
Databricks : Unity Catalog - Découverte - Partie 5 - Delta Live Tables
Nous allons découvrir le framework Delta Live Tables avec la solution Unity Catalog à la place du Hive Metastore.
Nous allons nous concentrer sur les éléments propres à la solution Unity Catalog.
L’utilisation de la solution Unity Catalog avec le framework Delta Live Tables était en “Public Preview” lors de la rédaction de ce papier début Juin 2023.
Nous allons utiliser un Account Databricks sur AWS pour réaliser cette découverte.
Note : Nous allons garder des termes techniques en anglais pour faciliter la compréhension
Qu’est ce que Delta Live Tables
Synthèse
Delta Live Tables est un framework permettant de travailler de manière déclarative afin de définir l’ensemble des éléments d’un traitement ETL (pipeline).
Ce framework permet de travailler en Python et en SQL.
Ce framework permet de définir des objets dans un script en Python ou dans un notebook en Python ou en SQL qui sera exécuté par un pipeline DLT (Delta Live Tables) en s’appuyant sur la fonctionnalité “Workflows”.
Ce framework se base sur les trois types d’objets suivant afin de gérer l’orchestration de l’ensemble des actions d’un pipeline DLT :
- Streaming Table : Cela correspond au terme SQL
STREAMING TABLE <objet> - Materialized View : Cela correspond au terme SQL
LIVE TABLE <objet> - View : Cela correspond au terme SQL
TEMPORARY LIVE VIEW <objet>ouTEMPORARY STREAMING LIVE VIEW <objet>
Vous pourrez retrouver dans ce lien l’ensemble des informations concernant le coût et les fonctionnalités accessibles par type d’édition. Une vision très synthétique des différentes éditions :
- DLT Core :
- Permet de gérer l’ensemble des fonctionnalité de base
- DLT Pro :
- Permet de gérer l’ensemble des fonctionnalités de l’édition “DLT Core” et la gestion du Change Data Capture (CDC) ainsi que de l’alimentation d’un objet en Slow Changing Dimension (SCD) de type 2 (très utile pour simplifier la gestion des données d’un référentiel lorsque l’on souhaite garder l’historique des changements)
- DLT Advanced :
- Permet de gérer l’ensemble des fonctionnalités de l’édition “DLT Pro” ainsi que toutes les fonctionnalités de gestion de la qualité des données (principalement la définition des contraintes (expectations) et leur observabilité (métriques))
Concernant les objets
Concernant l’objet Streaming Table :
- Cet objet permet de gérer la lecture d’une source de données en streaming et pouvoir lire un enregistrement seulement une fois (Spark Structured Streaming)
- La gestion des éléments (checkpoint, …) est géré par défaut par le framework DLT
- La source de données doit être en “append-only”
- Si la source de données est gérée avec Auto Loader, une colonne supplémentaire nommée
_rescued_datasera créée par défaut pour gérer les données mal formées. - Il est possible de définir des contraintes (expectations) au niveau de l’objet
- La lecture d’un objet “Streaming table” dans un même pipeline DLT se fait par l’utilisation de la syntaxe
STREAM(LIVE.<object>)(SQL) oudlt.read_stream("<object>")(Python) - Il est possible de définir l’ingestion des données d’un objet “Streaming Table” avec un processus de Slow Changing Dimension de type 2 automatiquement géré par le framework DLT
- Cela permet de très simplement mettre en place à partir d’une source utilisant du CDC (Change Data Capture) ou du CDF (Change Data Feed) une gestion d’historique pour des données de type référentiel
- Vu que les objets sont gérés par le framework DLT lors de l’exécution d’un pipeline DLT, il n’est pas souhaitable de faire des modifications sur les données en dehors du pipeline DLT.
- Il est possible de faire des modifications (requête de type DML) avec certaines limitations sur les objets “Streaming Table” mais cela n’est pas recommandé et toutes les opérations ne sont pas supportées.
Concernant l’objet Materialized View :
- Cet objet permet de gérer le rafraîchissement des données d’un objet en fonction de son état lors de l’exécution du pipeline DLT, le framework DLT définit de ce qu’il doit mettre à jour en fonction de l’état des sources et de la cible.
- Il est possible de définir des contraintes (expectations) au niveau de l’objet
- La lecture d’un objet “Materialized View” dans un même pipeline DLT se fait par l’utilisation de la syntaxe
LIVE.<object>(SQL) oudlt.read("<object>")(Python) - Il n’est pas possible d’exécuter des requêtes de types DML (Update, Delete, Insert) dans un object “Materialized View” car l’objet accessible n’est pas défini comme une table Delta.
- Pour accéder en lecture à un objet “Materialized View” en dehors du pipeline DLT, il faut utilisé un Cluster “Shared” ou un SQL Warehouse de type Pro ou Serverless (recommandé)
Concernant l’objet View :
- Cet objet permet de définir une vue temporaire (requête encapsulé) sur une source de données, cette vue n’existera que durant l’exécution du pipeline DLT
- La requête encapsulé est exécutée à chaque lecture de l’objet
- Il est possible de définir des contraintes (expectations) au niveau de l’objet
Concernant la gestion de la qualité des données
La gestion de la qualité des données se fait en déclarant des contraintes (expectations) sur les objets :
- Syntaxe en SQL :
CONSTRAINT expectation_name EXPECT (expectation_expr) [ON VIOLATION { FAIL UPDATE | DROP ROW }]
Lorsque l’on défini une contrainte (expectation) sur un objet, le framework DLT fera le contrôle lors de l’ingestion de l’enregistrement et réalisera l’action définie :
CONSTRAINT expectation_name EXPECT (expectation_expr): Lorsqu’il n’y a pas d’action défini, alors les enregistrements ne respectant pas la contrainte seront insérés dans l’objet et une information sera ajoutée dans les logs d’événement du pipeline DLT avec le nombre d’enregistrements concernés pour cet objet.CONSTRAINT expectation_name EXPECT (expectation_expr) ON VIOLATION FAIL UPDATE: Lorsque l’action définie est “FAIL UPDATE”, alors le pipeline DLT s’arrêtera en erreur au premier enregistrement ne respectant pas la contrainte avec le message d’erreur dans les logs d’événement du pipeline DLT.CONSTRAINT expectation_name EXPECT (expectation_expr) ON VIOLATION DROP ROW: Lorsque l’action définie est “DROP ROW”, alors les enregistrements ne respectant pas la contrainte ne seront pas insérés dans l’objet et une information sera ajoutée dans les logs d’événements du pipeline DLT avec le nombre d’enregistrements concernés pour cet objet.
Concernant le pipeline DLT
Afin de pouvoir exécuter un script (Python) ou notebook (SQL ou Python) avec le framework DLT, il est nécessaire de créer un pipeline DLT en précisant l’édition souhaitée.
La définition du pipeline DLT, se fait en utilisant la fonctionnalité “Workflows”. L’accès se fait de la manière suivante :
- Cliquez sur la vue “Data Science & Engineering” du menu latéral
- Cliquez sur l’option “Workflows” du menu latéral
- Cliquez sur l’onglet “Delta Live Tables”
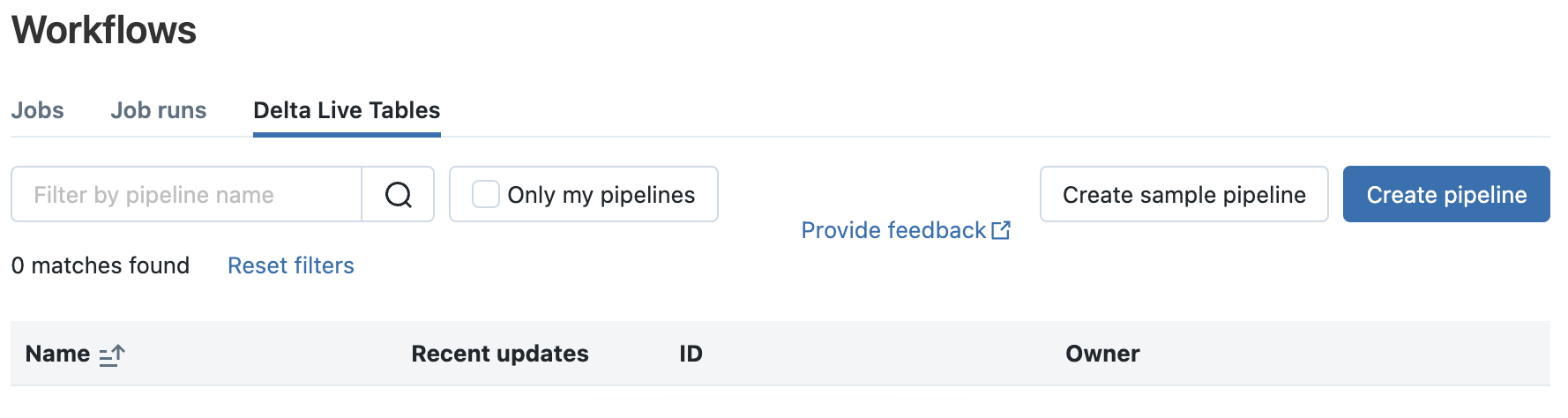
A partir de cet écran, vous pourrez gérer les pipelines DLT (création, suppression, configuration, modification) et visualiser les différentes exécutions (dans la limite de la période de rétention des données d’observabilité de l’édition définie pour chaque pipeline)
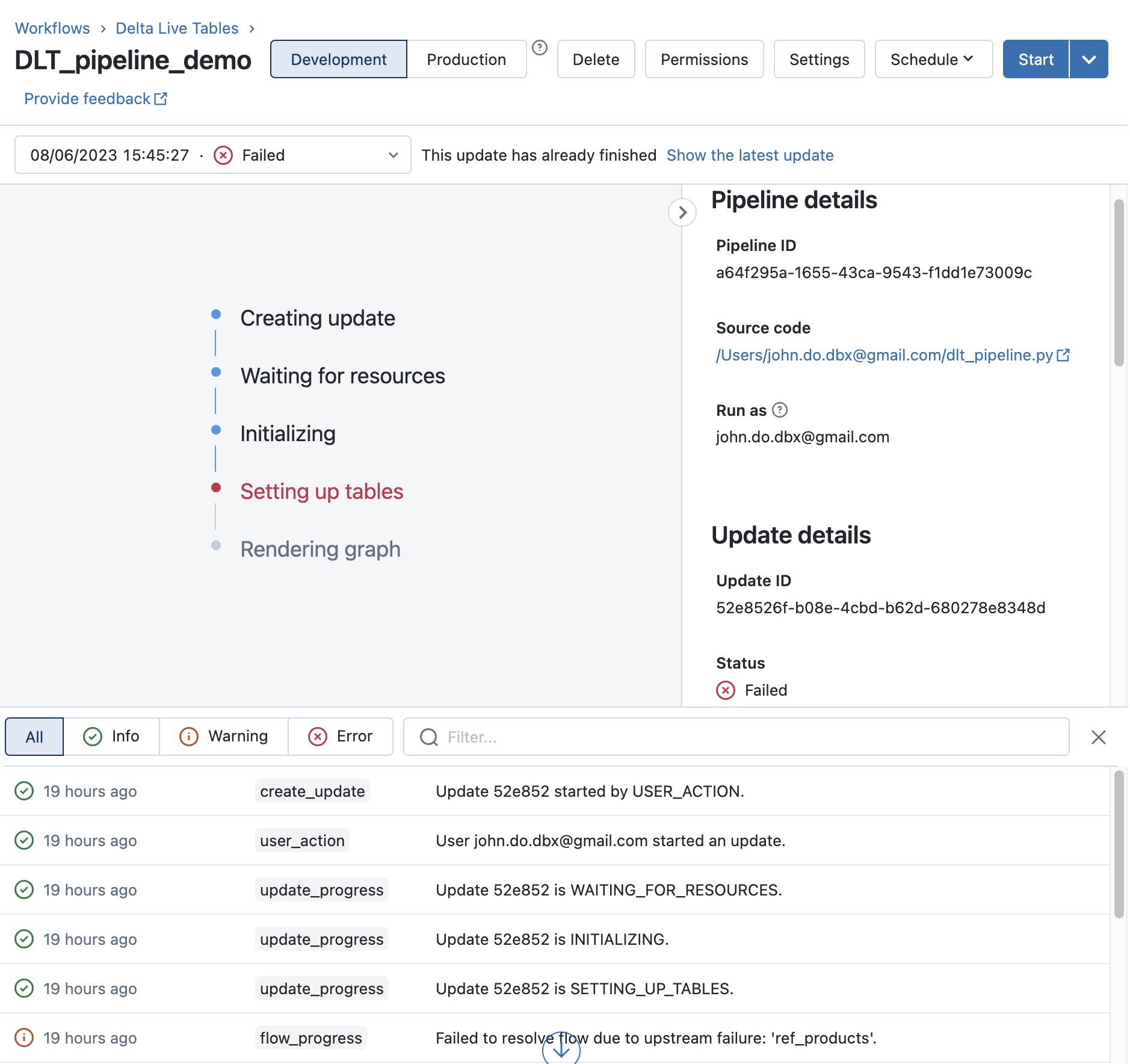
Les informations utiles pour la création d’un pipeline DLT :
- General :
- Product edition : Édition à choisir parmi DLT Core, DLT Pro et DLT Advanced, cela va définir les fonctionnalités utilisables ainsi qu’un des critères du coûts de l’exécution du pipeline DLT
- Pipeline mode :
- Triggered : Permet de gérer l’exécution en mode batch et par conséquent de couper le cluster après exécution du pipeline DLT
- Continuous : Permet de gérer l’exécution en mode streaming et par conséquent d’exécuter le pipeline en continue pour traiter les données dès qu’elles arrivent.
- Source Code : Permet de définir le script (Python) ou le Notebook (Python ou SQL) devant être exécuter par le pipeline DLT
- Destination
- Storage Option : Choisir Unity Catalog pour utiliser la solution Unity Catalog avec le framework DLT
- Catalog : Définir le catalogue cible du pipeline DLT (catalogue qui contient le schéma cible du pipeline DLT)
- Target schema : Définir le schéma cible du pipeline DLT (Schéma qui sera utilisé pour gérer les objets du pipeline DLT)
- Compute
- Cluster mode : Pour définir si vous voulez un nombre de worker fixe (Fixed size) ou qui s’adapte à la charge de travail dans les limites indiquées (Enhanced autoscaling, Legacy autoscaling)
- Workers : Permet de définir le nombre de workers si le mode est fixe ou le minimum et maximum de workers si le mode n’est pas fixe
Les informations utiles après la création du pipeline DLT :
- Mode d’exécution :
- Development : Dans ce mode, le cluster utilisée par le pipeline DLT ne s’arrêtera qu’après 2h (par défaut) pour éviter le temps de redémarrage d’un cluster et il n’y a pas de gestion de redémarrage automatique.
- Il est possible de modifier le temps d’attention avant l’arrêt du cluster en configurant le paramètre
pipelines.clusterShutdown.delayavec la valeur souhaitée (par exemple “300s” pour 5 minutes) - Exemple :
{"configuration": {"pipelines.clusterShutdown.delay": "300s"}})
- Il est possible de modifier le temps d’attention avant l’arrêt du cluster en configurant le paramètre
- Production : Dans ce mode, le cluster s’arrête automatiquement après l’exécution du pipeline DLT et il redémarre automatiquement en cas de problème technique (fuite mémoires, autorisations, démarrage, …)
- Development : Dans ce mode, le cluster utilisée par le pipeline DLT ne s’arrêtera qu’après 2h (par défaut) pour éviter le temps de redémarrage d’un cluster et il n’y a pas de gestion de redémarrage automatique.
- Schedule :
- Permet de définir une contrainte de déclenchement pour l’exécution du pipeline DLT
- Exécution :
- Start : Pour exécuter le pipeline DLT en prenant en compte uniquement les nouvelles données disponibles
- Start with Full refresh all : Pour exécuter le pipeline DLT en prenant en compte l’ensemble des données disponibles
- Select tables for refresh : Pour définir les objets que l’on souhaite mettre à jour lors de l’exécution du pipeline DLT (exécution partielle)
Attention :
- Il n’est pas possible d’exécuter en local ou avec un cluster Databricks le script ou notebook défini.
- Lorsque vous le ferez, vous aurez le message suivant :
This Delta Live Tables query is syntactically valid, but you must create a pipeline in order to define and populate your table.
- Lorsque vous le ferez, vous aurez le message suivant :
- Un pipeline DLT correspond uniquement à un script ou un notebook, par conséquent si l’on souhaite exécuter plusieurs scripts ou notebooks, il faut utiliser la fonctionnalité “Job” (de la fonctionnalité “Workflows”) pour orchestrer l’exécution de plusieurs pipelines DLT.
- L’exécution du “Job” permettra d’exécuter les pipelines DLT avec les contraintes (et l’orchestration) souhaitées
- Il n’est possible d’accéder à un objet avec la syntaxe du framework DLT qu’au sein du même pipeline DLT, si on souhaite lire le contenu d’un objet en dehors du pipeline DLT alors il sera accédé comme un objet externe et son utilisation ne sera pas tracé dans le graphe et dans les logs d’événements du pipeline DLT
- Syntaxe pour accéder à un objet au sein du même pipeline DLT:
dlt.read(<object>)oudlt.read_stream(<object>)en Python etLIVE.<object>ouSTREAM(LIVE.<object>)en SQL.
- Syntaxe pour accéder à un objet au sein du même pipeline DLT:
Concernant la gestion des données associées à un pipeline DLT (maintenance) :
- Le framework DLT exécute une maintenance automatique de chaque objet (table Delta) mise à jour dans un délai de 24h après la dernière exécution d’un pipeline DLT.
- Par défaut, le système exécute une opération complète OPTIMIZE, suivi d’une opération de VACUUM
- Si vous ne souhaitez pas qu’une table Delta soit automatisée par défaut, il faut utiliser la propriété
pipelines.autoOptimize.managed = falselors de la définition de l’objet (TBLPROPERTIES).
- Lorsque vous supprimez le pipeline DLT, l’ensemble des objets définis dans le pipeline DLT et se trouvant dans le schéma cible sera supprimé automatiquement et les tables Delta interne seront supprimées lors de la maintenance automatique (dans un délai de 24h après la dernière action sur le pipeline DLT).
Limitations :
- Il n’est pas possible de mixer l’utilisation de Hive Metastore avec la solution Unity Catalog ou de faire le changement entre les deux metastores pour la cible du pipeline DLT après sa création.
- Toutes les tables créées et mises à jour par un pipeline DLT sont des tables Delta
- Les objets gérés par le framework DLT ne peuvent être définis qu’une seule fois, cela signifie qu’ils ne peuvent être la cible que dans un seul pipeline DLT uniquement (impossible de définir le même objet dans le même schéma cible dans deux pipelines DLT différents)
- Un Workspace Databricks est limité à 100 mises à jours de pipeline DLT
Fonctionnement avec Unity Catalog
Synthèse
Afin de pouvoir utiliser Unity Catalog, il faut préciser lors de la création du pipeline DLT que l’on souhaite que la destination soit le metastore de la solution Unity Catalog ainsi que le catalogue et le schéma cible à utiliser.
Il n’est pas possible d’utiliser la notation recommandée des “trois namespaces” catalogue.schema.objet pour accéder à un objet géré par le framework DLT.
Les objets sont définis uniquement par leur nom et c’est la définition du catalogue et du schéma cible au niveau du pipeline DLT qui permet de définir où seront créés les objets.
Note : il est possible d’accéder en lecture aux objets non gérés par le framework DLT en utilisant la syntaxe spark classique (spark.table("catalogue.schema.objet"))
Afin de pouvoir utiliser Unity Catalog avec Delta Live Tables, il faut avoir les droits suivants pour le propriétaire du pipeline DLT :
- Vous devez avoir le droit “USE CATALOG” sur le catalogue cible
- Vous devez avoir le droit “USE SCHEMA” sur le schéma cible
- Vous devez avoir le droit “CREATE MATERIALIZED VIEW” dans le schéma cible pour pouvoir créer des objets “Materialized View”.
- Vous devez avoir le droit “CREATE TABLE” dans le schéma cible pour pouvoir créer des objets “Streaming table”
Conseil concernant l’ingestion des fichiers :
- Lorsque l’on souhaite récupérer des informations (métadonnées) concernant les fichiers ingérés, il n’est pas possible d’utiliser la fonction
input_file_namequi n’est pas supportée par Unity Catalog- Il faut utiliser la colonne
_metadataqui permet de récupérer les informations nécessaire, comme par exemple le nom du fichier_metadata.file_name - Vous trouverez la liste des informations disponible dans la colonne
_metadatasur la documentation officielle.
- Il faut utiliser la colonne
Concernant la gestion des objets par le framework DLT (lors de l’exécution du pipeline DLT)
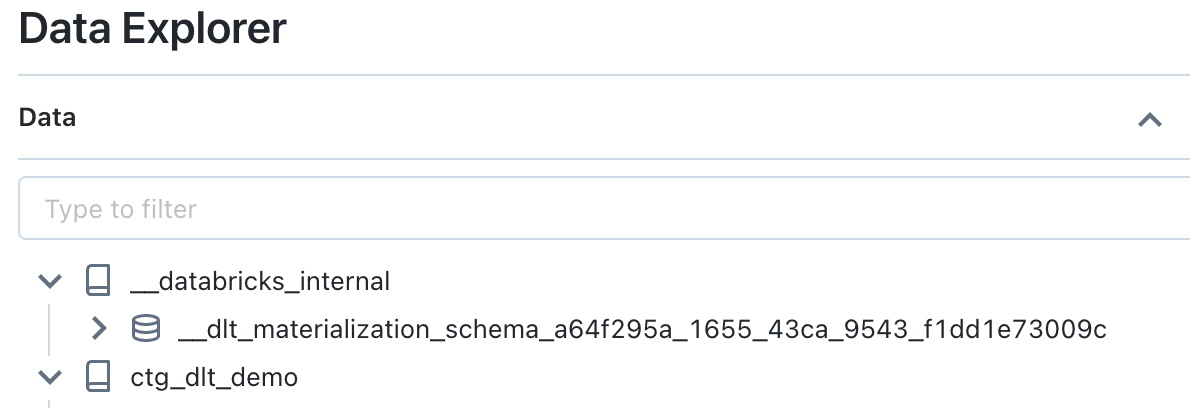
En réalité, lorsque l’on défini un objet avec le framework DLT, un objet va être créé dans le schéma cible indiqué au niveau du pipeline DLT (avec un type spécifique qui ne sera pas directement une table Delta) et une table Delta va être créée dans un schéma interne (géré par le système et non accessible par défaut aux utilisateurs) pour gérer le stockage des données de l’objet défini avec le framework DLT.
Le schéma interne se trouve dans le catalogue nommé __databricks__internal et dont le propriétaire est System.
Le schéma est nommé par défaut de la manière suivante : __dlt_materialization_schema_<pipeline_id>.
Dans ce schéma, se trouvera toutes les tables Delta dont le stockage est géré directement par le framework DLT (le propriétaire des tables Delta est celui du pipeline DLT) ainsi que la table Delta __event_log qui contiendra l’ensemble des logs d’événements des exécutions du pipeline DLT.
En prenant l’exemple de la définition d’un objet “Streaming Table” dans le schéma “ctg.sch” dans un pipeline DLT dont l’identifiant est “0000”, la gestion des données se fera de la manière suivante :
- Création d’une table Delta (avec un identifiant unique) dans un schéma interne géré par le système et nommé
__databricks__internal.__dlt_materialization_schema_0000- Avec sous répertoire (au niveau du stockage des données Delta)
_dlt_metadatacontenant un répertoirecheckpointspermettant de gérer les informations nécessaires à la gestion de l’ingestion des données en streaming
- Avec sous répertoire (au niveau du stockage des données Delta)
- Création d’un objet de type “STREAMING_TABLE” dans le schéma “ctg.sch” qui fait référence à la table Delta créée dans le schéma interne
__databricks__internal.__dlt_materialization_schema_0000- Cela permet d’accéder aux données de la table Delta interne avec certaines contraintes
En prenant l’exemple de la définition d’un objet “Materialized View” dans le schéma “ctg.sch” dans un pipeline DLT dont l’identifiant est “0000”, la gestion des données se fera de la manière suivante :
- Création d’une table Delta (avec un identifiant unique) dans un schéma interne géré par le système et nommé
__databricks__internal.__dlt_materialization_schema_0000- Avec un sous répertoire (au niveau du stockage des données Delta)
_dlt_metadatacontenant un répertoire_enzyme_logpour les informations nécessaires au Projet Enzyme afin de gérer le rafraîchissement des données de l’objet
- Avec un sous répertoire (au niveau du stockage des données Delta)
- Création d’un objet de type “MATERIALIZED_VIEW” dans le schéma “ctg.sch” qui fait référence à la table Delta créée dans le schéma interne
__databricks__internal.__dlt_materialization_schema_0000- Cela permet d’accéder aux données de la table Delta interne avec certaines contraintes
Note : L’objet “View” ne nécessite pas de création d’objet dans le schéma cible ou dans le schéma interne
Limitations
Il est aussi possible de profiter de la fonctionnalité de Data Lineage de la solution Unity Catalog avec les limitations suivantes :
- Il n’y a pas la trace des objets sources qui ne sont pas définis dans un pipeline DLT par conséquent la vision du lineage est incomplet lorsque le pipeline DLT ne contient pas l’ensemble des éléments.
- Par exemple, si il y a une source de données de type référentiel qui est utilisée comme source d’un objet “Materialized View”, le lineage n’aura pas l’information de cette source
- Le lineage ne prend pas en compte les vues temporaires et cela peut empêcher de faire le lien entre les sources de la vue et l’objet cible
Limitations (non exhaustive) lors de l’utilisation d’Unity Catalog avec Delta Live Table :
- Il n’est pas possible de modifier le propriétaire d’un pipeline utilisant Unity Catalog
- Les objets sont gérés/stockés uniquement dans le stockage par défaut du Metastore de Unity Catalog, il n’est pas possible de définir un autre chemin (managé ou externe)
- Il n’est pas possible d’utiliser le Delta Sharing avec les objets gérés par le framework DLT.
- La lecture des logs des événements des pipelines DLT ne peut se faire que par pipeline DLT
- L’accès aux données de certains objets ne peut se faire qu’en utilisant un SQL Warehouse (Pro ou Serverless) ou un Cluster (Shared)
Préparation de l’environnement
Contexte
Pré-requis :
- Création du groupe
grp_demo - Création de l’utilisateur
john.do.dbx@gmail.comet ajout de l’utilisateur dans le groupegrp_demo - Création d’un SQL Warehouse et donnez le droit d’utilisation au groupe
grp_demo - Existence d’un Metastore nommé
metastore-sandboxavec le Storage Credential nommésc-metastore-sandboxpermettant de stocker les données par défaut dans la ressource AWS S3 nommées3-dbx-metastore-uc - Ajout du droit de création d’un catalogue sur le Metastore Unity Catalog et du droit d’accès aux fichiers
1GRANT CREATE CATALOG on METASTORE to grp_demo;
2GRANT SELECT ON ANY FILE TO grp_demo;
Afin de faciliter la réalisation des exemples, nous allons utiliser la liste suivante de variable d’environnement :
1# Create an alias to use the tool curl with .netrc file
2alias dbx-api='curl --netrc-file ~/.databricks/.netrc'
3
4# Create an environment variable with Databricks API URL
5export DBX_API_URL="<Workspace Databricks AWS URL>"
6
7# Init local variables
8export LOC_PATH_SCRIPT="<Local Path for the folder with the Python script>"
9export LOC_PATH_DATA="<Local Path for the folder with the CSV files>"
10# Name for DLT Script (Python)
11export LOC_SCRIPT_DLT="dlt_pipeline.py"
12# List CSV files for the first execution
13export LOC_SCRIPT_DATA_1=(ref_products_20230501.csv ref_clients_20230501.csv fct_transactions_20230501.csv)
14# List CSV files for the second execution
15export LOC_SCRIPT_DATA_2=(ref_clients_20230601.csv fct_transactions_20230601.csv)
16
17# Init Databricks variables (Workspace)
18# Path to store the CSV files
19export DBX_PATH_DATA="dbfs:/mnt/dlt_demo/data"
20# Name for the DLT pipeline
21export DBX_DLT_PIPELINE_NAME="DLT_pipeline_demo"
22# DLT pipeline Target Catalog
23export DBX_UC_CATALOG="CTG_DLT_DEMO"
24# DLT pipeline Target Schema
25export DBX_UC_SCHEMA="SCH_DLT_DEMO"
26# Path to store the DLT Script (Python)
27export DBX_USER_NBK_PATH="/Users/john.do.dbx@gmail.com"
28
29# Init Pipeline variable
30export DBX_DLT_PIPELINE_ID=""
Schématisation de l’environnement
Schématisation du pipeline DLT que nous allons mettre en place :
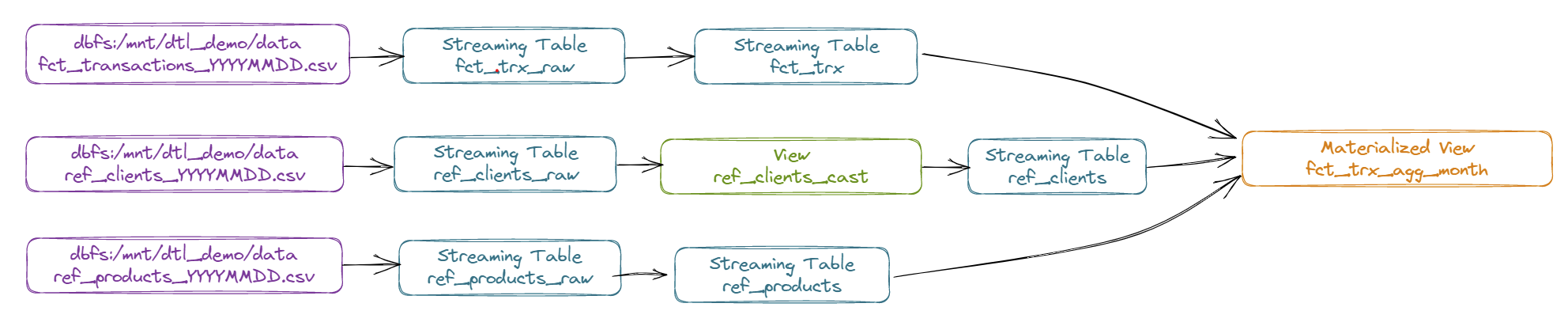
Détail du pipeline DLT :
- Récupération des données du référentiel Produit en streaming à partir de fichier CSV (ref_products_YYYYMMDD.csv) vers un objet “Streaming Table” nommé “REF_PRODUCTS_RAW”
- Alimentation en streaming des données de l’objet “REF_PRODUCTS_RAW” vers un objet “Streaming Table” nommé “REF_PRODUCTS”
- Récupération des données du référentiel Client en streaming à partir de fichier CSV (ref_clients_YYYYMMDD.csv) vers un objet “Streaming Table” nommé “REF_CLIENTS_RAW” (avec l’activation du Change Data Feed)
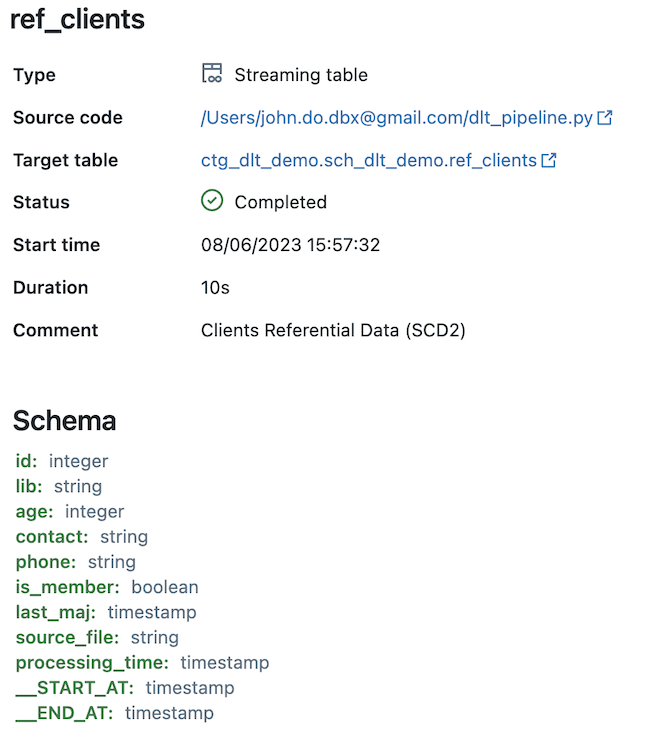
- Alimentation en streaming des données de l’objet “REF_PRODUCTS_RAW” vers un objet “Streaming Table” utilisant la fonctionnalité SCD Type 2 et nommé “REF_CLIENTS”
- En utilisant une vue nommé “REF_CLIENTS_CAST” pour transformer les données en amont
- Récupération des données de transactions en streaming à partir de fichier CSV (fct_transactions_YYYYMMDD.csv) vers un objet “Streaming Table” nommé “FCT_TRX_RAW”
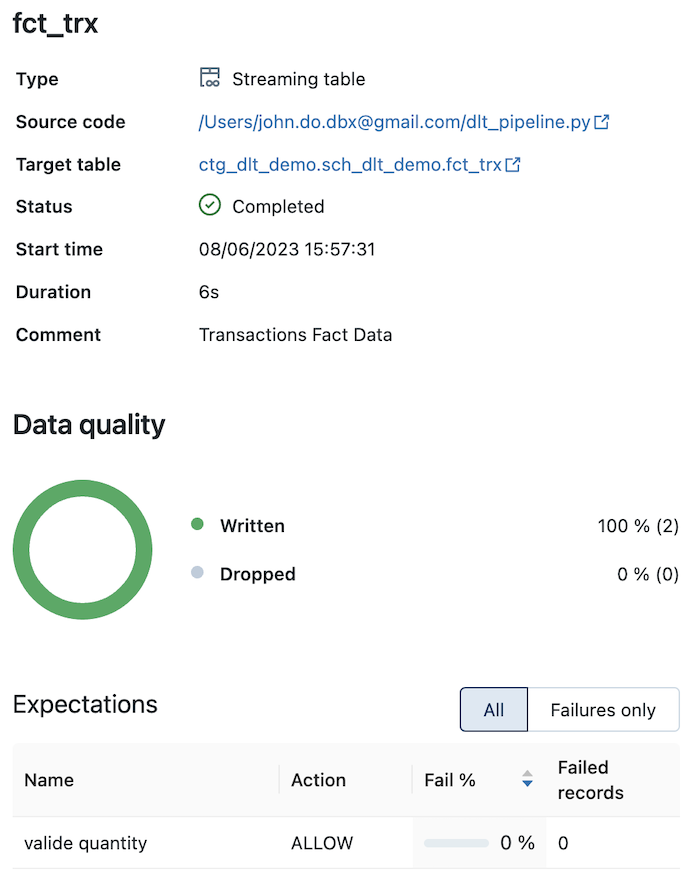
- Alimentation d’un objet “Streaming Table” nommé “FCT_TRX” à partir de l’objet “FCT_TRX_RAW” en appliquant une contrainte sur l’information “quantity” qui ne doit pas être égale à 0.
- Alimentation d’un objet “Materialized View” nommé “FCT_TRX_AGG_MONTH” à partir des objets “FCT_TRX”, “REF_CLIENTS” et “REF_PRODUCTS” pour agréger les ventes par mois, clients et produits
Mise en place d’un jeu de données
Le jeu de données sera constitué de deux lots afin de réaliser deux exécutions et mettre en pratique le rafraîchissement des données.
Jeu de données pour le lot n°1 (1ère exécution du pipeline DLT) :
Contenu du fichier ref_clients_20230501.csv :
1id,lib,age,contact,phone,is_member,last_maj
21,Maxence,23,max1235@ter.tt,+33232301123,No,2023-01-01 11:01:02
32,Bruce,26,br_br@ter.tt,+33230033155,Yes,2023-01-01 13:01:00
43,Charline,40,ccccharline@ter.tt,+33891234192,Yes,2023-03-02 09:00:00
Contenu du fichier ref_products_20230501.csv :
1id,lib,brand,os,last_maj
21,Pixel 7 Pro,Google,Android,2023-01-01 09:00:00
32,Iphone 14,Apple,IOS,2023-01-01 09:00:00
43,Galaxy S23,Samsung,Android,2023-01-01 09:00:00
Contenu du fichier fct_transactions_20230501.csv :
1id_trx,ts_trx,id_product,id_shop,id_client,quantity
21,2023-04-01 09:00:00,1,2,1,1
32,2023-04-01 11:00:00,1,1,1,3
Jeu de données pour le lot n°2 (2ème exécution du pipeline DLT) :
Contenu du fichier ref_clients_20230601.csv :
1id,lib,age,contact,phone,is_member,last_maj
22,Bruce,26,br_br@ter.tt,+33990033100,Yes,2023-04-01 12:00:00
Contenu du fichier fct_transactions_20230601.csv :
1id_trx,ts_trx,id_product,id_shop,id_client,quantity
23,2023-04-03 14:00:00,1,2,1,1
34,2023-04-05 08:00:00,3,1,2,9
45,2023-04-06 10:00:00,1,2,1,3
56,2023-04-06 12:00:00,2,2,1,1
67,2023-01-01 13:00:00,1,2,1,0
78,2023-04-10 18:30:00,2,1,2,11
89,2023-04-10 18:30:00,3,1,2,2
Mise en place des objets dans le Metastore Unity Catalog
Étapes pour la création des objets nécessaires :
- Création d’un catalogue nommé
ctg_dlt_demo - Création d’un schéma nommé
sch_dlt_demo
1-- 1. Create Catalog
2CREATE CATALOG IF NOT EXISTS ctg_dlt_demo
3COMMENT 'Catalog to store the dlt demo objects';
4
5-- 2. Create Schema
6CREATE SCHEMA IF NOT EXISTS ctg_dlt_demo.sch_dlt_demo
7COMMENT 'Schema to store the dlt demo objects';
Création du script python contenant la définition des objets pour le framework DLT
Le script est nommé dlt_pipeline.py et sera copié dans le Workspace Databricks pour pouvoir être utilisé par le pipeline DLT.
Le script Python contient le code suivant :
1"""Pipeline DLT demo"""
2import dlt
3from pyspark.sql.functions import col, current_timestamp, expr, sum
4
5# Folder to store data for the demo
6PATH_DATA = "dbfs:/mnt/dlt_demo/data"
7
8
9###################
10## Products Data ##
11###################
12
13# Create the streaming table named REF_PRODUCTS_RAW
14@dlt.table(
15 name="REF_PRODUCTS_RAW",
16 comment="Raw Products Referential Data",
17 table_properties={"quality" : "bronze"},
18 temporary=False)
19def get_products_raw():
20 return spark.readStream.format("cloudFiles") \
21 .option("cloudFiles.format", "csv") \
22 .option("delimiter",",") \
23 .option("header","true") \
24 .load(PATH_DATA+"/ref_products_*.csv") \
25 .select("*"
26 ,col("_metadata.file_name").alias("source_file")
27 ,current_timestamp().alias("processing_time"))
28
29# Create the streaming table named REF_PRODUCTS
30@dlt.table(
31 name="REF_PRODUCTS",
32 comment="Products Referential Data",
33 table_properties={"quality" : "silver"},
34 temporary=False)
35def get_products():
36 return dlt.read_stream("REF_PRODUCTS_RAW") \
37 .where("_rescued_data is null") \
38 .select(col("id").cast("INT")
39 ,col("lib")
40 ,col("brand")
41 ,col("os")
42 ,col("last_maj").cast("TIMESTAMP")
43 ,col("source_file")
44 ,col("processing_time"))
45
46
47###################
48## Clients Data ##
49##################
50
51# Create the streaming table named REF_CLIENTS_RAW
52@dlt.table(
53 name="REF_CLIENTS_RAW",
54 comment="Raw Clients Referential Data",
55 table_properties={"quality" : "bronze", "delta.enableChangeDataFeed" : "true"},
56 temporary=False)
57def get_products_raw():
58 return spark.readStream.format("cloudFiles") \
59 .option("cloudFiles.format", "csv") \
60 .option("delimiter",",") \
61 .option("header","true") \
62 .load(PATH_DATA+"/ref_clients_*.csv") \
63 .select("*"
64 ,col("_metadata.file_name").alias("source_file")
65 ,current_timestamp().alias("processing_time"))
66
67# Create the temporary view named REF_CLIENTS_RAW_CAST
68@dlt.view(
69 name="REF_CLIENTS_RAW_CAST"
70 ,comment="Temp view for Clients Raw Casting")
71def view_clients_cast():
72 return dlt.read_stream("REF_CLIENTS_RAW") \
73 .select(expr("cast(id as INT) as id")
74 ,col("lib")
75 ,expr("cast(age as INT) as age")
76 ,col("contact")
77 ,col("phone")
78 ,expr("(is_member = 'Yes') as is_member")
79 ,expr("cast(last_maj as timestamp) as last_maj")
80 ,col("source_file")
81 ,col("processing_time"))
82
83# Create the streaming table named REF_CLIENTS (and using SCD Type 2 management)
84dlt.create_streaming_table(
85 name = "REF_CLIENTS",
86 comment = "Clients Referential Data (SCD2)"
87)
88
89# Apply modification (for SCD Type 2 management) based on the temporary view
90dlt.apply_changes(target = "REF_CLIENTS",
91 source = "REF_CLIENTS_RAW_CAST",
92 keys = ["id"],
93 sequence_by = col("last_maj"),
94 stored_as_scd_type = 2)
95
96
97#######################
98## Transactions Data ##
99#######################
100
101# Create the streaming table named FCT_TRX_RAW
102@dlt.table(
103 name="FCT_TRX_RAW",
104 comment="Raw Transactions Fact Data",
105 table_properties={"quality" : "bronze"},
106 partition_cols=["dt_tech"],
107 temporary=False)
108def get_transactions_raw():
109 return spark.readStream.format("cloudFiles") \
110 .option("cloudFiles.format", "csv") \
111 .option("delimiter",",") \
112 .option("header","true") \
113 .load(PATH_DATA+"/fct_transactions_*.csv") \
114 .select("*"
115 ,col("_metadata.file_name").alias("source_file")
116 ,current_timestamp().alias("processing_time")
117 ,expr("current_date() as dt_tech"))\
118
119
120# Create the streaming table named FCT_TRX (with expectation)
121@dlt.table(
122 name="FCT_TRX",
123 comment="Transactions Fact Data",
124 table_properties={"quality" : "silver"},
125 partition_cols=["dt_trx"],
126 temporary=False)
127@dlt.expect("valide quantity","quantity <> 0")
128def get_transactions():
129 return dlt.read_stream("FCT_TRX_RAW") \
130 .where("_rescued_data IS NULL") \
131 .select(expr("cast(id_trx as INT) as id_trx")
132 ,expr("cast(ts_trx as timestamp) as ts_trx")
133 ,expr("cast(id_product as INT) as id_product")
134 ,expr("cast(id_shop as INT) as id_shop")
135 ,expr("cast(id_client as INT) as id_client")
136 ,expr("cast(quantity as DOUBLE) as quantity")
137 ,col("source_file")
138 ,col("processing_time")
139 ,col("dt_tech")) \
140 .withColumn("_invalid_data",expr("not(coalesce(quantity,0) <> 0)")) \
141 .withColumn("dt_trx",expr("cast(ts_trx as date)"))
142
143
144# Create the Materialized View named FCT_TRX_AGG_MONTH
145@dlt.table(
146 name="FCT_TRX_AGG_MONTH",
147 comment="Transactions Fact Data Aggregate Month",
148 table_properties={"quality" : "gold"},
149 partition_cols=["dt_month"],
150 temporary=False)
151def get_transactions_agg_month():
152 data_fct = dlt.read("FCT_TRX").where("not(_invalid_data)")
153 data_ref_products = dlt.read("REF_PRODUCTS")
154 data_ref_clients = dlt.read("REF_CLIENTS").where("__END_AT IS NULL")
155 return data_fct.alias("fct").join(data_ref_products.alias("rp"), data_fct.id_product == data_ref_products.id, how="inner") \
156 .join(data_ref_clients.alias("rc"),data_fct.id_client == data_ref_clients.id, how="inner") \
157 .withColumn("dt_month",expr("cast(substring(cast(fct.dt_trx as STRING),0,7)||'-01' as date)")) \
158 .groupBy("dt_month","rc.lib","rc.contact","rp.brand") \
159 .agg(sum("fct.quantity").alias("sum_quantity")) \
160 .select(col("dt_month")
161 ,col("rc.lib")
162 ,col("rc.contact")
163 ,col("rp.brand")
164 ,col("sum_quantity").alias("quantity")
165 ,expr("current_timestamp() as ts_tech"))
Création d’un Pipeline DLT
Pour créer le pipeline DLT, nous allons suivre les étapes suivantes :
- Création d’un répertoire dans le répertoire DBFS pour stocker les fichiers CSV
- Copie du script Python sur le Workspace Databricks
- Création du pipeline DLT (en prenant comme source le script Python copié sur le Workspace Databricks)
- Récupération de l’identifiant du pipeline DLT dans une variable d’environnement nommée “DBX_DLT_PIPELINE_NAME”
Utilisation de Databricks REST API :
1# 1. Create the directory to store CSV files (on the DBFS)
2dbx-api -X POST ${DBX_API_URL}/api/2.0/dbfs/mkdirs -H 'Content-Type: application/json' -d "{
3 \"path\": \"${DBX_PATH_DATA}\"
4}"
5
6# 2. Copy the Python script into the Workspace
7dbx-api -X POST ${DBX_API_URL}/api/2.0/workspace/import -H 'Content-Type: application/json' -d "{
8 \"format\": \"SOURCE\",
9 \"path\": \"${DBX_USER_NBK_PATH}/${LOC_SCRIPT_DLT}\",
10 \"content\" : \"$(base64 -i ${LOC_PATH_SCRIPT}/${LOC_SCRIPT_DLT})\",
11 \"language\": \"PYTHON\",
12 \"overwrite\": \"true\"
13}"
14
15# 3. Create the DLT Pipeline based on the Python script
16dbx-api -X POST ${DBX_API_URL}/api/2.0/pipelines -H 'Content-Type: application/json' -d "
17{
18 \"continuous\": false,
19 \"name\": \"${DBX_DLT_PIPELINE_NAME}\",
20 \"channel\": \"PREVIEW\",
21 \"catalog\": \"${DBX_UC_CATALOG}\",
22 \"target\": \"${DBX_UC_SCHEMA}\",
23 \"development\": true,
24 \"photon\": false,
25 \"edition\": \"ADVANCED\",
26 \"allow_duplicate_names\": \"false\",
27 \"dry_run\": false,
28 \"configuration\": {
29 \"pipelines.clusterShutdown.delay\": \"600s\"
30 },
31 \"clusters\": [
32 {
33 \"label\": \"default\",
34 \"num_workers\": 1
35 }
36 ],
37 \"libraries\": [
38 {
39 \"notebook\": {
40 \"path\": \"${DBX_USER_NBK_PATH}/${LOC_SCRIPT_DLT}\"
41 }
42 }
43 ]
44}"
45
46# 4. Retrieve the Pipeline ID
47export DBX_DLT_PIPELINE_ID=`dbx-api -X GET ${DBX_API_URL}/api/2.0/pipelines | jq -r '.statuses[]|select(.name==$ENV.DBX_DLT_PIPELINE_NAME)|.pipeline_id'`
Exécution et Visualisation d’un pipeline DLT
Exécution du pipeline DLT
Afin de pouvoir réaliser la 1ère exécution du pipeline DLT, il faut réaliser les actions suivantes :
- Copiez les données CSV du lot n°1 dans le répertoire DBFS (sur le Workspace Databricks)
- Exécutez le pipeline DLT
- Récupérez le statut du pipeline DLT
Utilisation de Databricks REST API :
1# 1. Upload CSV Files (for execution)
2for file in ${LOC_SCRIPT_DATA_1}; do
3 dbx-api -X POST ${DBX_API_URL}/api/2.0/dbfs/put -H 'Content-Type: application/json' -d "{
4 \"path\": \"${DBX_PATH_DATA}/${file}\",
5 \"contents\": \"$(base64 -i ${LOC_PATH_DATA}/${file})\",
6 \"overwrite\": \"true\"
7 }"
8done
9
10# 2. Execute the DLT Pipeline
11dbx-api -X POST ${DBX_API_URL}/api/2.0/pipelines/${DBX_DLT_PIPELINE_ID}/updates -H 'Content-Type: application/json' -d "
12{
13 \"full_refresh\": false,
14 \"cause\": \"USER_ACTION\"
15}"
16
17# 3. Retrieve the status of the DLT Pipeline execution
18dbx-api -X GET ${DBX_API_URL}/api/2.0/pipelines/${DBX_DLT_PIPELINE_ID}/events | jq '.events[0]|.details'
Afin de pouvoir réaliser la 2ème exécution du pipeline DLT, il faut réaliser les actions suivantes :
- Copiez les données CSV du lot n°2 dans le répertoire DBFS (sur le Workspace Databricks)
- Exécutez le pipeline DLT
- Récupérez le statut du pipeline DLT
Utilisation de Databricks REST API :
1# 1. Upload CSV Files (for execution)
2for file in ${LOC_SCRIPT_DATA_2}; do
3 dbx-api -X POST ${DBX_API_URL}/api/2.0/dbfs/put -H 'Content-Type: application/json' -d "{
4 \"path\": \"${DBX_PATH_DATA}/${file}\",
5 \"contents\": \"$(base64 -i ${LOC_PATH_DATA}/${file})\",
6 \"overwrite\": \"true\"
7 }"
8done
9
10# 2. Execute the DLT Pipeline
11dbx-api -X POST ${DBX_API_URL}/api/2.0/pipelines/${DBX_DLT_PIPELINE_ID}/updates -H 'Content-Type: application/json' -d "
12{
13 \"full_refresh\": false,
14 \"cause\": \"USER_ACTION\"
15}"
16
17# 3. Retrieve the status of the DLT Pipeline execution
18dbx-api -X GET ${DBX_API_URL}/api/2.0/pipelines/${DBX_DLT_PIPELINE_ID}/events | jq '.events[0]|.details'
Visualisation du pipeline DLT
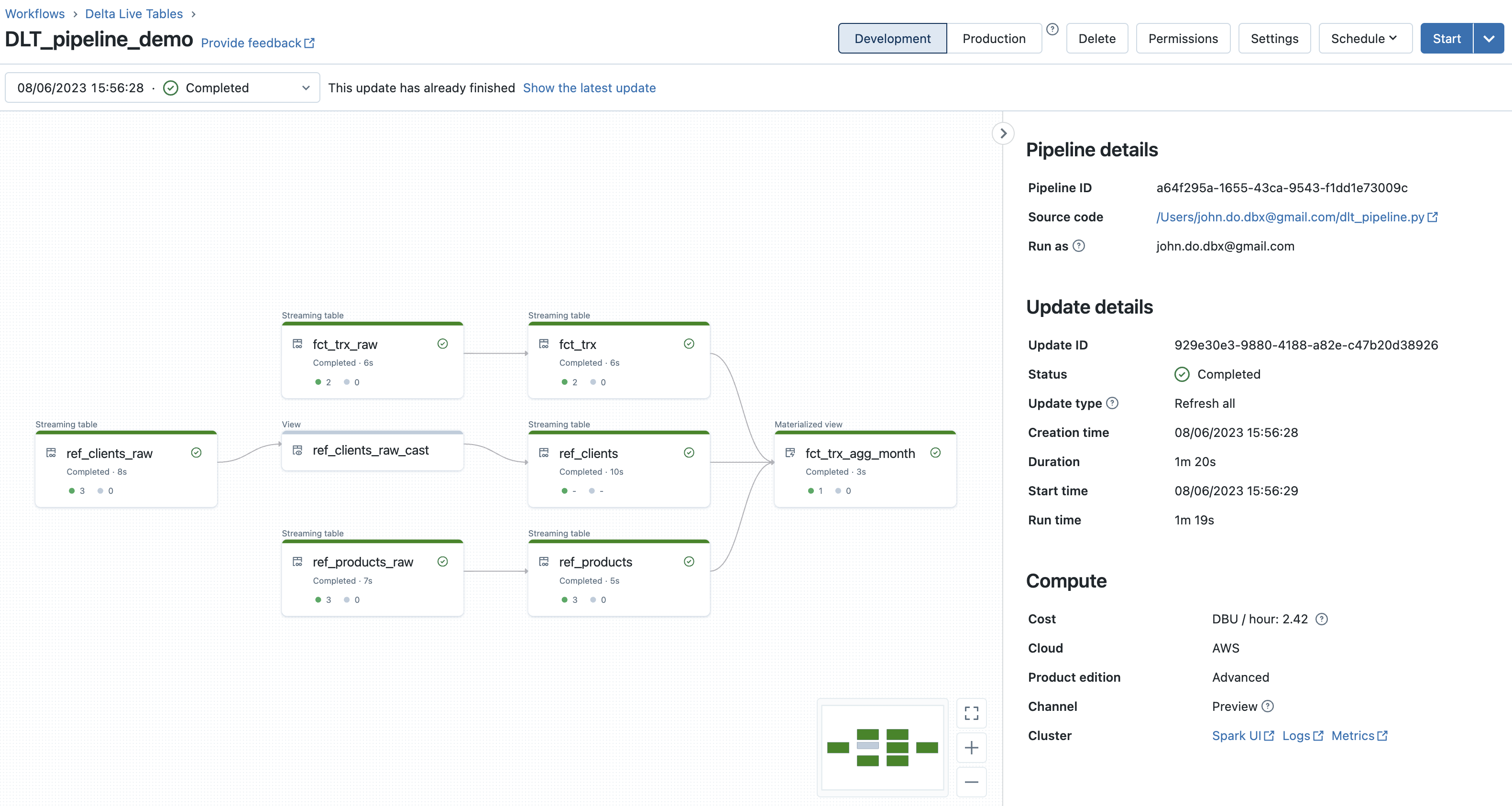
Résultat après la 1ère exécution du pipeline DLT :
Détail de l’objet “FCT_TRX” (avec la contrainte sur l’information “quantity”) :
Détail de l’objet “REF_CLIENTS” (alimenté par le processus SCD de type 2) :
Résultat après la 2ème exécution du pipeline DLT :
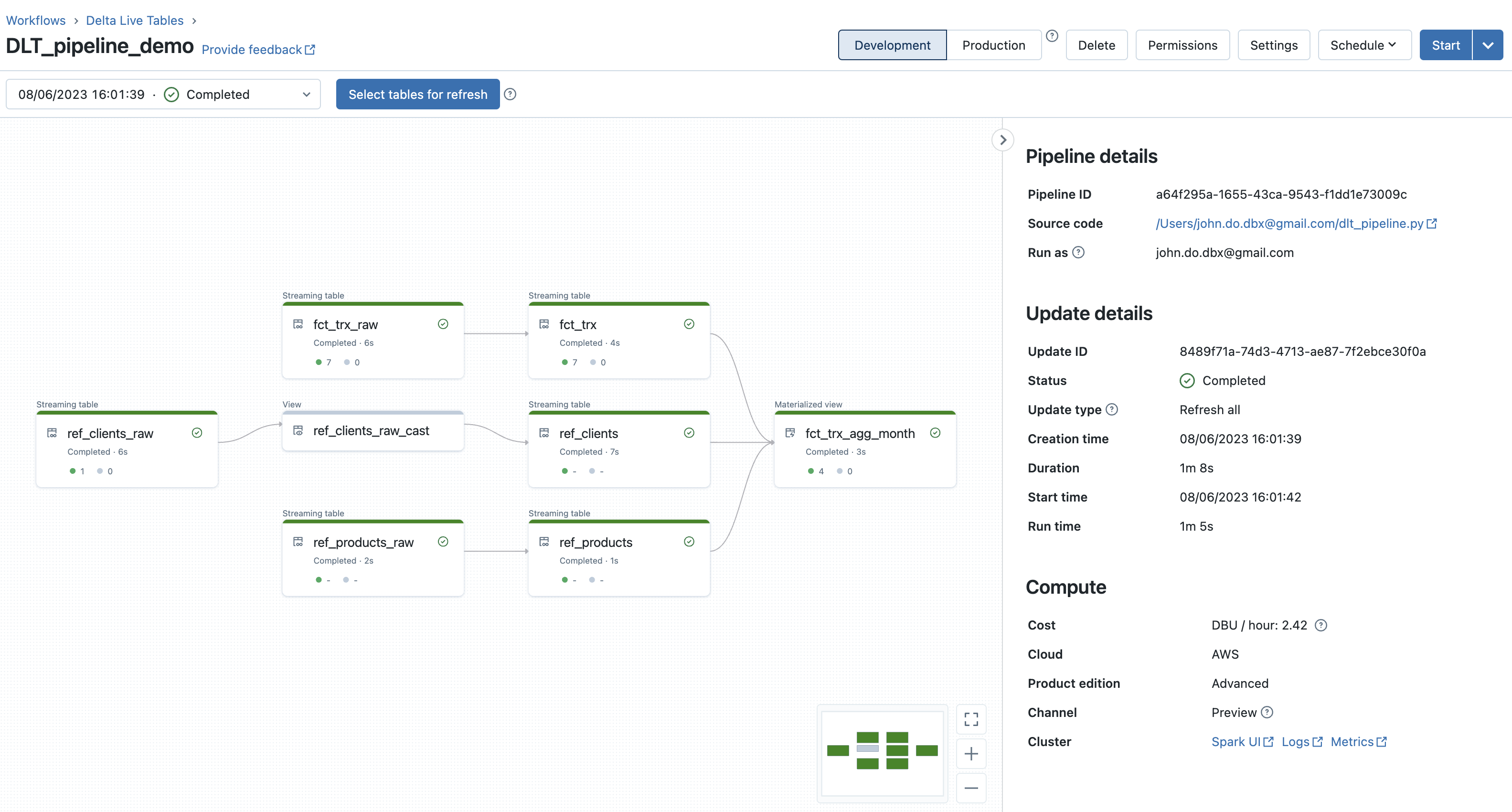
Détail de l’objet “FCT_TRX” (avec la contrainte sur l’information “quantity”) :
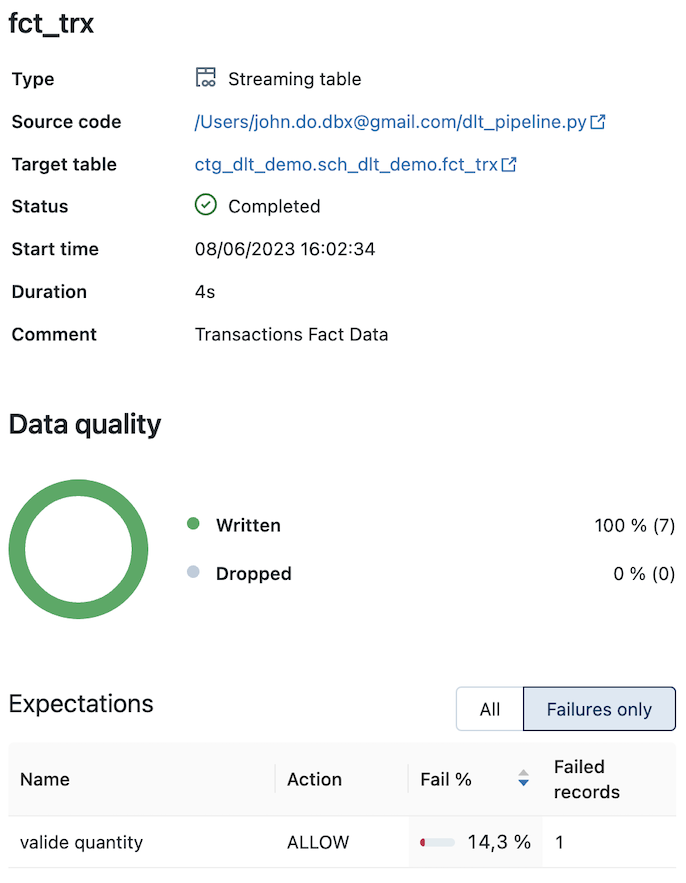
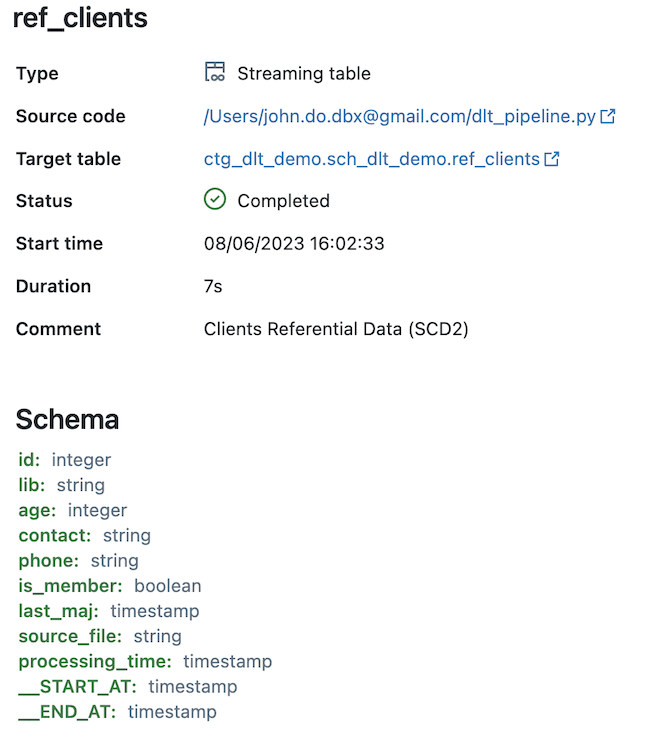
Détail de l’objet “REF_CLIENTS” (alimenté par le processus SCD de type 2) :
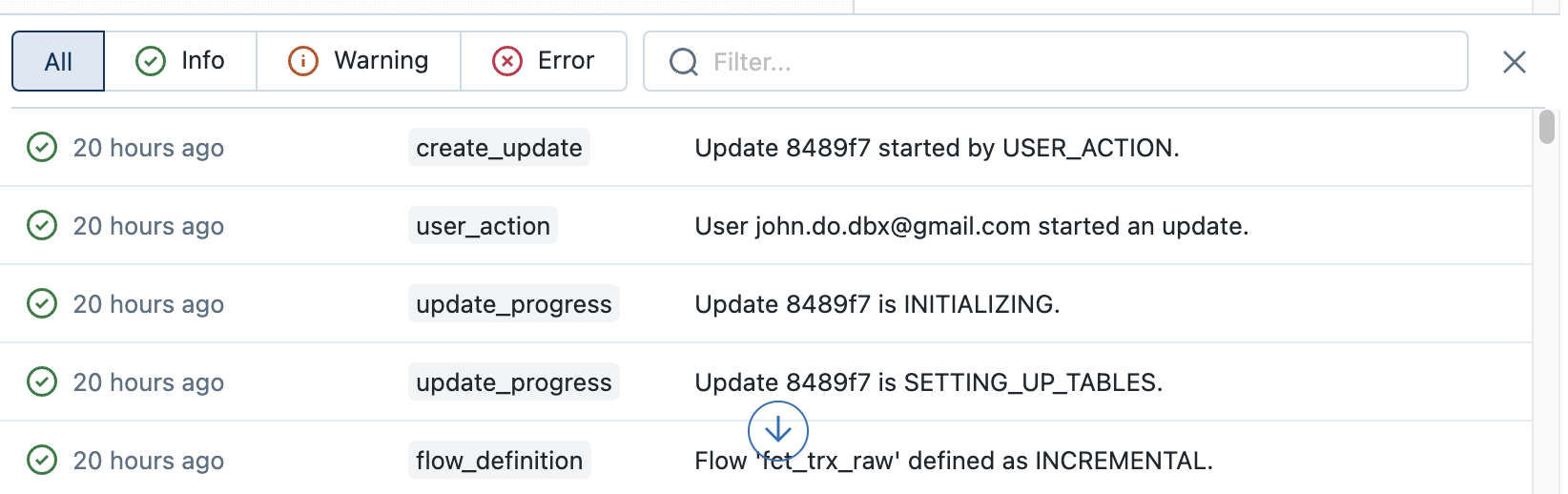
Exemple de l’onglet contenant les logs d’évènements de la 2ème exécution du pipeline DLT:
Remarque :
- Le graphe du pipeline DLT permet de très facilement visualiser le lineage des données ainsi que le nombre d’enregistrement traités (ou supprimés) lors de chaque étape (objet)
- Lorsque nous cliquons sur un objet, nous pouvons avoir des métriques sur l’objet (nombre d’enregistrements écrits et supprimés, nombre d’enregistrements violant une contrainte, schéma de l’objet, date et heure d’exécution, durée, …)
- En bas de l’écran, nous avons accès à l’ensemble des logs d’événements de l’exécution du pipeline DLT et il est possible de les filtrer sur les options “All”, “Info”, “Warning” et “Error” ou sur la description des événements.
- Il est possible de choisir l’exécution que l’on souhaite visualiser en la sélectionnant dans la liste déroulante (par timestamp d’exécution et contenant le dernier statut d’exécution).
Visualisation avec Unity Catalog
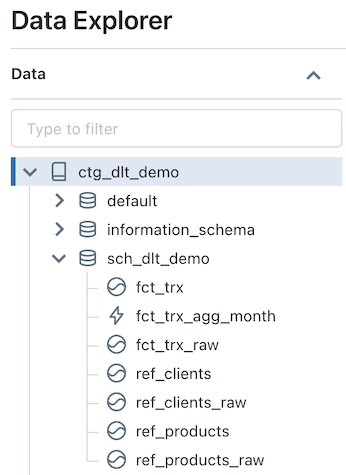
Visualisation des objets du schéma “sch_dlt_demo” dans le catalogue “ctg_dlt_demo” :
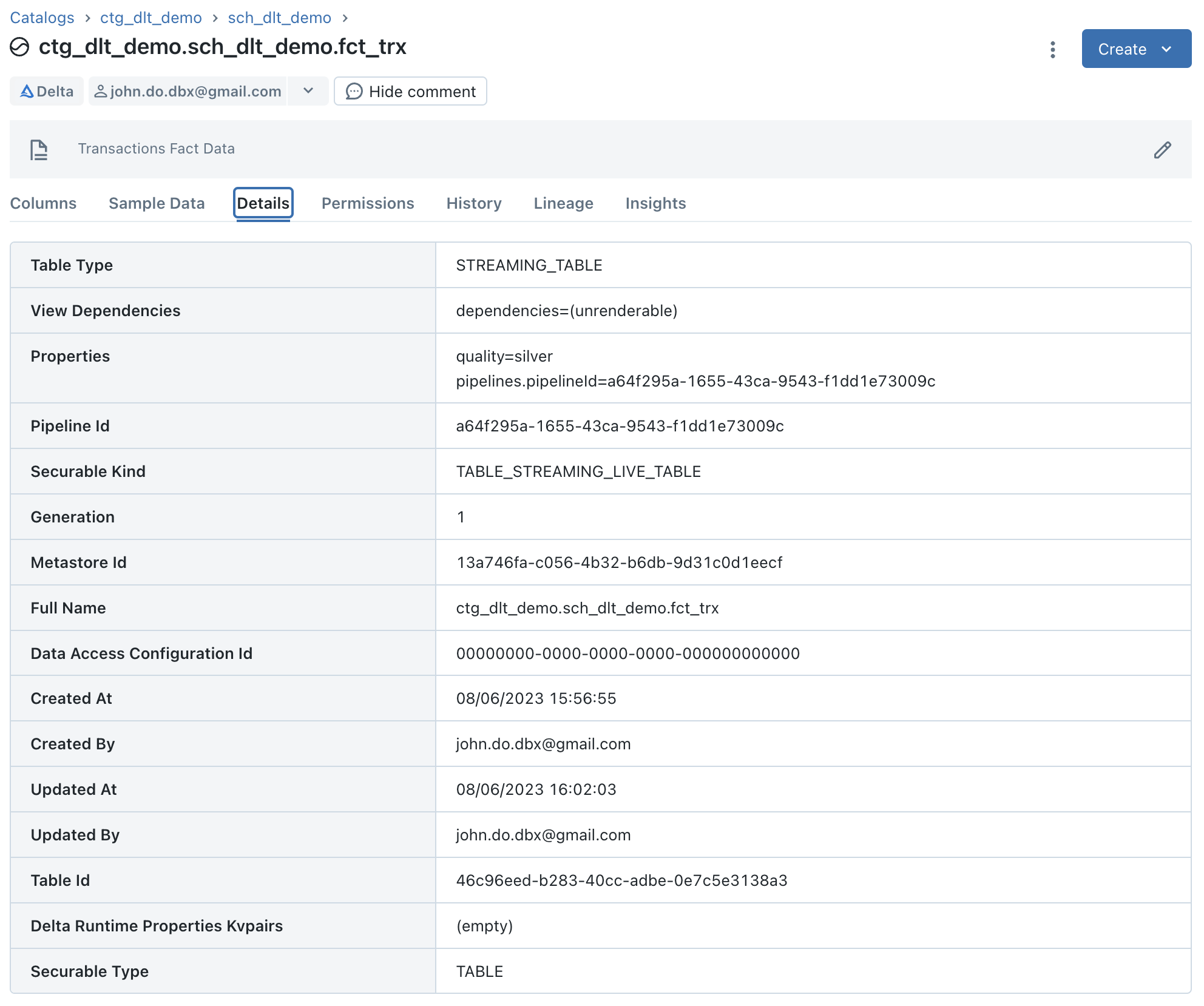
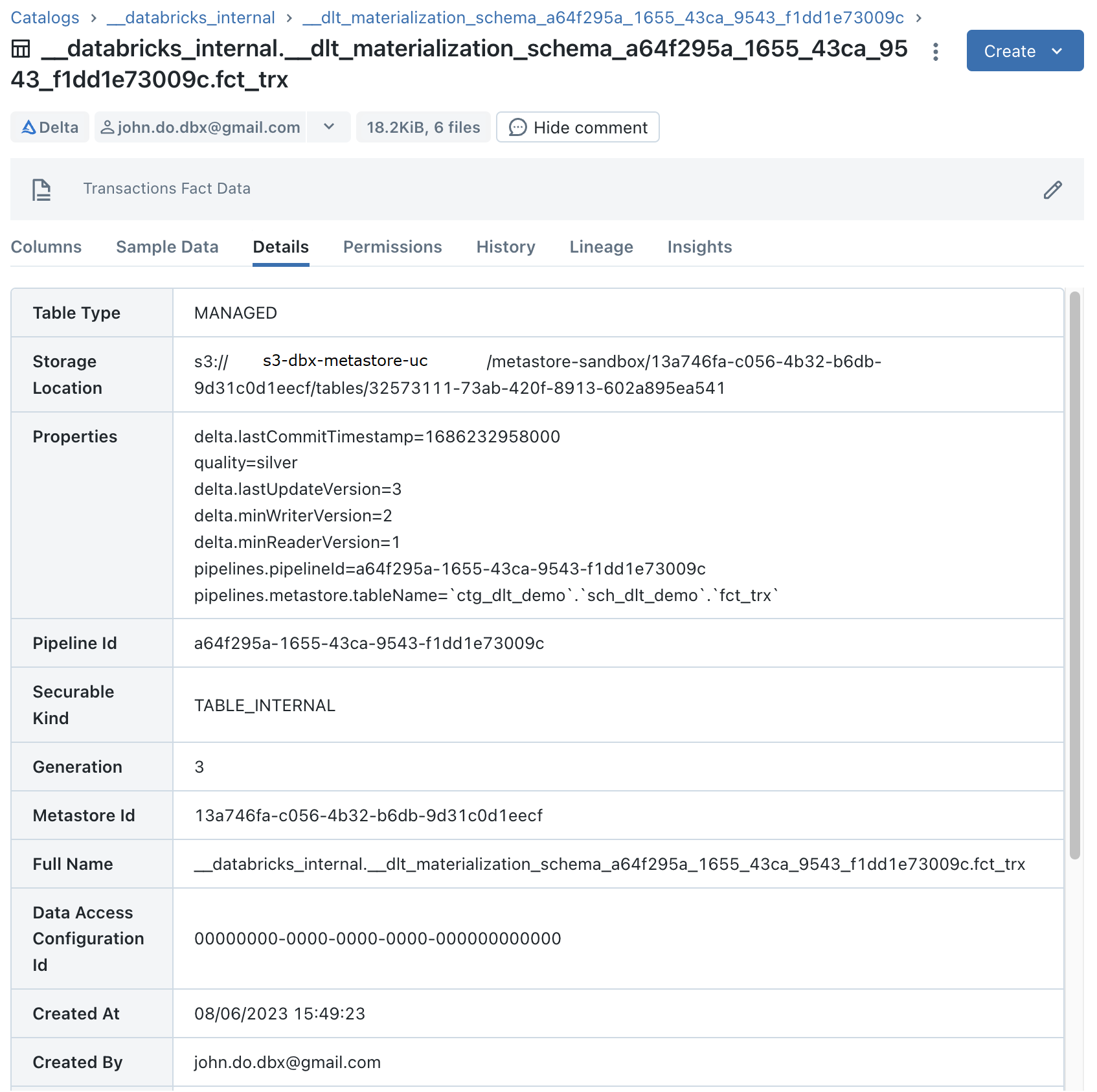
Visualisation des détails pour l’objet “FCT_TRX” qui est un objet “Streaming Table” :
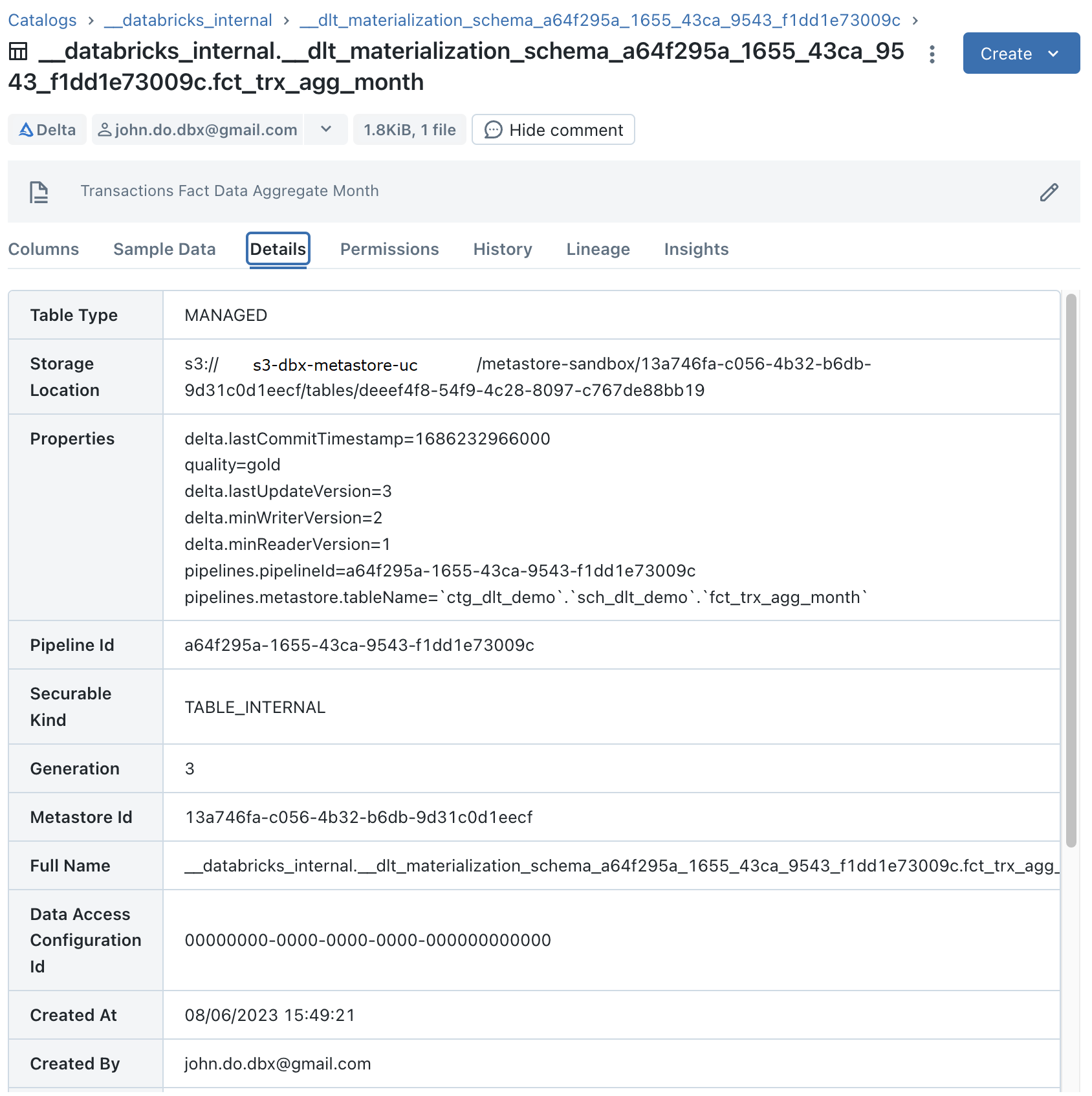
Visualisation des détails pour l’objet “FCT_TRX_AGG_MONTH” qui est un objet “Materialized View” :
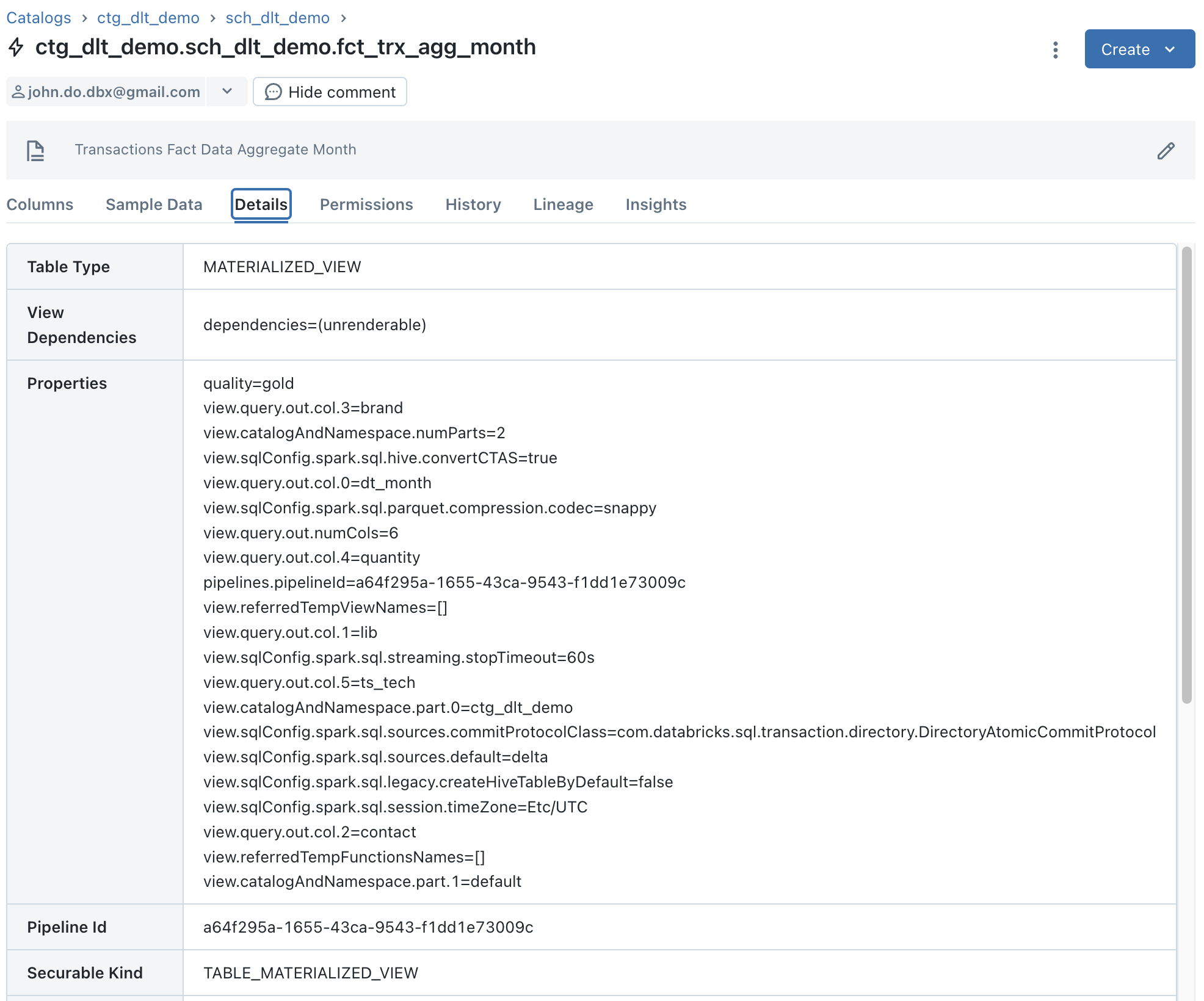
Remarque :
- Nous pouvons voir que l’information “Storage Location” n’existe pas car ce ne sont pas réellement des tables Delta mais cela peut être vu comme des objets logiques.
Concernant le Data Lineage :
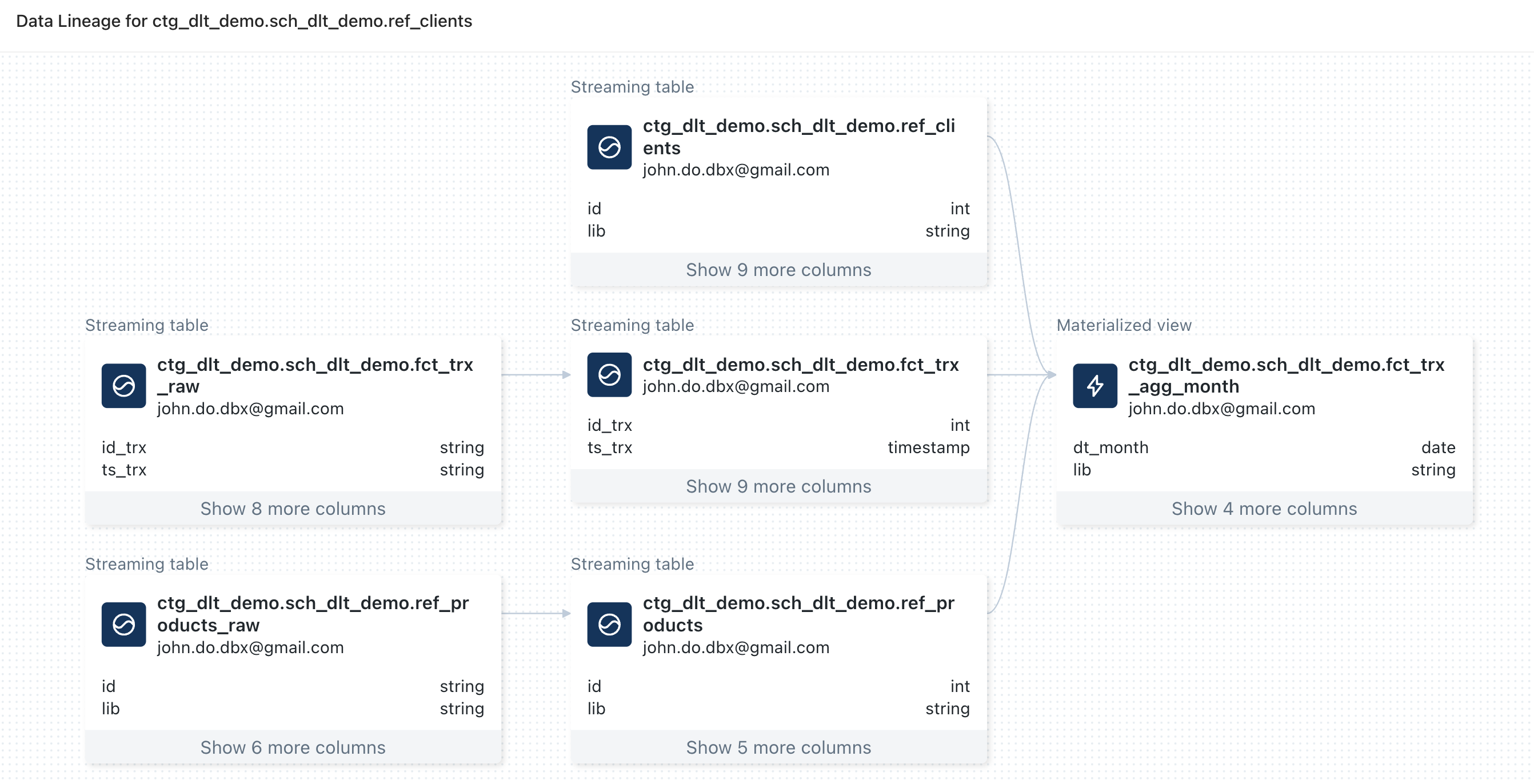
Visualisation du lineage en partant de l’objet “REF_CLIENTS” :
 Remarque :
Remarque :
- Nous pouvons observer qu’il y a des informations pour les objets définis dans le pipeline DLT à l’exception de la source de données de l’objet “REF_CLIENTS” qui se nomme “REF_CLIENTS_RAW”
- Nous pouvons observer qu’il n’y a aucune information sur les sources de données (fichiers CSV)
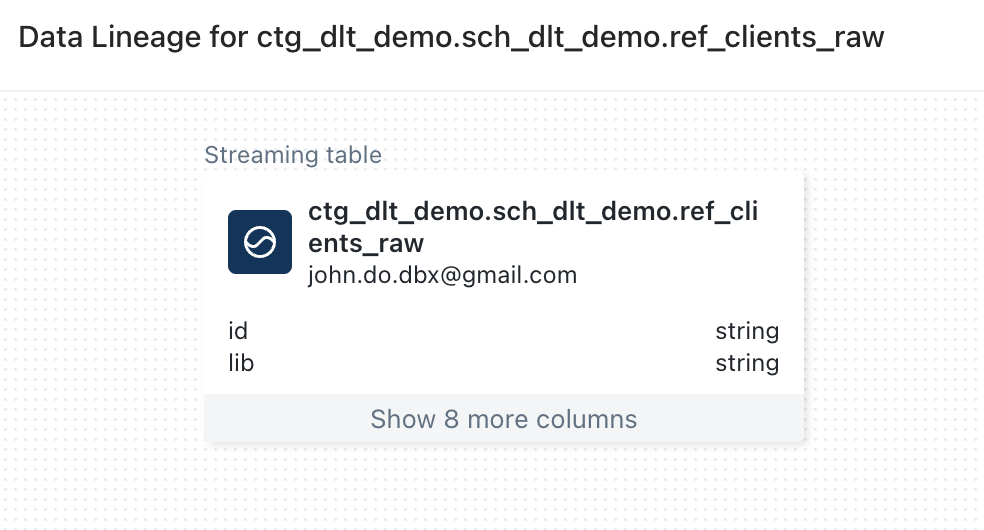
Visualisation du lineage en partant de l’objet “REF_CLIENTS_RAW” :
 Remarque :
Remarque :
- Nous pouvons observer que l’objet “REF_CLIENTS_RAW” n’a aucune information de lineage alors qu’il est la source de l’alimentation de l’objet “REF_CLIENTS” dans le pipeline DLT
Concernant les objets internes : Attention : Pour pouvoir les visualiser, il faut avoir les droits suivants
1GRANT USE_CATALOG ON CATALOG __databricks_internal TO <user or group>;
2GRANT USE_SCHEMA ON SCHEMA __databricks_internal.__dlt_materialization_schema_<pipeline_id> TO <user or group>;
Visualisation du catalogue interne __databricks_internal avec Data Explorer :
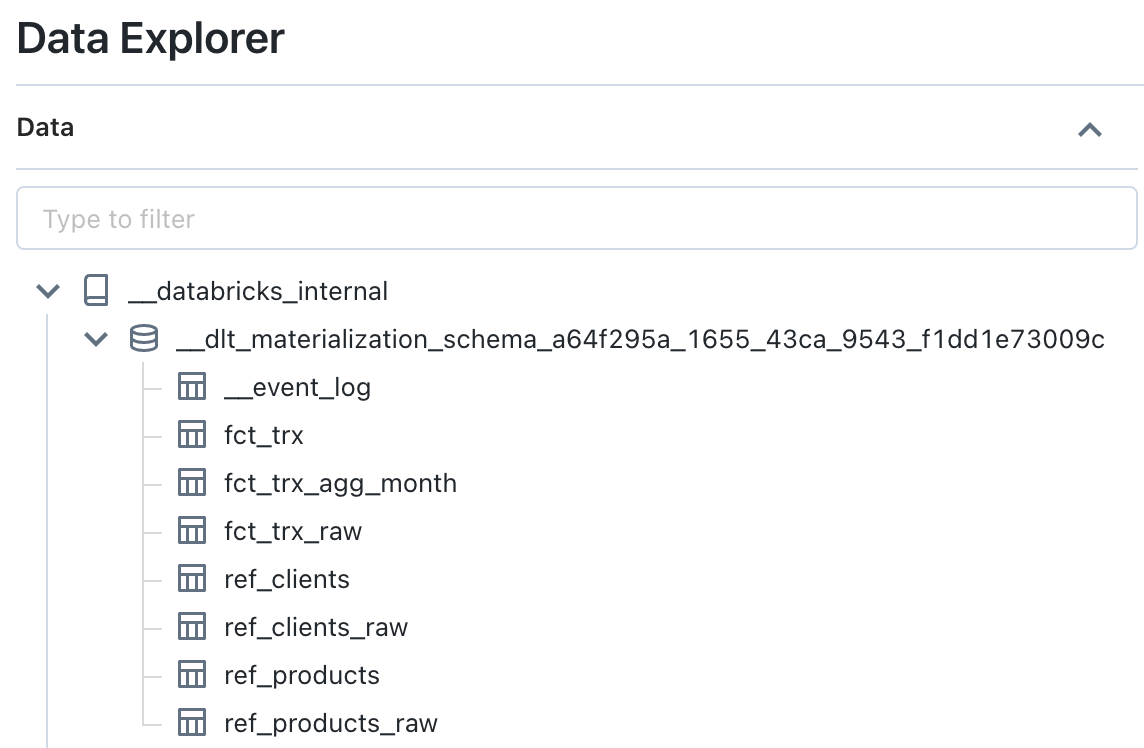
Visualisation des détails pour l’objet interne “FCT_TRX” (qui contient les données d’un objet “Streaming Table”) :
Visualisation des détails pour l’objet “FCT_TRX_AGG_MONTH” (qui contient les données d’un objet “Materialized View”) :
Remarque :
- Nous pouvons observer que ce sont des tables Delta classiques
Monitoring d’un pipeline DLT
Le monitoring d’un pipeline DLT s’appuie sur les logs d’événements liés à l’exécution du pipeline DLT, incluant les logs d’audit, de qualité des données et de lineage. Cela permet d’analyser les exécutions et l’état des pipelines DLT.
L’objet interne __event_log est une table Delta qui contient un sous répertoire nommé _dlt_metadata et contenant un répertoire _autoloader avec les informations permettant de gérer le chargement des données par le système avec Auto Loader.
Il y a quatre méthodes d’accès aux logs des événements concernant l’exécution des pipelines DLT :
- La 1ère méthode consiste à utiliser l’interface utilisateurs du Workspace Databricks
- Cliquez sur l’option “Workflows” dans le menu latéral
- Cliquez sur l’onglet “Delta Live Tables”
- Sélectionnez le pipeline DLT voulu
- Sélectionnez l’exécution du pipeline DLT voulu (trié par timestamp de début décroissant)
- L’ensemble des logs d’événements se trouve dans l’onglet en bas de l’interface
- La 2ème méthode est d’utiliser l’API REST Databricks
- La 3ème méthode est d’utiliser la fonction
event_log(<pipeline_id)(table valued function), c’est la méthode recommandée par Databricks - La 4ème méthode est d’accéder à la table Delta
__event_logse trouvant dans le schéma interne lié au pipeline DLT- Cette méthode nécessite d’avoir le droit “USE” sur le schéma interne et sur le catalogue interne correspondant
1GRANT USE_CATALOG ON CATALOG __databricks_internal TO <user or group>;
2GRANT USE_SCHEMA ON SCHEMA __databricks_internal.__dlt_materialization_schema_<pipeline_id> TO <user or group>;
Le stockage des logs d’événements des pipelines DLT est physiquement séparé pour chaque pipeline DLT et il n’existe pas de vue par défaut qui permet d’avoir une vue agrégée des logs d’événements. Vous trouverez le détail du schéma dans la documentation officielle
Les types d’événements existant sont les suivants (non exhaustif) :
- user_action : Information concernant les actions utilisateurs (création d’un pipeline DLT, exécution d’un pipeline DLT, arrêt manuel d’un pipeline DLT)
- create_update : Information concernant la demande d’exécution du pipeline DLT (origine de la demande)
- update_progress : Information concernant les étapes d’exécution du pipeline DLT (WAITING_FOR_RESOURCES, INITIALIZING, SETTING_UP_TABLES, RUNNING, COMPLETED, FAILED)
- flow_definition : Information concernant la définition des objets (Type de mise à jour (INCREMENTAL, CHANGE, COMPLETE), schéma de l’objet, …)
- dataset_definition : Information concernant la définition des objets (schéma, stockage, type, …)
- graph_created : Information concernant la création du graphe lors de l’exécution du pipeline DLT
- planning_information : Information concernant la planification des rafraîchissements pour les objets “Materialized View”
- flow_progress : Information concernant les étapes d’exécutions de l’ensemble des éléments définis dans le pipeline DLT (QUEUED, STARTING, RUNNING, COMPLETED, FAILED)
- cluster_resources : Information sur la gestion des ressources du cluster du pipeline DLT
- maintenance_progress : Information concernant les opérations de maintenance sur les données dans un délai de 24h après l’exécution du pipeline DLT
Attention :
- Lorsque vous supprimez un pipeline DLT, les logs d’événements ne seront plus accessibles en utilisant la fonction
event_log(<pipeline_id)mais seront toujours accessible en accédant directement à la table Delta “__event_log” concernée (tant qu’elle ne sera pas supprimée) - Les métriques ne sont pas capturées pour les objets “Streaming Table” mis à jour avec le processus de Slow Changing Dimension (SCD) de Type 2 géré par le framework DLT
- Néanmoins, il est possible d’avoir des métriques en accédant à l’historique de la table Delta interne directement
- Lorsqu’il y a des enregistrements ne respectant pas les contraintes sur un objet, nous avons accès aux métriques sur le nombre d’enregistrements mais pas le détail des enregistrements concernés.
Il est très simple de mettre en place des tableaux de bord ou des exports basés sur les événements pour centraliser les informations à partir de l’API REST Databricks, de SQL Warehouse ou en ajoutant un traitement (dans un Job) après l’exécution de chaque pipeline DLT permettant de récupérer les informations nécessaires.
Nous allons nous appuyer sur la 3ème méthode pour donner des exemples de requête permettant d’analyser le pipeline DLT :
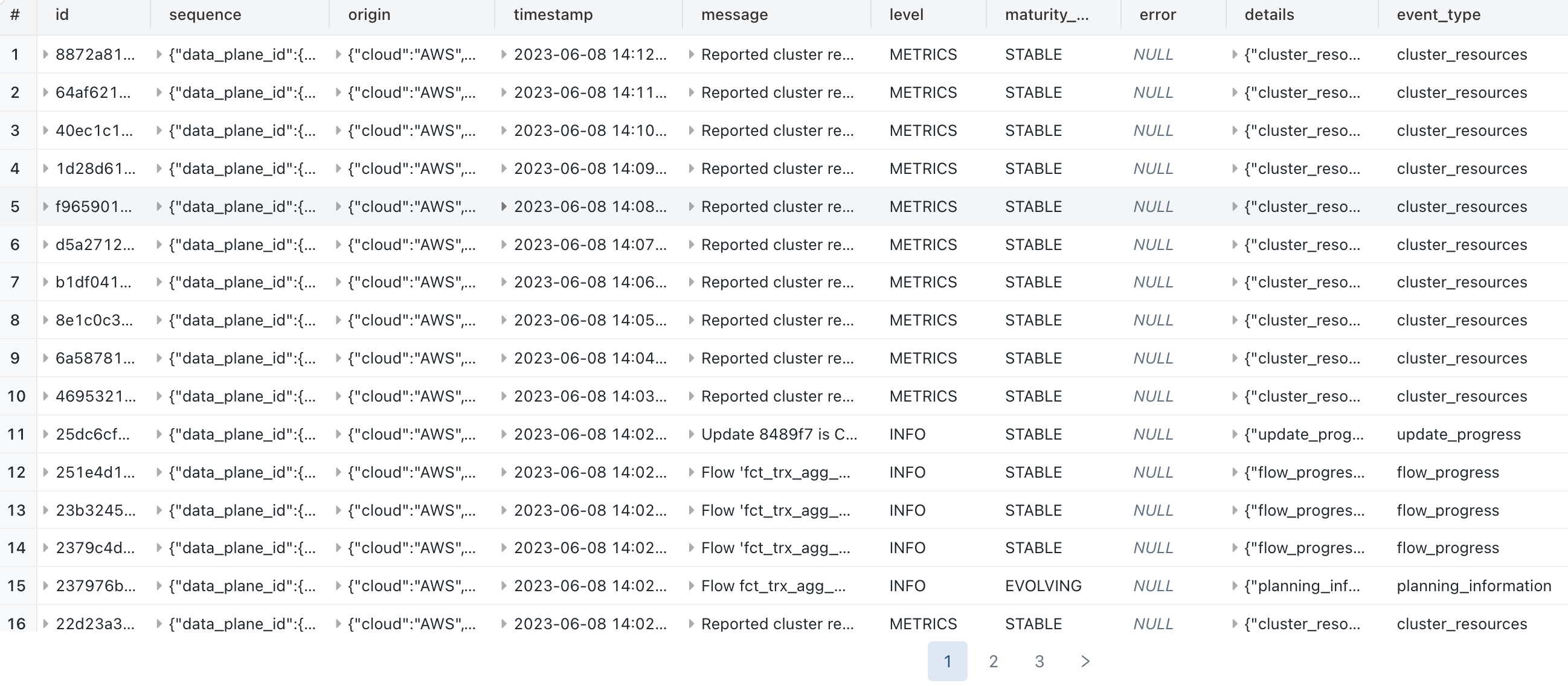
1/ Exemple de requête permettant de récupérer l’ensemble des informations pour la dernière exécution du pipeline DLT
1with updid (
2 select row_number() over (order by ts_start_pipeline desc) as num_exec_desc
3 ,update_id
4 ,ts_start_pipeline
5 from (
6 select origin.update_id as update_id,min(timestamp) as ts_start_pipeline
7 from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c')
8 where origin.update_id is not null
9 group by origin.update_id
10 )
11)
12select l.*
13from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c') l
14where l.origin.update_id = (select update_id from updid where num_exec_desc = 1)
15order by timestamp desc
Résultat :
2/ Exemple de requête permettant de récupérer le nombre de ligne écrites pour chaque objet lors des deux exécutions du pipeline DLT :
1with updid (
2 select row_number() over (order by ts_start_pipeline desc) as num_exec_desc
3 ,update_id
4 ,ts_start_pipeline
5 from (
6 select origin.update_id as update_id,min(timestamp) as ts_start_pipeline
7 from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c')
8 where origin.update_id is not null
9 group by origin.update_id
10 )
11)
12select l.origin.flow_name
13 ,u.ts_start_pipeline
14 ,sum(l.details:['flow_progress']['metrics']['num_output_rows']) as num_output_rows
15 ,sum(l.details:['flow_progress']['metrics']['num_upserted_rows']) as num_upserted_rows
16 ,sum(l.details:['flow_progress']['metrics']['num_deleted_rows']) as num_deleted_rows
17from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c') l
18inner join updid u
19on (l.origin.update_id = u.update_id)
20and event_type = 'flow_progress'
21and details:['flow_progress']['metrics'] is not null
22group by l.origin.flow_name
23 ,u.ts_start_pipeline
24order by l.origin.flow_name
25 ,u.ts_start_pipeline
Remarque :
- Lorsque l’objet est de type “Streaming Table”, les métriques sont capturées avec l’événement qui a le statut “RUNNING”
- Cas particulier pour un objet “Streaming Table” utilisant le processus du SCD Type 2 dont les métriques ne sont pas capturés
- Lorsque l’objet est de type “Materialized View”, les métriques sont capturés avec l’événement qui a le statut “COMPLETED”
- Lorsque l’objet est de type “View”, aucune métrique n’est capturée
Résultat :
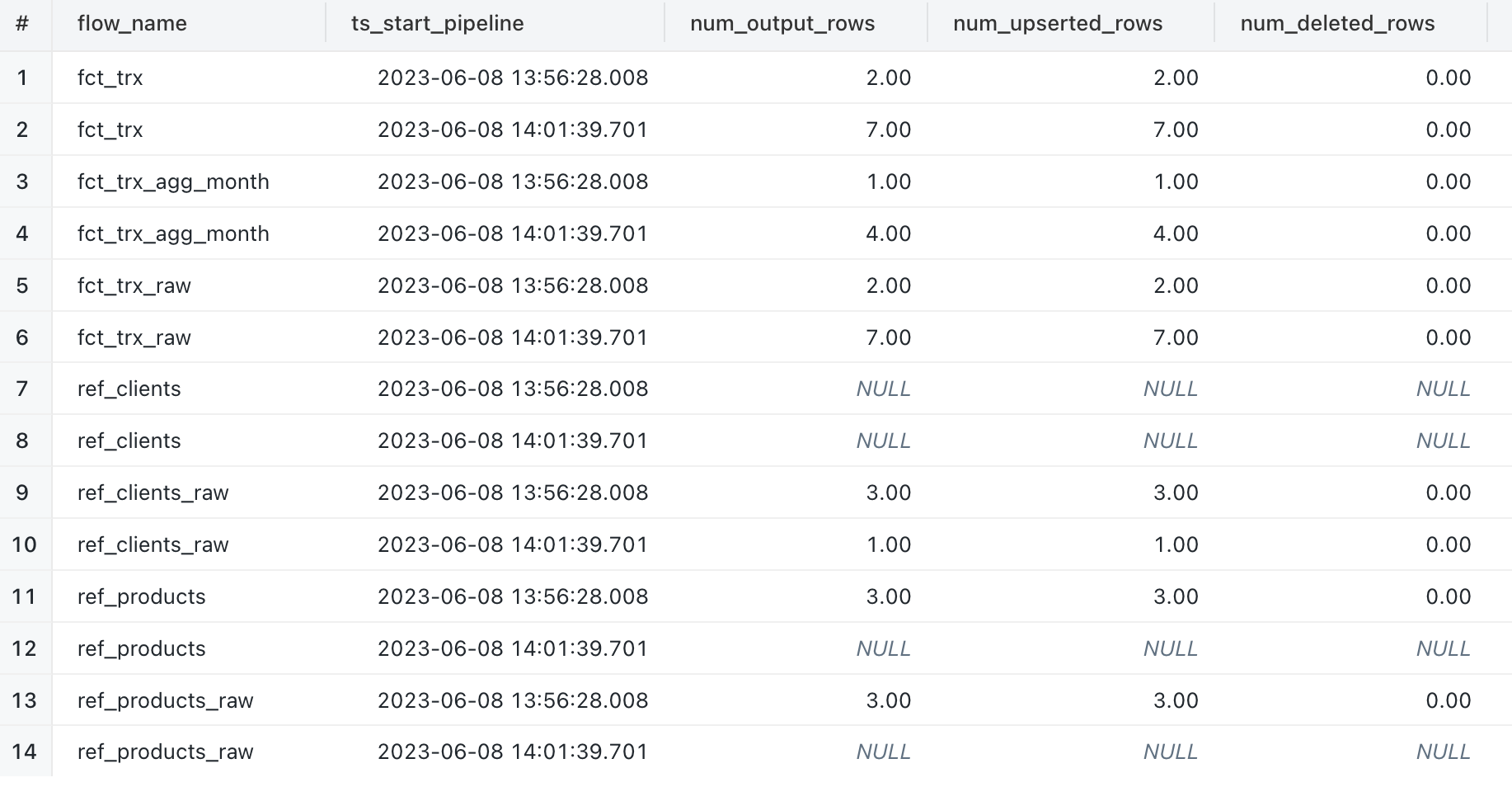
Commentaire :
- Nous pouvons observer que les objets “REF_PRODUCTS” et “REF_PRODUCTS_RAW” n’avaient pas de nouvelle données lors de la deuxième exécution
- Nous pouvons observer que l’objet “REF_CLIENT” n’a pas d’information alors que l’objet source “REF_CLIENT_RAW” a récupéré uniquement les nouvelles données lors de chaque exécution du pipeline DLT
3/ Exemple de requête pour récupérer le nombre d’enregistrements ne respectant pas les contraintes pour l’objet “FCT_TRX” lors de chaque exécution du pipeline DLT :
1with updid (
2 select row_number() over (order by ts_start_pipeline desc) as num_exec_desc
3 ,update_id
4 ,ts_start_pipeline
5 from (
6 select origin.update_id as update_id,min(timestamp) as ts_start_pipeline
7 from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c')
8 where origin.update_id is not null
9 group by origin.update_id
10 )
11)
12select flow_name
13 ,metrics.name
14 ,ts_start_pipeline
15 ,sum(metrics.passed_records) as passed_records
16 ,sum(metrics.failed_records) as failed_records
17from (
18 select l.origin.flow_name as flow_name
19 ,u.ts_start_pipeline as ts_start_pipeline
20 ,explode(from_json(l.details:['flow_progress']['data_quality']['expectations'][*], 'array<struct<name string, passed_records int, failed_records int >>')) as metrics
21 from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c') l
22 inner join updid u
23 on (l.origin.update_id = u.update_id)
24 and event_type = 'flow_progress'
25 and origin.flow_name = "fct_trx"
26 and details:['flow_progress']['data_quality'] is not null
27) wrk
28group by flow_name
29 ,metrics.name
30 ,ts_start_pipeline
31order by flow_name
32 ,metrics.name
33 ,ts_start_pipeline
Résultat :

4/ Exemple de requête pour récupérer les dates de début et de fin de chaque exécution du pipeline DLT :
1with updid (
2 select row_number() over (order by ts_start_pipeline desc) as num_exec_desc
3 ,update_id
4 ,ts_start_pipeline
5 from (
6 select origin.update_id as update_id,min(timestamp) as ts_start_pipeline
7 from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c')
8 where origin.update_id is not null
9 group by origin.update_id
10 )
11)
12select update_id
13,start_time
14,end_time
15,end_time - start_time as duration
16,last_state
17from (
18 select l.origin.update_id as update_id
19 ,min(l.timestamp) over (partition by l.origin.update_id) as start_time
20 ,max(l.timestamp) over (partition by l.origin.update_id) as end_time
21 ,row_number() over (partition by l.origin.update_id order by timestamp desc) as num
22 ,l.details:['update_progress']['state'] as last_state
23 from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c') l
24 inner join updid u
25 on (l.origin.update_id = u.update_id)
26 and event_type = 'update_progress'
27) wrk
28where num = 1
29order by update_id
30,start_time asc
Résultat :

Suppression des éléments
Suppression du pipeline DLT
1dbx-api -X DELETE ${DBX_API_URL}/api/2.0/pipelines/${DBX_DLT_PIPELINE_ID}
Suppression du script Python du Workspace Databricks
1dbx-api -X POST ${DBX_API_URL}/api/2.0/workspace/delete -H 'Content-Type: application/json' -d "{
2 \"path\": \"${DBX_USER_NBK_PATH}/${LOC_SCRIPT_DLT}\",
3 \"recursive\": \"false\"
4}"
Suppression des fichiers de données du DBFS du Workspace Databricks
1dbx-api -X POST ${DBX_API_URL}/api/2.0/dbfs/delete -H 'Content-Type: application/json' -d "{
2 \"path\": \"${DBX_PATH_DATA}\",
3 \"recursive\": \"true\"
4}"
Suppression du catalogue “CTG_DLT_DEMO” du Metastore Unity Catalog :
1-- Delete the Catalog with CASCADE option (to delete all objects)
2DROP CATALOG IF EXISTS CTG_DLT_DEMO CASCADE;
Attention :
- La suppression du pipeline DLT va supprimer l’ensemble des objets (défini dans le pipeline DLT) du schéma cible mais ne supprimera pas directement les tables Delta du schéma interne. La suppression des tables Delta interne se fera lors de l’opéation de maintenance automatique (dans les 24h après la suppression du pipeline DLT)
- En cas de problème, la suppression des tables Delta du schéma interne peut se faire avec les commandes suivantes :
1# Get the list of tables (with full_name)
2export list_tables=(`dbx-api -X GET ${DBX_API_URL}/api/2.1/unity-catalog/tables -H 'Content-Type: application/json' -d "{
3 \"catalog_name\": \"__databricks_internal\",
4 \"schema_name\": \"__dlt_materialization_schema_$(echo ${DBX_DLT_PIPELINE_ID} | sed 's/-/_/g')\"
5}" | jq -r '.tables[]|.full_name'`)
6
7# Delete tables
8for table in ${list_tables}; do
9 dbx-api -X DELETE ${DBX_API_URL}/api/2.1/unity-catalog/tables/${table}
10done
Conclusion
Le framework DLT permet d’être très efficace dans la création et l’exécution d’un pipeline ETL et de pouvoir facilement ajouter une gestion de la qualité de la donnée (sous réserve d’utiliser l’édition Advanced).
Le fait de pouvoir visualiser le graphe et les métriques associées aux objets d’une exécution précise du pipeline DLT est extrêmement pratique pour une analyse rapide. De plus, l’accès aux logs d’événements (stockés dans une table Delta) nous permet de récupérer beaucoup d’informations et de pouvoir faire des analyses et des tableaux de bords très simplement.
Lors de POC ou de traitement d’ingestion ETL spécifique, il est très pratique de pouvoir s’appuyer sur le framework DLT mais dans le cadre d’un projet nécessitant de gérer de nombreux objets et schémas, on se retrouve beaucoup trop limité pour pouvoir utiliser le framework DLT.
En l’état (preview public), les limitations sont trop importantes pour nous permettre de recommander l’utilisation du framework DLT avec Unity Catalog pour des projets importants :
- Le lineage est incomplet si l’objet n’est pas géré dans le pipeline DLT ou si on utilise des objets de type “View”
- On ne peut avoir qu’un seul schéma cible pour l’ensemble des éléments d’un pipeline DLT
- Certaines opérations (gestion SCD Type 1 et 2) n’ont pas de métriques capturées dans les logs d’événements
- Pas d’agrégations des logs d’événements de l’ensemble des pipelines par défaut si l’on souhaite faire des analyses sur l’ensemble des pipelines DLT
A mon humble opinion, il est encore un peu tôt pour utiliser le framework DLT en s’appuyant sur la solution Unity Catalog pour gérer l’ensemble des processus ETL pour la gestion des données d’une entreprise, mais j’ai hâte de voir les futurs améliorations apportées par Databricks pour en faire un outil central et performant pour gérer les processus ETL tout en profitant de l’ensemble des fonctionnalités de la solution Unity Catalog (Data Lineage, Delta Sharing, …).