
Azure : Microsoft Fabric Preview
Suite à l’annonce du passage en preview de la solution Microsoft Fabric, j’ai profité de la version d’essai (Trial) en preview pour en faire un premier tour rapide.
Note n°1 : Certains termes resteront en anglais pour faciliter la compréhension
Note n°2 : Les informations se basent sur l’état de la solution début Juillet 2023 en mode preview.
Qu’est ce que Microsoft Fabric
Synthèse
Microsoft Fabric est une solution proposée par Microsoft pour regrouper de manière cohérente un ensemble de services se basant principalement sur les services Azure et permettant de couvrir l’ensemble des besoins analytiques liés aux données.
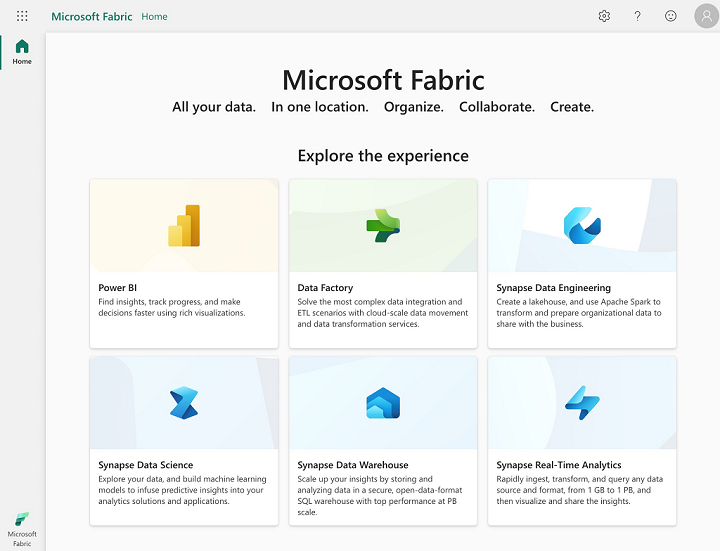
Les fondations de Microsoft Fabric reposent principalement sur les trois éléments suivants:
- OneLake
- Un ensemble de SaaS (Software as a Service)
- Des Capacity Fabric
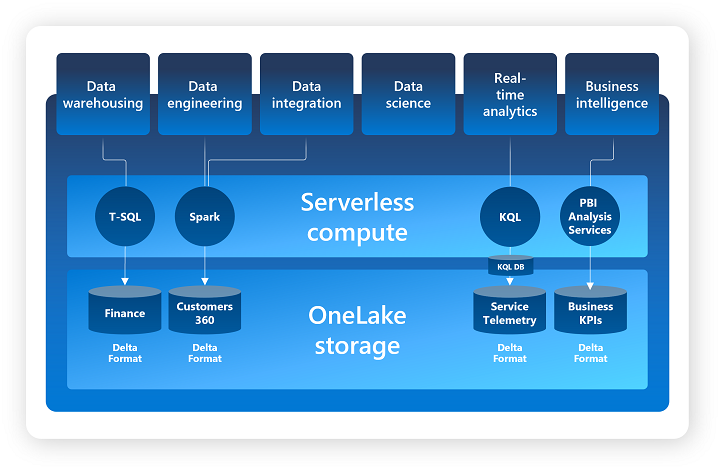
OneLake est un Data Lake unifié pour l’ensemble d’un Tenant (organisation) se basant sur Azure Data Lake Gen2 permettant de centraliser la gouvernance et la gestion des données.
Pour la partie SaaS, on retrouve les éléments suivants (qui seront enrichis dans le futur) :
- Data integration : Data Factory
- Gestion des Dataflow (Gen2) et des Data pipeline
- Data engineering : Synapse Data Engineering
- Gestion des Lakehouse, Notebook, Apache Spark Job Definition
- Data warehousing : Synapse Data Warehouse
- Gestion des Warehouses
- Data science : Synapse Data Science
- Gestion des Models, Experiments et Notebooks
- Real-time analytics : Synapse Real Time Analytics
- Gestion des KQL Database, KQL Queryset, Eventstream
- Business intelligence : Power BI
- Gestion des Reports, Dashboards, Dataflow, Datamart, Dataset, …
Note : On peut observer que Microsoft Fabric s’appuie principalement sur les services Azure Synapse et Power BI.
Concernant la notion de Capacity Fabric :
- L’ensemble des services étant des services managés et serverless, la puissance à disposition est défini par une Capacity Fabric
- Une Capacity Fabric est propre à un Tenant (organisation) et il peut y en avoir plusieurs par organisation.
- Chaque Capacity Fabric représente un ensemble de ressources distinct alloué à Microsoft Fabric et plus spécifiquement aux espaces de travail (Workspaces) concernés.
- Le choix de la configuration d’une Capacity Fabric va déterminer la puissance de calcul disponible et par conséquent les services managés utilisables. Vous trouverez la liste des configurations dans la documentation officielle
La hiérarchie des éléments :
- Niveau n°1 : OneLake est unique pour l’ensemble d’un Tenant
- Niveau n°2 : Les workspaces (avec regroupement logique par domaine possible)
- Niveau n°3 : les ressources (Lakehouse, Warehouse, KQL Database, SQL Endpoint, …)
- Niveau n°4 : les objets (Files, Tables, Dashboard, Notebooks, …)
Un workspace est assigné à une Capacity Fabric et l’ensemble des services managés utilise les ressources de cette Capacity Fabric pour s’exécuter.
La centralisation de la gestion des droits (par rôles/utilisateurs) permet de gérer les accès par workspaces et de gérer les droits sur les éléments des différents services de manière simplifiée.
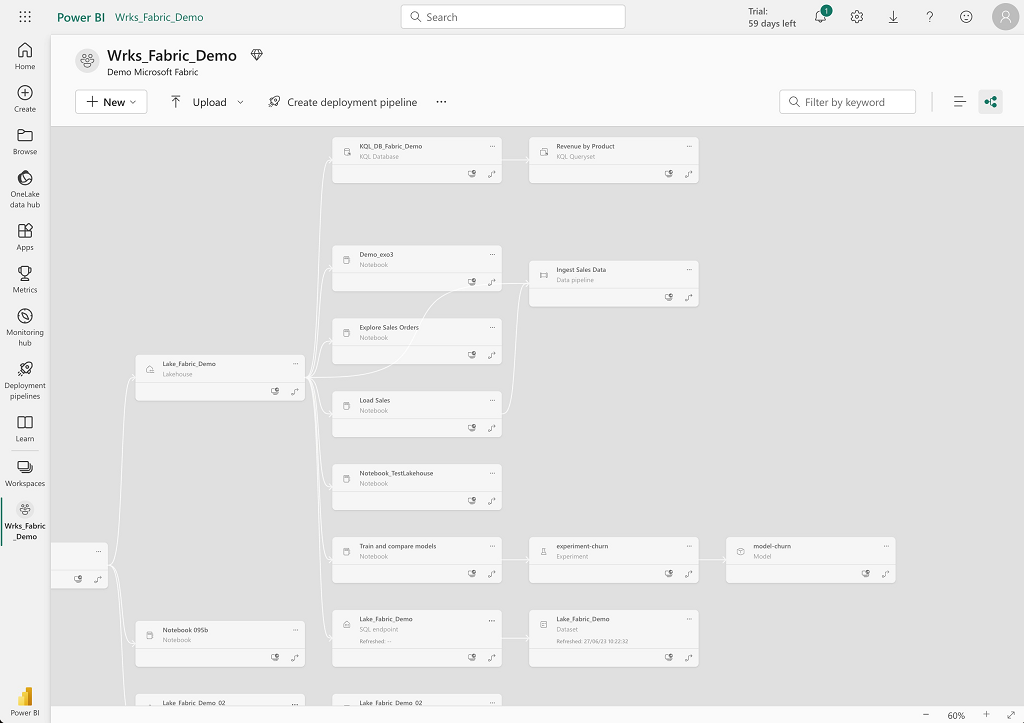
Par défaut, Microsoft Fabric propose une visualisation du linéage des objets au niveau d’un workspace.
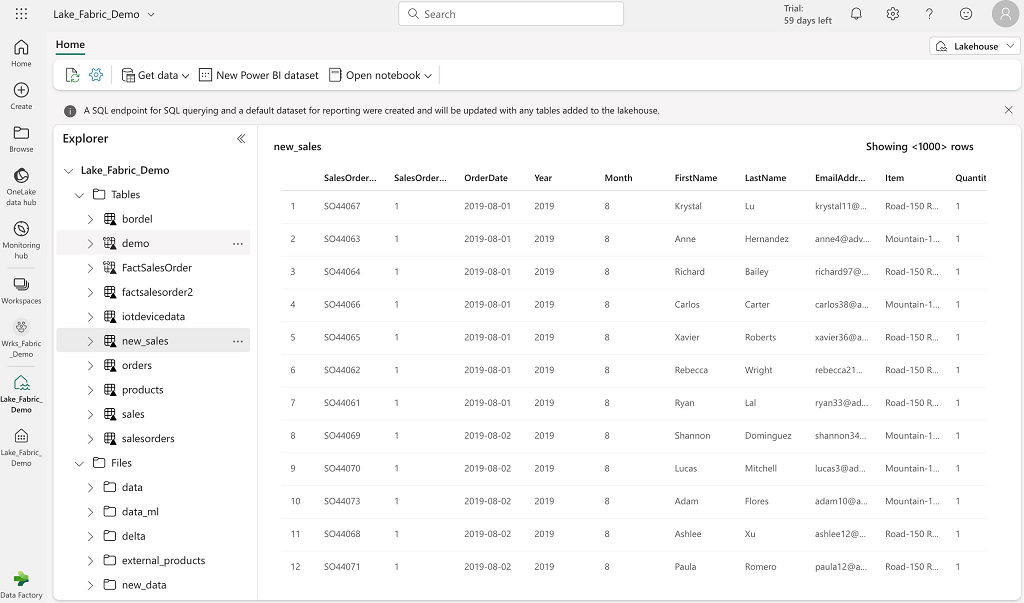
Concernant la partie Lakehouse
Un Lakehouse va permettre de stocker des données sous formes de fichiers ou de tables en utilisant par défaut l’espace de stockage de OneLake.
Exemple de l’interface du Lakehouse :
Deux moteurs sont utilisées :
- Apache Spark pour transformer et manipuler les données
- Un moteur SQL pour accéder aux données en lecture en utilisant la syntaxe T-SQL
Lors de la création d’un Lakehouse, Microsoft Fabric créé par défaut deux éléments supplémentaires (avec le même nom que le Lakehouse) :
- Un SQL Endpoint (Moteur SQL)
- Un Dataset par défaut (Représentation des données)
Le SQL Endpoint permet d’utiliser la syntaxe T-SQL pour accéder aux données des tables définies au niveau du Lakehouse en lecture seule. Il permet aussi d’accéder en lecture seule aux tables des autres Lakehouse et Warehouse du même workspace.
Il est possible de réaliser les actions suivantes avec un SQL Endpoint :
- Requêter les tables du Lakehouse et du Warehouse
- Créer des vues et procédures permettant d’encapsuler des requêtes en T-SQL
- Gérer les droits sur les objets
Le Dataset par défaut permet à PowerBI d’accéder aux données des tables du Lakehouse. Il est possible de créer des rapports PowerBI directement à partir des données du Lakehouse (répertoire Tables uniquement) en utilisant le dataset par défaut ou en créant un nouveau dataset et en définissant un modèle de données associé (lien entre les objets).
Le Lakehouse est composé de deux répertoires racines :
- Le répertoire Tables représente les données managées par le Lakehouse (format Delta dont le stockage et les métadonnées sont gérés directement par le Lakehouse)
- Le répertoire Files représente les données non managées par le Lakehouse (multiple format de données gérées par l’utilisateur)
Il est possible de travailler avec les données dans le Lakehouse de plusieurs manières :
- Upload: Télécharger des fichiers ou répertoires locaux vers le Lakehouse (dans le répertoire Files) et charger les données dans le répertoire Tables
- Dataflows (Gen2) : Importer et transformer des données à partir de nombreuses sources et charger les directement dans des tables du Lakehouse
- Data Factory pipelines : Copier des données et orchestrer les activités de transformations et chargement des données dans les répertoires Tables ou Files du Lakehouse
- Notebooks : Travailler de manière interactive avec les données avec Apache Spark (Scala, Java, Python, R …)
- Shortcuts (Raccourcis) : Se connecter aux stockages externe (OneLake, Azure Data Lake Gen2, AWS S3)
- Il existe deux types de Shortcuts :
- Au niveau du répertoire Files, cela permet de faire un lien vers un espace de stockage externe pour travailler directement avec les données de manière sécurisée
- Au niveau du répertoire Tables, cela permet de synchroniser une table avec une table d’un autre Lakehouse
- Il existe deux types de Shortcuts :
Remarques :
- Si on crée plusieurs Lakehouses dans un même workspace, alors on aura plusieurs SQL Endpoints mais qui en réalité auront tous la même chaîne de connexion
- La suppression d’un Lakehouse supprime automatiquement le dataset par défaut et le SQL Endpoint associé
Concernant le format des données utilisables au niveau du Lakehouse :
- Pour le répertoire Files : PARQUET, CSV, AVRO, JSON et tous les formats compatible avec Apache Hive
- Pour le répertoire Tables : Le format par défaut est Delta
Au niveau du stockage, les données sont par défaut stockées dans les espaces suivants :
- Chemin avec le nom des tables :
<workspace name>@onelake.dfs.fabric.microsoft.com/<lakehouse name>.Lakehouse/Tables/* - Chemin avec le nom des fichiers :
<workspace name>@onelake.dfs.fabric.microsoft.com/<lakehouse name>.Lakehouse/Files/* - Chemin avec les identifiants uniques (tables) :
<workspace id>@onelake.dfs.fabric.microsoft.com/<lakehouse id>/Tables/*
Concernant la partie Warehouse
Ce service repose sur Synapse Warehouse Serverless permettant d’utiliser la syntaxe T-SQL pour fournir l’ensemble des opérations d’une base de données (insert, update, delete, select, grant, …) sur les différents objets gérés.
Exemple de l’interface du Warehouse :
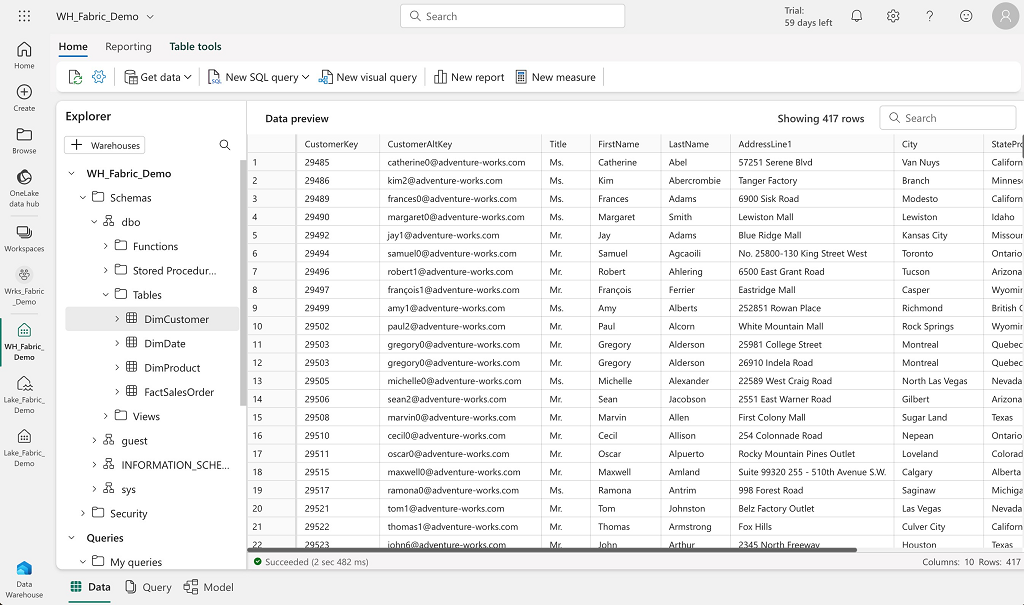
Le stockage des données se trouve au niveau du OneLake et utilise le format Delta (qui devrait être le format par défaut). Remarque : dans la version preview, lorsque l’on crée une table sans préciser le format de stockage alors on se retrouve avec le format par défaut de Hive (qui n’est pas le format Delta).
Ce service permet de mettre en place une couche de modélisation relationnelle au-dessus du stockage des données dans le Lakehouse et de profiter de l’ensemble des caractéristiques d’un Warehouse (propriété ACID, concurrence, gestion des droits, organisation en schéma, modèle relationnel…). L’exploration des données peut se faire très facilement directement avec des requêtes T-SQL ou des outils de reporting comme PowerBI. L’interface de Synapse Warehouse permet aussi de gérer les requêtes T-SQL (création, sauvegarde, modification, ….)
La création d’un Warehouse dans un workspace génère les éléments suivants :
- Création des schémas par défaut : dbo, guest, INFORMATION_SCHEMA et sys
- Création d’un dataset par défaut ayant le même nom que le Warehouse pour l’accès aux données avec PowerBI
Remarque :
- A partir d’un Warehouse, on peut accéder aux tables d’un Lakehouse comme si c’était simplement une base de données différente dont les objets sont stockée dans un schéma nommé dbo mais en lecture seule uniquement. Il n’est pas possible de faire des requêtes de type DML (modification des données) sur les objets d’un Lakehouse à partir d’un Warehouse
- Il faut que les données du Lakehouse soient copiées (avec par exemple l’utilisation de la fonctionnalité Shortcut) dans le Warehouse pour être modifiées
- Un Shortcut aura la même fonctionnalité pour une table du Warehouse que pour une table du Lakehouse
Au niveau du stockage, les données sont par défaut stockée dans l’espace suivant :
- Chemin au format abfss :
abfss://<workspace id>@onelake.dfs.fabric.microsoft.com/<warehouse id>/Tables/<schema name>/<table name> - Chemin au format https :
https://onelake.dfs.fabric.microsoft.com/<workspace id>/<warehouse id>/Tables/<schema name>/<table name>
Information concernant la différence entre un SQL Endpoint et un Warehouse :
- Un SQL Endpoint est utilisé uniquement pour réaliser des requêtes de type select sur les données d’un Lakehouse ou d’un Warehouse
- Un Warehouse est utilisé pour avoir l’ensemble des fonctionnalités d’une base de données en serverless (transactions ACID, DML opérations, …) Vous trouverez plus d’informations dans la documentation officielle.
Concernant la partie KQL Database
Synapse Real-Time Analytics est un service managé et serverless qui est optimisé pour le stockage et l’analyse des données en temps réel. Ce service s’appuie sur une base de données KQL qui se base sur Data Explorer Database et utilise le langage Kusto Query (KQL) permettant uniquement de lire les données pour retourner un résultat.
Exemple de l’interface de KQL Database :
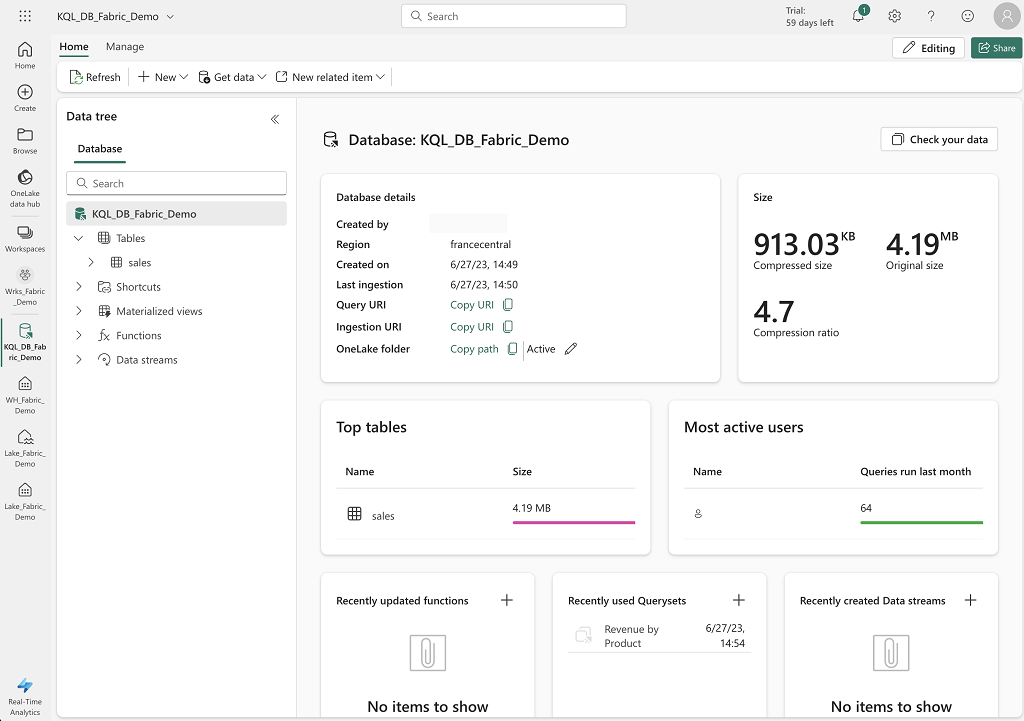
Le service est constitué des éléments suivants :
- Une base de données Kusto (KQL Database) permettant de gérer des collections d’objets de type tables, fonctions, vues matérialisées et Shortcuts.
- La lecture et manipulation des données se fait avec des KQL Queryset qui permet uniquement d’accéder et d’appliquer des transformations aux données mais pas de modifier le contenu d’une table.
- La fonctionnalité Eventstream permet de facilement intégrer des données provenant de sources comme Event Hubs.
Les objets d’une KQL Database :
- Une table permet de stocker les données sous forme tabulaire (colonnes et lignes) et typées
- Une fonction permet de définir une requête encapsulée pouvant être utilisée dans une requête KQL et pouvant avoir une liste de paramètre en entrée
- Une vue matérialisée permet de pré-calculer le résultat d’une requête encapsulée pour optimiser les temps d’accès aux données
- Un datastream est un ensemble d’eventstreams KQL connectés et rattachés à la base de données (KQL Database)
Au niveau du stockage :
- Chemin au format https :
https://francecentral-api.onelake.fabric.microsoft.com/<workspace id>/<KQL database id>/tables/<table name>
Quelques informations supplémentaires sur KQL Database :
- Par défaut, KQL Database stocke les données dans un format en colonne, de cette manière le moteur n’a besoin d’accéder qu’aux colonnes concernées par les requêtes au lieu de scanner l’ensemble des données d’un objet.
- KQL database est optimisée pour les données qui sont uniquement lues, supprimées rarement et jamais mises à jour
- KQL database est conçue pour accélérer l’ingestion des données en n’appliquant aucune des contraintes que l’on retrouve sur les bases de données relationnelles (PK, FK, Check, Unicité, …).
- KQL database gère les Shorcuts comme des tables externes.
Note : Il n’est pas possible de lire les données de KQL Database à partir du SQL Endpoint ou du Warehouse.
Vous trouverez plus d’informations concernant la comparaison entre Synapse Real-Time Analytics et Azure Data Explorer dans la documentation officielle.
Concernant la partie PowerBI
C’est le service le plus mis en avant dans la solution Microsoft Fabric.
Toutes les ressources et toutes les données gérées par Microsoft Fabric (et stockées dans OneLake) sont accessibles par PowerBI pour valoriser les informations et mettre en place les rapports et analyses souhaités de manière très rapide.
L’élément clé pour l’utilisation de PowerBI est le Dataset. Par défaut, lors de la création d’un Lakehouse ou d’un Warehouse, Microsoft Fabric crée automatiquement un dataset par défaut mais il est possible de créer ces propres datasets avec la modélisation souhaitée pour pouvoir utiliser les données avec PowerBI.
Concernant la notion de Dataset :
- Un dataset est une couche sémantique avec des métriques représentant un ensemble d’objet stocké dans les différents services et utilisé pour la création des rapports et analyses
- Les datasets sont automatiquement synchronisés avec l’état des données dans le Lakehouse ou le Warehouse, il n’y a pas de gestion ou de rafraîchissement spécifique à gérer
- Les nouveaux objets d’un Lakehouse ou d’un Warehouse sont automatiquement ajoutés dans les datasets par défaut correspondant
Il est très facile d’accéder à l’ensemble des objets par les datasets sur l’ensemble des services (Lakehouse, Warehouse, KQL database) de Microsoft Fabric avec PowerBI et de partager les différents éléments créés avec d’autres utilisateurs.
Je n’ai pas pu tester l’utilisation de l’IA avec Copilot pour PowerBI qui est un élément mis en avant par Microsoft pour faciliter la création de rapports et de manière générale, l’analyse des données par une population n’étant pas experte sur PowerBI.
Concernant Data Science
Le service Synapse Data Science permet de gérer l’ensemble des éléments (Notebooks, Models, Experiments) en s’appuyant sur le framework MLflow pour travailler sur l’ensemble des besoins en Machine Learning.
L’ensemble des éléments utilise MLflow qui est un framework open source permettant de tracer et gérer les expérimentations.
Concernant les notebooks :
- Ils permettent de travailler de manière interactive sur les données avec Apache Spark (Python, Scala, SQL, R)
- Ils sont automatiquement rattachés à un cluster Apache Spark
- Ils permettent de lire les données du Lakehouse en utilisant des dataframes Apache Spark ou Pandas.
Concernant les expérimentations :
- Une expérimentation consiste à un ou plusieurs exécutions d’une tâche d’un notebook.
- Il est possible de créer des expérimentations à partir de l’interface utilisateur ou directement avec le framework MLflow
Concernant les modèles :
- le framework MLflow permet de tracer et gérer les modèles au sein de Microsoft Fabric
- A partir d’une expérimentation, il est possible de sauvegarder l’ensemble des éléments sous forme d’un nouveau modèle avec l’ensemble des métadonnées associées.
Observations
Attention : Afin d’activer Microsoft Fabric (preview), il est indispensable d’être un membre d’un Azure Active Directory et d’avoir le rôle Power BI Administrator.
L’expérience utilisateur PowerBI est la base de l’expérience utilisateur Microsoft Fabric.
Au niveau du workspace :
- Utilisation de Azure DevOps uniquement pour gérer les sources (pas de github ou gitlab proposé) au niveau du workspace
- Cela manque d’un système de hiérarchie ou de répertoire pour organiser les différents éléments au sein d’un workspace (afin d’améliorer sa compréhension et sa lisibilité)
- On doit se reposer sur une normalisation stricte du nommage des objets pour pouvoir les filtrer et trier efficacement
- Il y un effet bordélique lorsque l’on commence à avoir un certain nombre d’élément dans un workspace comme cela est visible sur les écrans ci-dessous
Visualisation des éléments au niveau du OneLake :
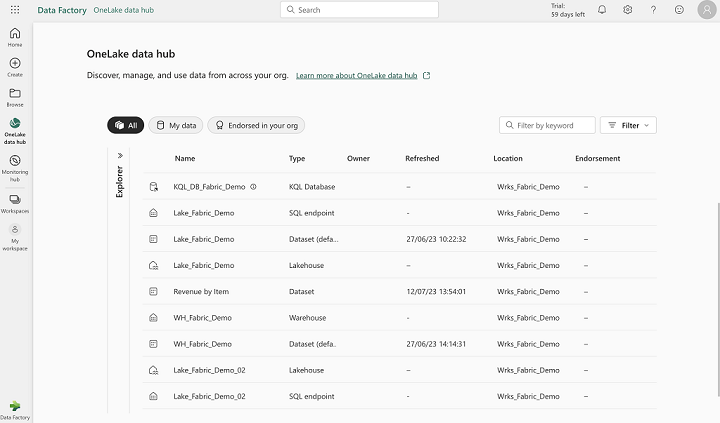 Note : Cette interface permet de voir les ressources créés (Lakehouse, Warehouse, KQL Database, SQL Endpoint, Dataset) mais pas directement les objets (fichier, tables, notebooks)
Note : Cette interface permet de voir les ressources créés (Lakehouse, Warehouse, KQL Database, SQL Endpoint, Dataset) mais pas directement les objets (fichier, tables, notebooks)
Visualisation des éléments au niveau d’un workspace :
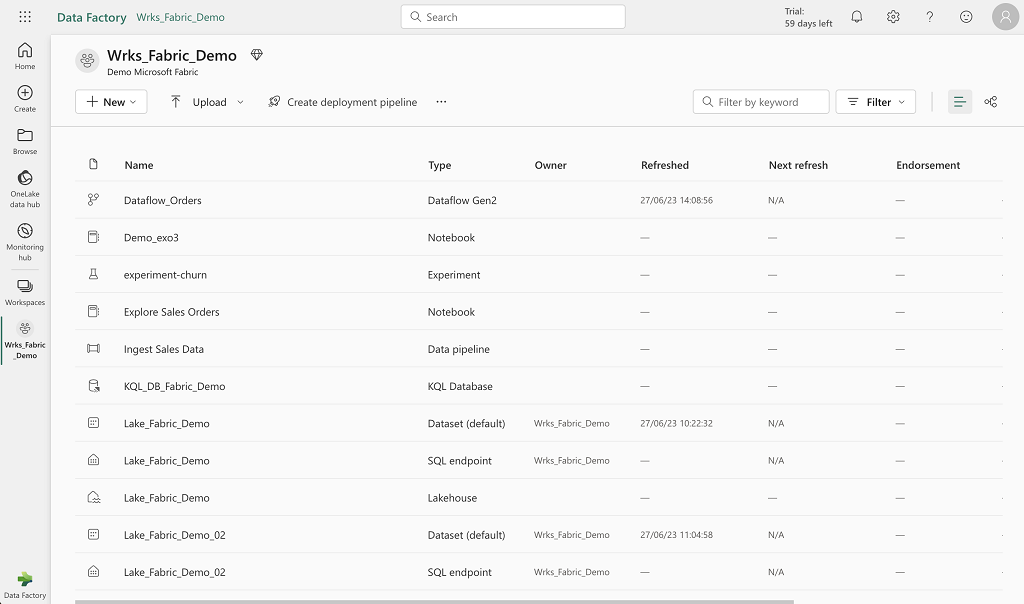 Note : Cette interface permet de voir l’ensemble des éléments d’un workspace (ressources et objets)
Note : Cette interface permet de voir l’ensemble des éléments d’un workspace (ressources et objets)
Afin de pouvoir naviguer, il est possible de filtrer par nom ou par type d’éléments sur les différentes interfaces :
La gestion des notebooks est proche de celle de Databricks sans le versionning automatique. Avec l’explorateur (se situant à gauche de l’interface), il est très simple de générer une syntaxe minimale pour le chargement des données (Tables ou Files) avec Apache Spark (création automatique d’une cellule avec le code minimal)
Quelques limitations lorsque l’on souhaite configurer un job Apache Spark :
- Utilisation d’un script python uniquement
- Possibilité de télécharger un fichier local ou de récupérer un fichier d’un stockage ADLS Gen2
- Possibilité d’ajouter une ligne de commande
- Possibilité d’ajouter un Lakehouse de référence pour pouvoir utiliser les chemins relatifs (Files/…)
- Limitation de la configuration du job cluster :
- Choix de l’ordonnancement
- Choix du runtime Apache spécifique à Microsoft Fabric (voir la documentation officielle)
- Aucun choix concernant la configuration des workers
- Configuration des “retry” en cas d’erreur
Partage des données :
- Les données du Lakehouse ne semblent pas partagées par défaut avec le Warehouse contrairement au SQL Endpoint qui lui a accès directement au tables du Lakehouse dans le schéma par défaut dbo (même schéma par défaut que le Warehouse)
- A partir d’un SQL Endpoint, on peut ajouter ou enlever les Warehouse et Lakehouse souhaités du même workspace (afin de les visualiser dans l’explorateur)
- Définition des clés étrangères entre les différents objets dans l’onglet Model pour pouvoir utiliser plus facilement le Visual Query (et pour PowerBI)
- Interface très peu efficace lorsque l’on souhaite faire des modifications dans l’onglet Model
- Dès que l’on clique sur une colonne pour la rendre invisible, il y a 1 à 2 secondes d’attente à cause du rafraîchissement de l’ensemble des objets de l’interface, par conséquent lorsque l’on souhaite réaliser cette action plusieurs fois c’est extrêmement lent et désagréable
- Lorsque l’on veut créer un rapport :
- Dans le panneau Data, on visualise l’ensemble des objets (tables et vues) même ceux ne faisant pas partie du Model défini
Dans une logique d’architecture en médaillon, on se retrouve avec deux possibilités :
- Utilisation d’un Lakehouse unique pour l’ensemble des zones
- Les Zones Bronze et Silver se retrouvent au niveau de deux sous-répertoires différents dans le répertoire Files du Lakehouse
- La Zone Gold se retrouve au niveau des tables du Lakehouse (pas de fonctionnement de schéma)
- Cela rendra accessible uniquement les données de la zone Gold au plus grand nombre d’usage par l’utilisation d’un SQL Endpoint ou d’un Warehouse
- Utilisation d’un Lakehouse par zone
- Permet de tout gérer au niveau des tables de chaque zone (par Lakehouse) et de profiter de l’ensemble des fonctionnalités offertes sur l’ensemble des zones
- Surcoût en terme de ressources et de gestion des droits
Pour la gouvernance des données, il est possible d’utiliser Microsoft Purview avec Microsoft Fabric et de mettre en place une capture du linéage des données.
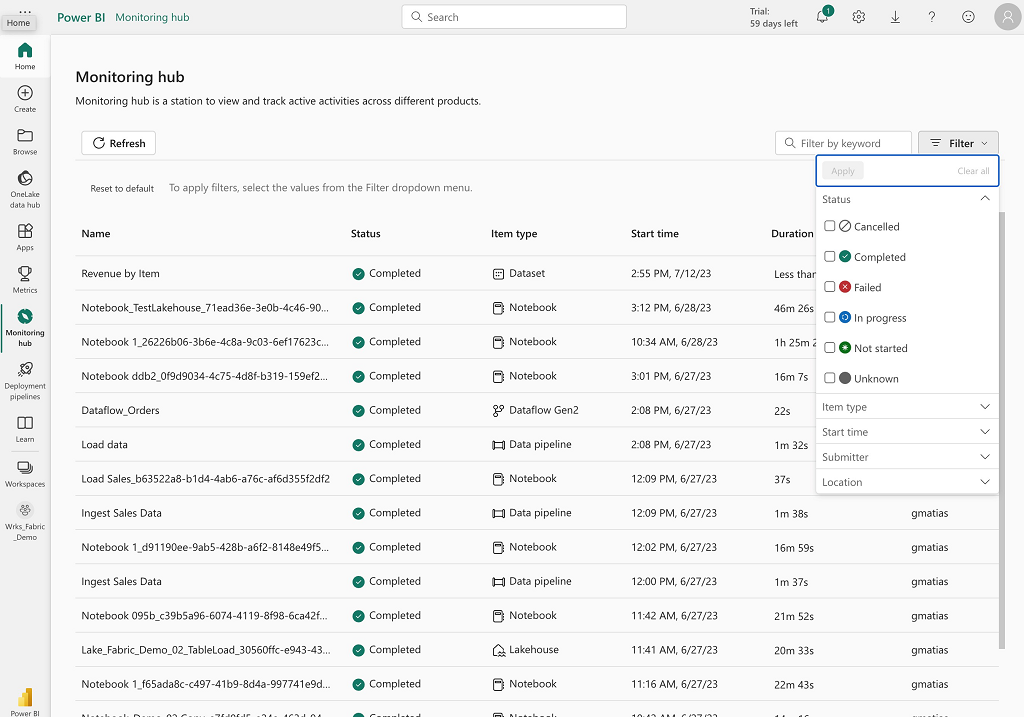
Il y a une partie Monitoring permettant de suivre l’exécution des traitements/activités au niveau du tenant mais pas des ressources/services directement.
Conclusion
C’est clairement une offre cohérente qui permet d’avoir un usage démultiplié des données en limitant la duplication des données sur différents espaces de stockage.
La centralisation de la gestion des données permet de faciliter la gouvernance et le partage des données.
Il y a une réelle volonté de pousser PowerBI comme la solution unique d’analyse des données.
C’est une direction très intéressante dans la centralisation des données afin de limiter l’effet silos et de faciliter le partage des données et la centralisation de la gouvernance (dans une approche Data Mesh par exemple).
Il y a un axe important du développement qui porte sur le principe du no-code (ou low-code) afin de pouvoir travailler sur les données sans écrire de code en se basant sur les services Synapse principalement. Cela est une bonne idée pour pouvoir gérer/utiliser les données par des utilisateurs qui ne sont pas Data Engineer dans le cadre d’expérimentation et de démonstration mais lorsque l’on souhaite industrialiser efficacement la gestion des données et des traitements, cela devient une contrainte pouvant être très coûteuse en temps et en énergie.
En ajoutant le fait que l’on ne peut pas gérer la configuration des ressources qui s’appuie directement sur une Capacity Fabric, on se retrouve avec une facilité d’utilisation des données mais avec une perte de maîtrise des ressources et par conséquent des coûts. Note : Petite exception pour le Pool Apache Spark qui permet de gérer quelques paramètres comme le nombre et le type des workers
En conclusion, Microsoft Fabric est une solution tout en un et clé en main pour permettre à tout type d’utilisateurs de gérer et manipuler de la données dans un espace unifié mais je pense qu’une solution comme Databricks ou Snowflake permet d’être beaucoup plus efficace (performance, coût, industrialisation) tout en gardant l’utilisation du service PowerBI pour l’approche Lakehouse, Warehouse, Data Science, la centralisation de la gouvernance de données et la maîtrise des coûts mais ne permettra pas à une population avec peu de compétence technique de travailler correctement avec les données.