues), l’utilisateur doit avoir le droit
SELECTsur ces objets.
Fonctionnement :
- La capture des informations de Data Lineage est faite à partir des logs d’exécution des différents outils (notebooks, requêtes sql, workflow, …) sur les 30 derniers jours (période glissante)
- Cela signifie que les informations de Data Lineage concernant les logs d’exécution des traitements de plus de 30 jours ne sont pas disponible
- La capture se fait jusqu’à la granularité de la colonne de chaque objet
Limitation :
- Lorsque qu’un objet est renommé, les informations de Data Lineage ne sont plus visibles
- La capture des informations de Data Lineage est faite par rapport au nom de l’objet et non pas à l’identifiant unique de la table
- Pour avoir à nouveau les informations de Data Lineage, il faut attendre l’exécution des traitements liés à l’objet
- Lorsqu’une colonne est renommée, les informations de Data Lineage ne sont plus visibles sur la colonne de l’objet de la même manière que pour le renommage d’un objet
- Remarque :
- Il est possible de renommer à nouveau l’objet (table ou vue) ou la colonne avec l’ancien nom pour retrouver l’ensemble des informations de Data lineage déjà capturé
- Lors du renommage d’un objet (pour un objet managé dans le Metastore), l’identifiant de l’objet (et le chemin de stockage) ne change pas. Seulement le nom de l’objet ou de la colonne est modifié.
Pour chaque objet, les informations du Data Lineage sont constitués des éléments suivants :
- Affichage du graphe complet (ensemble des éléments sources et cible en partant de l’objet) et possibilité de naviguer dedans
- Option “Upstream” : Permet de filtrer l’ensemble des éléments utiliser comme source de l’alimentation de l’objet (1er niveau)
- Option “Downstream” : Permet de filtrer l’ensemble des éléments utilisant les données de l’objet (1er niveau)
Les éléments qui peuvent être capturés par Unity Catalog pour un objet (Table ou Vue) sont :
- Les tables : L’ensemble des objets (Tables, Vues) dans le Metastore liés à l’objet concerné
- Les notebooks : L’ensemble des notebooks ayant utilisé l’objet concerné (alimentation ou lecture)
- Les workflows : L’ensemble des workflows ayant un traitement utilisant l’objet concerné (alimentation ou lecture)
- Les pipelines : L’ensemble des pipelines ayant un traitement utilisant l’objet concerné (alimentation ou lecture)
- Les dashboards : L’ensemble des dashboards composé des requêtes SQL utilisant l’objet concerné
- Les requêtes : L’ensemble des requêtes SQL (format notebook utilisant le SQL Warehouse) ayant utilisé l’objet concerné
- Les chemins d’accès aux données : L’ensemble des chemins d’accès aux données externes utilisé par l’objet concerné
Visualisation
Visualisation du Data Lineage à partir de la table ctg_ipp.sch_bronze.fct_transactions_raw en se limitant uniquement au lien de 1er niveau :
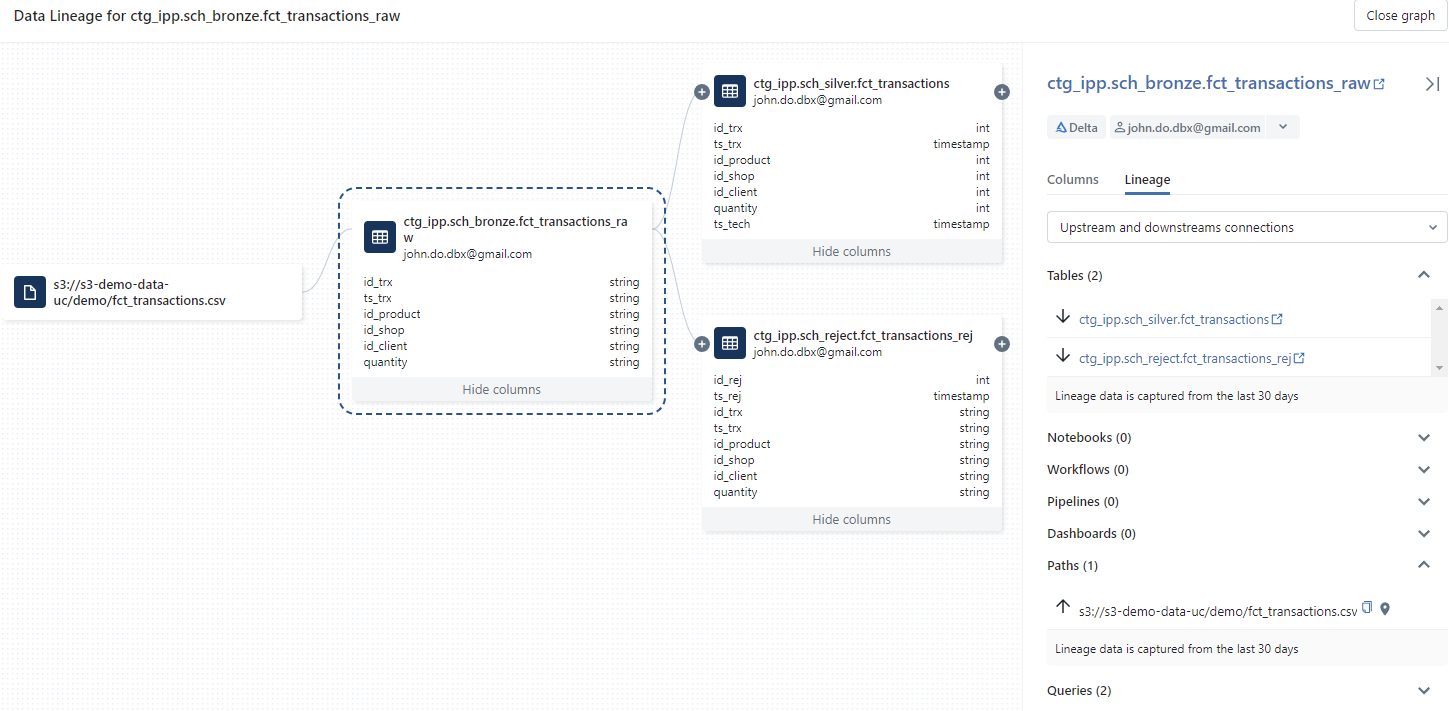
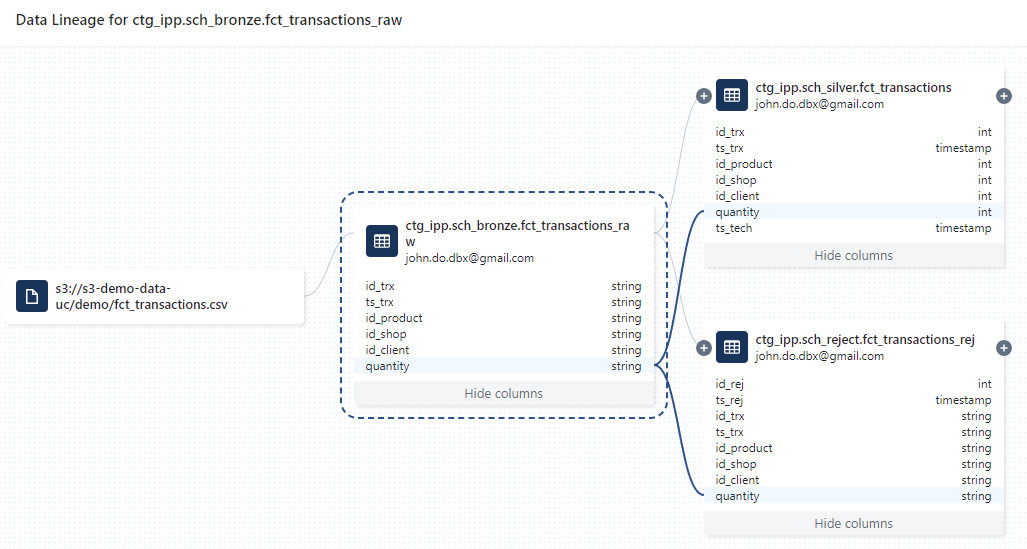
Visualisation du Data Lineage à partir de la colonne quantity de la table ctg_ipp.sch_bronze.fct_transactions_raw :
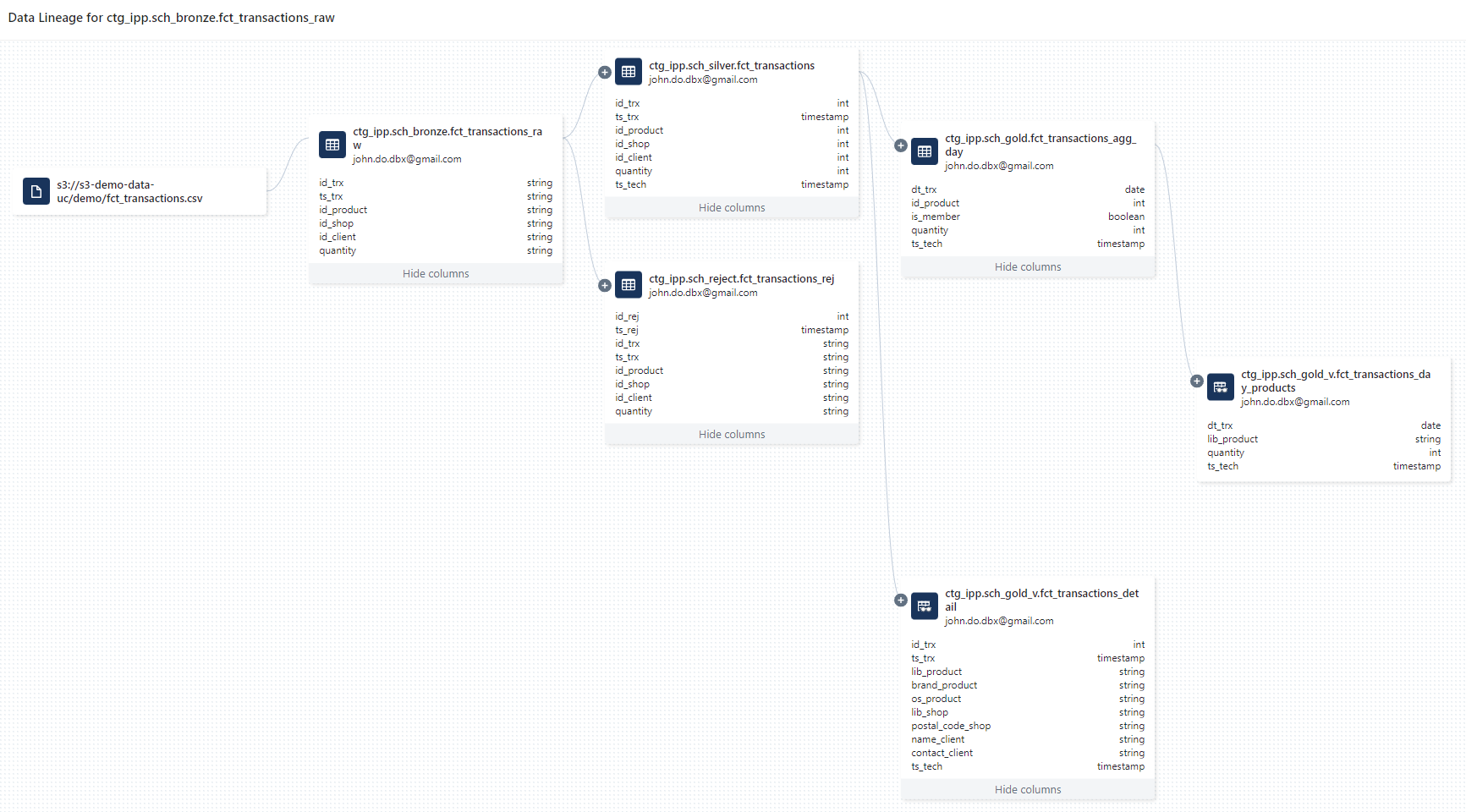
Visualisation du Data Lineage à partir de la table ctg_ipp.sch_bronze.fct_transactions_raw en prenant l’ensemble des liens jusqu’aux vues du schéma ctg_ipp.sch_gold_v
Affichage de la liste des données sources utilisées pour l’alimentation de la table ctg_ipp.sch_bronze.fct_transactions_raw :
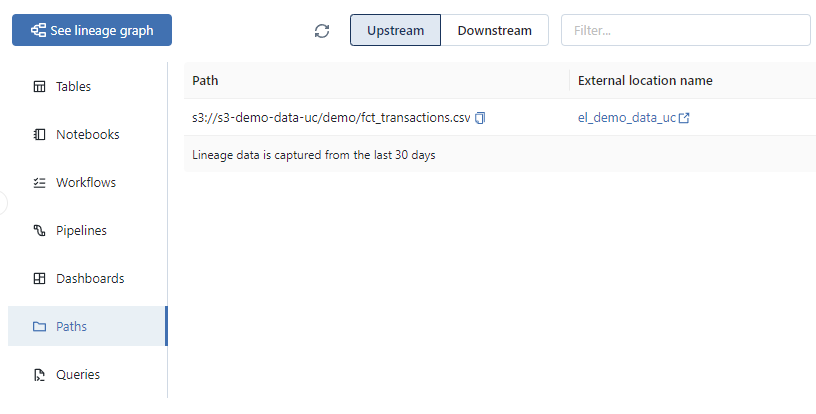
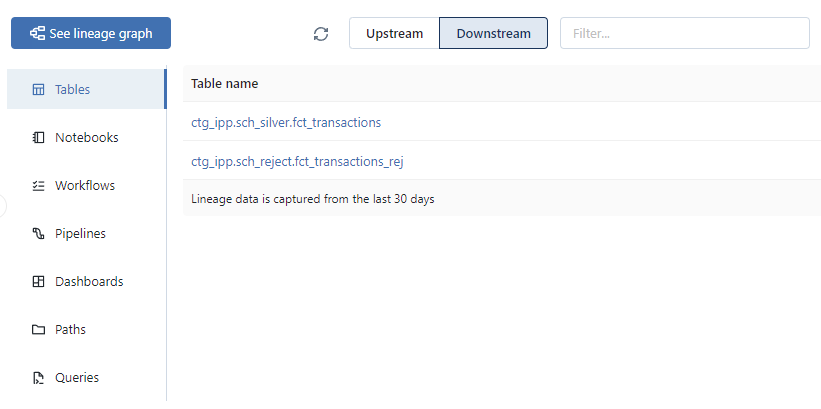
Affichage de la liste des objets dont l’une des sources de données est la table ctg_ipp.sch_bronze.fct_transactions_raw :
Export des données de Data Linage avec Databricks REST API
Pré-requis :
- Avoir l’outil
Curlinstallé - Avoir l’outil
jqinstallé
Préparation des accès à l’API REST et des variables d’environnements :
- Création d’un fichier
.netrcpermettant de gérer les accès à l’API REST :
1# Create the folder where the .netrc file will be stored
2mkdir ~/.databricks
3
4# Create the .netrc file
5echo "machine <url workspace databricks without https://>
6login token
7password <token user databricks>
8" > ~/.databricks/.netrc
- Création des variables d’environnements et des alias :
1# Create an alias to use the tool curl with .netrc file
2alias dbx-api='curl --netrc-file ~/.databricks/.netrc'
3
4# Create an environment variable with Databricks API Url
5export DBX_API_URL="<url workspace databricks with https://>"
Récupération des informations au niveau de l’objet ctg_ipp.sch_silver.fct_transactions :
1# 1. Get the list of upstreams elements from an object
2dbx-api -X GET -H 'Content-Type: application/json' ${DBX_API_URL}/api/2.0/lineage-tracking/table-lineage -d '{"table_name": "ctg_ipp.sch_silver.fct_transactions", "include_entity_lineage": true}}' | jq '.upstreams[]'
3
4# 2. Get the list of downstreams elements from an object
5dbx-api -X GET -H 'Content-Type: application/json' ${DBX_API_URL}/api/2.0/lineage-tracking/table-lineage -d '{"table_name": "ctg_ipp.sch_silver.fct_transactions", "include_entity_lineage": true}}' | jq '.downstreams[]'
Résultat au format JSON de la liste des éléments utilisés pour l’alimentation de l’objet ctg_ipp.sch_silver.fct_transactions :
1{
2 "tableInfo": {
3 "name": "fct_transactions_raw",
4 "catalog_name": "ctg_ipp",
5 "schema_name": "sch_bronze",
6 "table_type": "TABLE"
7 },
8 "queryInfos": [
9 {
10 "workspace_id": 1198890856567221,
11 "query_id": "40af215d-e21d-4933-b207-c478b78a38d6"
12 }
13 ]
14}
Résultat au format JSON de la liste des éléments utilisant l’objet ctg_ipp.sch_silver.fct_transactions :
1{
2 "tableInfo": {
3 "name": "fct_transactions_detail",
4 "catalog_name": "ctg_ipp",
5 "schema_name": "sch_gold_v",
6 "table_type": "PERSISTED_VIEW"
7 },
8 "queryInfos": [
9 {
10 "workspace_id": 1198890856567221,
11 "query_id": "40af215d-e21d-4933-b207-c478b78a38d6"
12 },
13 {
14 "workspace_id": 1198890856567221,
15 "query_id": "bf2570b5-bfd8-444d-b2a7-d896192f063f"
16 }
17 ]
18}
19{
20 "tableInfo": {
21 "name": "fct_transactions_agg_day",
22 "catalog_name": "ctg_ipp",
23 "schema_name": "sch_gold",
24 "table_type": "TABLE"
25 },
26 "queryInfos": [
27 {
28 "workspace_id": 1198890856567221,
29 "query_id": "40af215d-e21d-4933-b207-c478b78a38d6"
30 },
31 {
32 "workspace_id": 1198890856567221,
33 "query_id": "bf2570b5-bfd8-444d-b2a7-d896192f063f"
34 }
35 ]
36}
Récupération des informations au niveau de la colonne quantity de l’objet ctg_ipp.sch_silver.fct_transactions :
1# 1. Get the list of upstreams columns from a column
2dbx-api -X GET -H 'Content-Type: application/json' ${DBX_API_URL}/api/2.0/lineage-tracking/column-lineage -d '{"table_name": "ctg_ipp.sch_silver.fct_transactions", "column_name": "quantity"}}' | jq '.upstream_cols[]'
3
4# 2. Get the list of downstreams columns from a column
5dbx-api -X GET -H 'Content-Type: application/json' ${DBX_API_URL}/api/2.0/lineage-tracking/column-lineage -d '{"table_name": "ctg_ipp.sch_silver.fct_transactions", "column_name": "quantity"}}' | jq '.downstream_cols[]'
Résultat au format JSON de la liste des colonnes utilisées pour l’alimentation de la colonne quantity de l’objet ctg_ipp.sch_silver.fct_transactions :
1{
2 "name": "quantity",
3 "catalog_name": "ctg_ipp",
4 "schema_name": "sch_bronze",
5 "table_name": "fct_transactions_raw",
6 "table_type": "TABLE",
7 "path": "s3://s3-dbx-metastore-uc/metastore-sandbox/13a746fa-c056-4b32-b6db-9d31c0d1eecf/tables/66cf0444-e436-4936-9106-1f930a884f23"
8}
Résultat au format JSON de la liste des colonnes utilisant la colonne quantity de l’objet ctg_ipp.sch_silver.fct_transactions :
1{
2 "name": "quantity",
3 "catalog_name": "ctg_ipp",
4 "schema_name": "sch_gold",
5 "table_name": "fct_transactions_agg_day",
6 "table_type": "TABLE",
7 "path": "s3://s3-dbx-metastore-uc/metastore-sandbox/13a746fa-c056-4b32-b6db-9d31c0d1eecf/tables/9c724ab7-e48b-40fb-8105-a8bc292b591c"
8}
Suppression des éléments
Vous trouverez, ci-dessous, l’ensemble des instructions nécessaires pour nettoyer l’environnement.
Suppression des éléments de Unity Catalog en utilisant les instructions SQL :
1-- Delete the Catalog with CASCADE option (to delete all objects)
2DROP CATALOG IF EXISTS ctg_ipp CASCADE;
3DROP CATALOG IF EXISTS ctg_ext CASCADE;
Suppression des données utilisées sur la ressource AWS S3 :
1# Delete all files stored in the AWS S3 resource
2aws s3 rm "s3://s3-demo-data-uc/demo/" --recursive
Conclusion
L’outil Data Explorer permet de faciliter l’exploration des données au sein du Metastore de la solution Unity Catalog et de gérer les droits d’accès sur les objets sans connaître les commandes SQL.
Les informations du Data Lineage capturées par la solution Unity Catalog permettent d’avoir un certain nombre d’informations sur le cycle de vie des données ainsi que sur la liste des éléments utilisant un objet spécifique. Cela permet d’avoir facilement une liste des éléments (notebooks, workflows, pipelines, requêtes,…) utilisant l’objet et par conséquent pouvant être impactés en cas de modification de l’objet. Cela permet aussi de permettre la visualisation et la navigation en se basant sur les informations de Data Lineage (liens entre les objets jusqu’au niveau des colonnes).
Point d’attention : La contrainte des 30 derniers jours (glissant) pour la capture des informations peut être très limitante dans le cadre d’une application ayant des traitements avec une fréquence supérieur eou égale au mois.