
LLMs : Utilisation de Ollama avec Podman et VS Code
Vous trouverez dans cet article, des informations pour utiliser Ollama (LLMs) avec Podman et VS Code.
Ollama
Ollama est un outil gratuit et open-source conçu pour exécuter localement des LLMs (Large Language Models) libre sur votre système.
Ollama est conçu pour tirer avantage des cartes graphiques Nvidia ou AMD. Si vous n’avez qu’un CPU, vous aurez une très mauvaise performance du modèle.
Vous trouverez la liste des GPU prises en charge dans la documentation officielle.
Il est nécessaire d’avoir une quantité importante de mémoire pour l’utiliser. Je vous recommande de disposer d’au moins 32 Go.
Vous trouverez tous les modèles LLM disponibles dans la bibliothèque officielle.
Quelques exemples de modèles disponibles :
- llama3 : Meta Llama 3, une famille de modèles développée par Meta Inc.
- codellama : Code Llama est un modèle conçu pour générer et discuter du code, construit sur la base de Llama 2.
- gemma2 : Google Gemma 2, présentant une nouvelle architecture conçue pour offrir des performances et une efficacité exceptionnelles.
- codegemma : CodeGemma est un ensemble de modèles puissants et légers qui peuvent accomplir diverses tâches de codage, telles que la finition automatique du code, la génération de code, la compréhension naturelle du langage, la raison mathématique et l’exécution d’instructions.
- starcoder2 : StarCoder2 est la prochaine génération de modèles decode ouverts entraînés de manière transparente.
Commandes utiles :
ollama list: Liste les modèles récupérésollama ps: Liste les modèles en cours d’exécutionollama pull <model>: Récupère un modèle à partir d’un dépôtollama show <model>: Affiche des informations concernant un modèleollama run <model>: Execution d’un modèleollama rm <model>: Suppression d’un modèle
Podman
Podman est un outil sans démon, open-source, natif Linux, conçu pour faciliter la recherche, l’exécution, la construction, le partage et le déploiement d’applications en utilisant les conteneurs et les Images de Conteneur Open Containers Initiative (OCI).
Podman propose une ligne de commande (CLI) familière aux utilisateurs de l’outil Docker.
Podman gère l’ensemble de l’écosystème de conteneurs, qui inclut les pods, les conteneurs, les images de conteneurs et les volumes, en utilisant la bibliothèque libpod.
Concepts fondamentaux :
- Un pod est un groupe de conteneurs qui fonctionnent ensemble et partagent les mêmes ressources, similaire aux pods Kubernetes.
- Un conteneur est un environnement isolé dans lequel une application peut fonctionner sans affecter le reste du système ou être influencé par celui-ci.
- Une image de conteneur est un fichier statique contenant du code exécutable qui peut créer un conteneur sur un système informatique. Une image de conteneur est immuable – cela signifie qu’elle ne peut pas être modifiée et peut être déployée de manière cohérente dans n’importe quel environnement.
- Un volume de conteneur est un stockage durable qui peut être utilisé par un conteneur.
Attention : Pour obtenir une performance optimale, je vous recommande d’utiliser le GPU Passthrough.
VS Code
VS Code est un éditeur de code extensible et multi-plateformes développé par Microsoft.
VS Code peut être étendu via des extensions disponibles dans un dépôt central.
Continue est un assistant de code AI open-source qui permet de connecter n’importe quels modèles à un IDE.
Nous utiliserons l’extension VS Code Continue pour travailler avec notre configuration Ollama (locale ou distante). En outre, vous pouvez utiliser différents fournisseurs et services, tels que Open AI, Anthropic, Mistral, Gemini, et d’autres.
Installation de l’extension VS Code Continue
Les étapes à suivre :
- Ouvrez VS Code
- Cliquez sur le menu “extensions” dans le panneau à gauche
- Filtrez les résultats avec le terme
Continue.continue
- Installez l’extension nommée “Continue - Codestral, Claude, and more”
- Sélectionnez l’icone Continue dans le panneau de gauche

Configuration de l’extension VS Code Continue
Vous pouvez accéder au fichier config.json de deux manières différentes.
Première manière par l’interface de VS Code :
- Ouvrez VS Code
- Cliquez sur le menu Continue dans le panneau de gauche
- Cliquez sur l’option Configure Continue en bas à droite du nouveau panneau de gauche

Seconde manière par la Palette de commande de VS Code :
- Ouvrez VS Code
- Ouvrez la Palette de commande avec la combinaison
Ctrl + Shift + p - Utilisez le terme
continue optiondans l’espace de recherche et sélectionnez l’optionContinue : open config.json
Configuration locale
Mise en place de Ollama en locale
Nous utiliserons les paramètres suivantes :
- Modèle Ollama :
llama3:8b
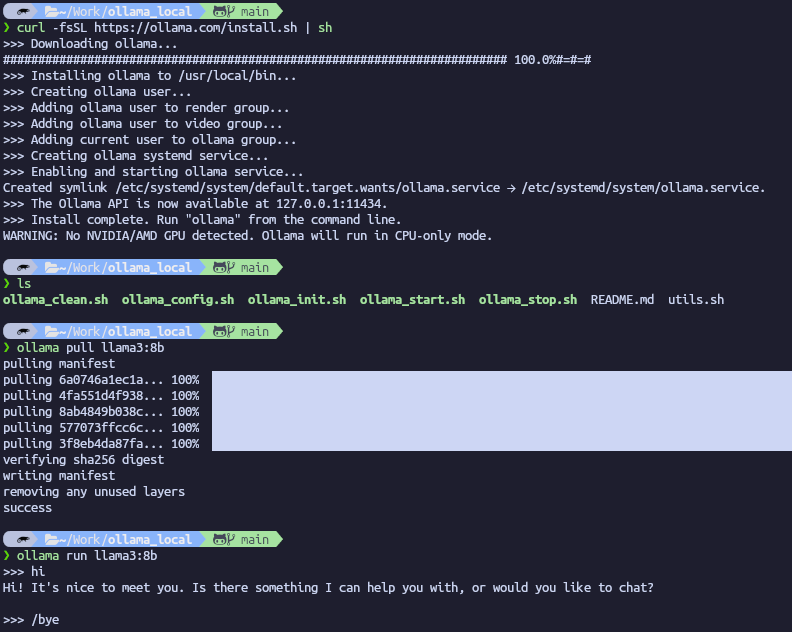
Pour installer et utiliser Ollama :
- Allez sur le site officiel et télécharger la version souhaitée (Linux, Windows or Mac).
- Suivez les instructions d’installation de l’outil
- Ouvrez un terminal
- Exécutez la commande :
Ollama pull llama3:8b(Ou choisissez le model souhaité à partir de la librarie Ollama) - Exécutez la commande :
Ollama run llama3:8b
Note : Si vous n’avez pas de GPU, alors Ollama affichera le warning suivant : No NVIDIA/AMD GPU detected. Ollama will run in CPU-only mode.
Note : utilisez la commande /bye pour terminer le prompt
Configuration de l’extension VS Code Continue
Exemple d’une configuration de VS Code Continue pour utiliser un serveur locale de Ollama :
1{
2 "models": [
3 {
4 "title": "CodeLlama",
5 "provider" : "ollama",
6 "model" : "codellama:7b",
7 },
8 {
9 "title": "Llama3",
10 "provider" : "ollama",
11 "model" : "llama3:8b",
12 }
13 ],
14 "tabAutocompleteModel": {
15 "title": "Starcoder",
16 "provider": "ollama",
17 "model": "starcoder2:3b",
18 },
19 "embeddingsProvider": {
20 "title": "Nomic",
21 "provider": "ollama",
22 "model": "nomic-embed-text",
23 }
24}
Configuration distante
Mise en place de Ollama avec Podman
Objectif : Déployer Ollama sur n’importe quel machine, et plus particulièrement sur une machine avec un ou plusieurs GPU récents, permettant une utilisation optimale à partir de tout ordinateur connecté au même réseau.
Nous utiliserons les paramètres suivants :
- Nom du pod :
llms-pod - Nom du conteneur :
llms-pod-ollama - Modèle Ollama :
llama3:8b - Numéro du port par défaut :
11434
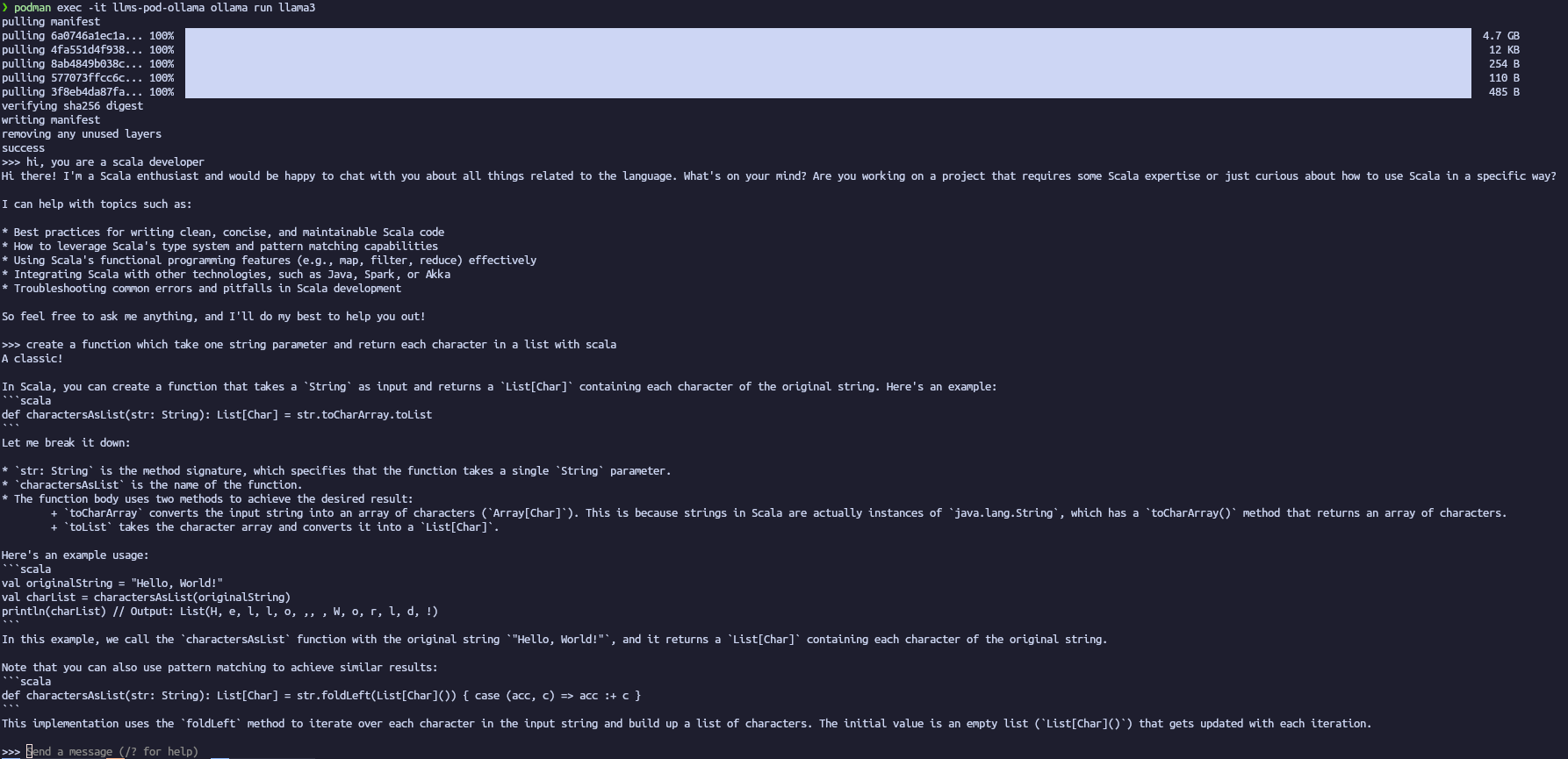
Les étapes à suivre sont les suivantes :
- Création d’un pod avec la définition du port (API) :
podman pod create --name llms-pod -p 11434:11434 - Création d’un conteneur dans le pod créé :
podman run -dt --pod llms-pod --name llms-pod-ollama docker.io/ollama/ollama:latest - Récupération d’un modèle spécifique :
podman exec -it llms-pod-ollama ollama pull llama3:8b - Exécution d’un modèle spécifique :
podman exec -it llms-pod-ollama ollama run llama3:8b`
Note : Vous trouverez des scripts pour gérer le pod plus facilement dans ce dépôt github.
Configuration de l’extension VS Code Continue
Exemple d’une configuration de VS Code Continue pour utiliser un serveur distant de Ollama :
1{
2 "models": [
3 {
4 "title": "CodeLlama",
5 "provider" : "ollama",
6 "model" : "codellama:7b",
7 "apiBase": "http://localhost:11434"
8 },
9 {
10 "title": "Llama3",
11 "provider" : "ollama",
12 "model" : "llama3:8b",
13 "apiBase": "http://localhost:11434"
14 }
15 ],
16 "tabAutocompleteModel": {
17 "title": "Starcoder",
18 "provider": "ollama",
19 "model": "starcoder2:3b",
20 "apiBase": "http://localhost:11434"
21 },
22 "embeddingsProvider": {
23 "title": "Nomic",
24 "provider": "ollama",
25 "model": "nomic-embed-text",
26 "apiBase": "http://localhost:11434"
27 }
28}
Conclusion
Il est très facile d’utiliser des LLMs localement, pour toutes les personnes ayant une attention particulière concernant l’usage de leurs données (vie privée, données sensibles, …) ou n’ayant pas les moyens d’utiliser les offres commerciales, avec Ollama (disponible sur les plateformes Linux, Windows et Mac) et VS Code. Cependant, il est indispensable d’avoir un GPU récent et une quantité de mémoire suffisante pour pouvoir l’utiliser efficacement.