
Databricks : Unity Catalog - First Step - Part 1 - Set up
We are going to discover the Unity Catalog solution from Databricks and more specifically how to set it up on an existing workspace.
We will use a Databricks account on AWS to perform this demonstration.
Note: Work is based on the state of the Unity Catalog solution at the end of Q1 2023 on AWS and Azure.
Introduction
In December 2021, Databricks announced the general availability of SQL Warehouse. This represents an important step in the development of the Lakehouse platform in order to multiply the uses of the data stored in Delta format. Data management was mainly based on Hive Metastore, which had the disadvantage of being local to a Databricks Workspace by default. This meant that it was necessary to redefine the different objects and the management of the rights on the different Workspace Databricks requiring access to the data of the Lakehouse platform.
In order to do the best use of the Lakehouse platform and especially to be able to manage data governance, we were waiting for a Databricks solution to centralize all the metadata at the Databricks Account level and to be able to facilitate the metadata sharing between Databricks Workspaces.
In the late summer 2022, Databricks announced the general availability of the Unity Catalog solution on AWS and on Azure and then in late Q1 2023, the announcement was made on GCP. With these announcements, Unity Catalog has become the default data governance solution for Databricks Lakehouse platform (both on AWS, Azure and GCP).
At the end of summer 2022, Databricks also announced the general availability of Delta Sharing which is an open protocol aiming at sharing in an efficient, simple and secure way the data managed by the Lakehouse platform with third party tools/technologies (Python, Java, Scala, Power BI, and many others) but also with other Databricks Accounts (using or not the Unity Catalog solution)
At the end of 2022, Databricks announced the general availability of the Data Lineage feature. This feature is very important to be able to follow the life cycle of all the data on the Lakehouse platform.
In order to make the Unity Catalog solution accessible to as many people as possible, which is a key solution in the use and management of the Databricks Lakehouse platform, a series of 5 articles has been written in a spirit of discovery (pedagogical) to set up and use the various features of the Unity Catalog solution.
The 45 articles have been organized as follows :
- Databricks : Unity Catalog - First Step - Part 1 - Set up
- Databricks : Unity Catalog - First Step - Part 2 - Data and Rights Management
- Databricks : Unity Catalog - First Step - Part 3 - Data Lineage
- Databricks : Unity Catalog - First Step - Part 4 - Delta Sharing
- Databricks : Unity Catalog - First Step - Part 5 - Delta Live Tables
Please note that the work is based on the state of the Unity Catalog solution at the end of Q1 2023 on AWS and Azure.
We will use the following tools :
What’s a metastore
A metastore is a repository allowing to store a set of metadata related to data (storage, usage, options).
A metadata is an information about a data allowing to define its context (description, rights, technical date and time of creation or update, creator, …) and its usage (storage, structure, access, …).
A metastore can be local to an instance of a resource (a cluster, a workspace) or central to all resources managing data.
In a company with a data governance based on a Data Lake, Datawarehouse or Lakehouse model for example, we will advise to set up a centralized metastore allowing to store all the metadata of the company’s data in order to facilitate the governance, the use and the sharing of the data to all the teams
Wha’s the Unity Catalog solution
Unity Catalog is the Databricks solution that allows to have a unified and centralized governance for all the data managed by the Databricks resources as well as to secure and facilitate the management and the sharing of the data to all the internal and external actors of an organization.
The internal use is done by sharing a metastore of Unity Catalog on all Databricks workspaces.
The external use is done by using the “Delta Sharing” functionality of Unity Catalog or by using the SQL Warehouse functionality through an external tool (JDBC connector, ODC or Databricks partners).
Some examples of features offered by the Unity Catalog solution:
- Management of rights on objects by groups and users using an ANSI SQL syntax
- Management of objects that can be created in a Databricks workspace and used by all Databricks workspaces using Unity Catalog
- Possibility to share data in a simple and secure way through the Delta Sharing functionality
- Allows to capture information on the life cycle and the origin of the data (Data Lineage)
- Capture all logs to be able to audit data access and use
You can get a more complete overview by reading the official documentation
Objects hierarchy
Avant d’aller plus loin, nous allons introduire la hiérarchie des objets au sein de la solution Unity Catalog. Nous allons nous concentrer uniquement sur les éléments nécessaires à la mise en place de la solution Unity Catalog.
We will introduce the object hierarchy within the Unity Catalog solution. We will focus only on the elements that are used in our set up of the Unity Catalog solution.
Diagram of the objects hierarchy :
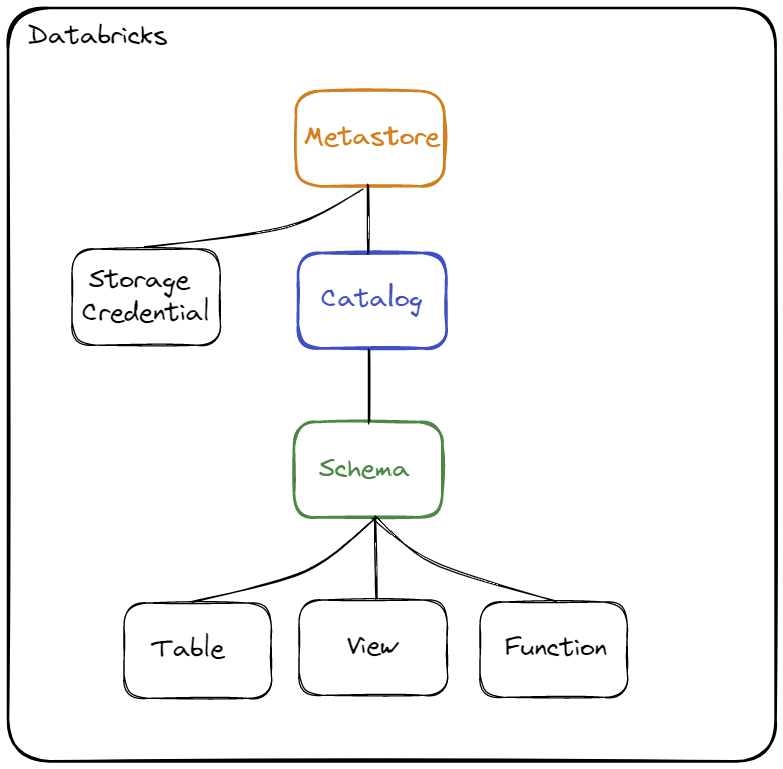
The objects hierarchy consists of the following three levels :
- Metastore :
- It is the top level object that can contain metadata
- There can only be one Metastore per region
- A Metastore must be attached to a Workspace to be used
- The Metastore must have the same region as the Workspace to which it is attached
- Catalog :
- It is the first level of the hierarchy used to organize the data
- It allows to organize objects (data) by schema (also called database)
- If you want to have several environments in the same Metastore (in the same region) then you can create one Catalog per environment
- Schema (or Database) :
- It is the 2nd and last level of the hierarchy used to organize the data
- This level is used to store all the metadata about objects of type Table, View or Function
When you want to access an object (for example a table), it will be necessary to specify the Catalog and Schema where the object is defined.
Example : select ... from catalog.schema.table
Object used by the Unity Catalog solution to manage global access to data :
- Storage Credential : This object is directly associated with the Metastore and used to store access to a cloud provider (for example AWS S3) allowing the Unity Catalog solution to manage the rights on the data.
Objects used by the Unity Catalog solution to store and manage metadata (data usage):
- Table : Object used to define the structure and storage of data.
- Managed Table : The data is directly managed by the Unity Catalog solution and use the format Delta
- External Table : The data is not directly managed by the Unity Catalog solution and can use any of the following formats : “Delta, CSV, JSON, Avro, Parquet, ORC or Text”
- View : Object used to encapsulate a query using one or more objects (table or view)
- Function : Objet used to define user defined function (operations on data)
Some information about object quotas in the Unity Catalog solution:
- A Metastore can contain up to 1000 Catalog
- A Metastore can contain up to 200 Storage Credential
- A Catalog can contain up to 10000 Schema
- A Schema can contain up to 10000 Table and 10000 Function
Context
For this demonstration, we will only focus on the set up of a Metastore of the Unity Catalog solution on a Databricks Account on AWS.
In a project/company context, it is recommended to use the Terraform tool in order to be able to manage the infrastructure as code (IaC) and make the elements reproducible.
In the context of this demonstration, we will deliberately use command lines to make our approach clearer and more didactical.
We will mainly use the following tools:
- Databricks CLI: Command line interface to facilitate the use and configuration of Databricks resources
- AWS CLI: Command line interface to facilitate the use and configuration of AWS resources
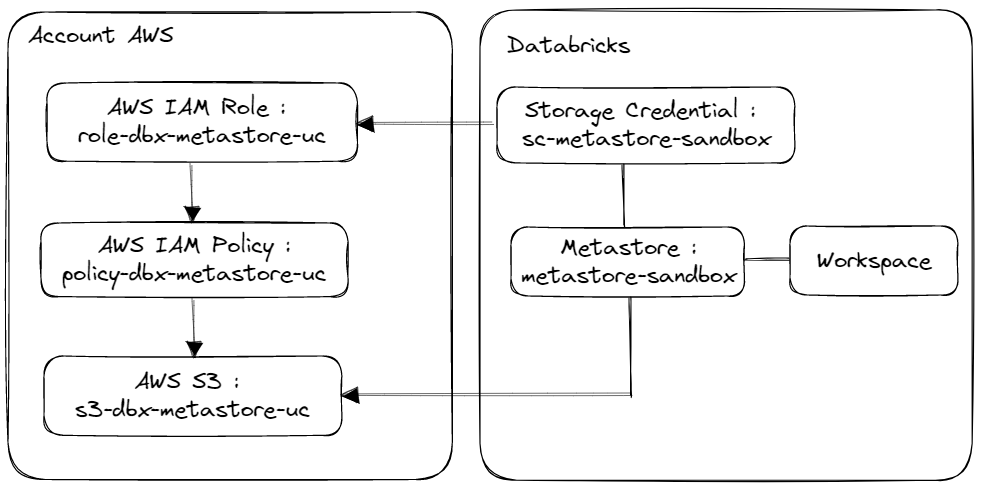
Diagram
Diagram of all the elements that we will put in place to use the Unity Catalog solution with a Databricks Workspace.
Prerequisites
The following items are required before starting the set up :
- The Workspace must be in a Premium plan or higher
- You must have a Databricks Account on AWS
- You must have a Databricks Workspace based on the “eu-west-1” region
- You must have a Databricks user account with administrative rights on the Databricks account
- You must have an AWS user account with administration rights on AWS S3 and AWS IAM resources
In order to use the Databricks CLI and AWS CLI tools you must have created the following elements :
- A Databricks User Token to use Databricks CLI
- An AWS User Token to use AWS CLI Note: You will find the procedure for configuring the AWS CLI and Databricks CLI tools in the resources of this article.
Information about the global Databricks role for managing AWS access through Unity Catalog solution :
- AWS IAM Role Unity Catalog :
arn:aws:iam::414351767826:role/unity-catalog-prod-UCMasterRole-14S5ZJVKOTYTL
Information about le Databricks Workspace ID :
- Based on Databricks Workspace URL :
https://<databricks-instance>.com/o=XXXXX, the workspace ID is the numeric value represented byXXXXX.
Steps
To set up the Unity Catalog solution and create a Metastore, we will perform the following steps :
- Creation of an AWS S3 resource
- Creation of a Policy and a Role to manage the AWS S3 resource with AWS IAM resource
- Creation of a Databricks Metastore
- Creation of a Databricks Storage Credential
- Association of the Databricks Storage Credentiel with the Databricks Metastore
- Association of the Databricks Metastore with the Databricks Workspace
Setting up
Step n°0 : Initialization of environment variables
Creation of environment variables allowing to define the naming of objects and to facilitate the writing of the commands.
1# AWS Variables
2export AWS_S3_DBX_UC="s3-dbx-metastore-uc"
3export AWS_IAM_ROLE_DBX_UC="role-dbx-metastore-uc"
4export AWS_IAM_POLICY_DBX_UC="policy-dbx-metastore-uc"
5export AWS_TAGS='{"TagSet": [{"Key": "owner","Value": "admin"},{"Key": "project","Value": "databricks"}]}'
6
7# Databricks Variables
8export DBX_WORKSPACE_ID="0000000000000000"
9export DBX_METASTORE_NAME="metastor-sandbox"
10export DBX_METASTORE_SC="sc-metastore-sandbox"
11
12
13# AWS Variables to define during the steps executions
14export AWS_IAM_ROLE_DBX_UC_ARN=""
15export AWS_IAM_POLICY_DBX_UC_ARN=""
16
17# Databricks Variables to define during the steps executions
18export DBX_METASTORE_ID=""
19export DBX_METASTORE_SC_ID=""
Step n°1 : Creation of the AWS S3 resource
This AWS S3 resource will be used by Unity Catalog to store “Managed” object data and metadata.
Execute the following commands using the AWS CLI :
1# Bucket creation
2aws s3api create-bucket --bucket ${AWS_S3_DBX_UC} --create-bucket-configuration LocationConstraint=eu-west-1
3# Add Encryption information
4aws s3api put-bucket-encryption --bucket ${AWS_S3_DBX_UC} --server-side-encryption-configuration '{"Rules": [{"ApplyServerSideEncryptionByDefault": {"SSEAlgorithm": "AES256"},"BucketKeyEnabled": true}]}'
5# Revoke public access
6aws s3api put-public-access-block --bucket ${AWS_S3_DBX_UC} --public-access-block-configuration '{"BlockPublicAcls": true,"IgnorePublicAcls": true,"BlockPublicPolicy": true,"RestrictPublicBuckets": true}'
7# Add ownership controls information
8aws s3api put-bucket-ownership-controls --bucket ${AWS_S3_DBX_UC} --ownership-controls '{"Rules": [{"ObjectOwnership": "BucketOwnerEnforced"}]}'
9# Add tags
10aws s3api put-bucket-tagging --bucket ${AWS_S3_DBX_UC} --tagging ${AWS_TAGS}
Étape n°2 : Création d’une politique et d’un rôle avec la ressource AWS IAM
The policy and the role will allow to give administrative rights to the Unity Catalog solution to manage data access on the AWS S3 resource.
Execute the following commands using the AWS CLI :
1
2# Create JSON config file for role creation (init)
3cat > tmp_role_document.json <<EOF
4{
5 "Version": "2012-10-17",
6 "Statement": [
7 {
8 "Effect": "Allow",
9 "Principal": {
10 "AWS": [
11 "arn:aws:iam::414351767826:role/unity-catalog-prod-UCMasterRole-14S5ZJVKOTYTL"
12 ]
13 },
14 "Action": "sts:AssumeRole",
15 "Condition": {
16 "StringEquals": {
17 "sts:ExternalId": "<AWS Account Databricks ID>"
18 }
19 }
20 }
21 ]
22}
23EOF
24
25
26
27# Role creation
28aws iam create-role --role-name ${AWS_IAM_ROLE_DBX_UC} --assume-role-policy-document file://tmp_role_document.json
29# Get the role ARN
30export AWS_IAM_ROLE_DBX_UC_ARN=`aws_ippon_dtl iam get-role --role-name ${AWS_IAM_ROLE_DBX_UC} | jq '.Role.Arn'`
31
32
33
34# Create JSON config file for role update
35cat > tmp_role_document_update.json <<EOF
36{
37 "Version": "2012-10-17",
38 "Statement": [
39 {
40 "Effect": "Allow",
41 "Principal": {
42 "AWS": [
43 ${AWS_IAM_ROLE_DBX_UC_ARN},
44 "arn:aws:iam::414351767826:role/unity-catalog-prod-UCMasterRole-14S5ZJVKOTYTL"
45 ]
46 },
47 "Action": "sts:AssumeRole",
48 "Condition": {
49 "StringEquals": {
50 "sts:ExternalId": "<AWS Account Databricks ID>"
51 }
52 }
53 }
54 ]
55}
56EOF
57
58# Add reference on himself
59aws iam update-assume-role-policy --role-name ${AWS_IAM_ROLE_DBX_UC} --policy-document file://tmp_role_document_update.json
60# Add tags
61aws iam tag-role --role-name ${AWS_IAM_ROLE_DBX_UC} --tags ${AWS_TAGS}
62# Add description
63aws iam update-role-description --role-name ${AWS_IAM_ROLE_DBX_UC} --description 'This role is used for storing Databricks Unity Catalog metadata to S3 Resources'
64
65
66
67
68# Create JSON config file for policy creation
69cat > tmp_policy_document.json <<EOF
70{
71 "Version": "2012-10-17",
72 "Statement": [
73 {
74 "Action": [
75 "s3:GetObject",
76 "s3:PutObject",
77 "s3:DeleteObject",
78 "s3:ListBucket",
79 "s3:GetBucketLocation",
80 "s3:GetLifecycleConfiguration",
81 "s3:PutLifecycleConfiguration"
82 ],
83 "Resource": [
84 "arn:aws:s3:::${AWS_S3_DBX_UC}/*",
85 "arn:aws:s3:::${AWS_S3_DBX_UC}"
86 ],
87 "Effect": "Allow"
88 },
89 {
90 "Action": [
91 "sts:AssumeRole"
92 ],
93 "Resource": [
94 ${AWS_IAM_ROLE_DBX_UC_ARN}
95 ],
96 "Effect": "Allow"
97 }
98 ]
99}
100EOF
101
102# Policy creation
103aws iam create-policy --policy-name ${AWS_IAM_POLICY_DBX_UC} --policy-document file://tmp_policy_document.json > tmp_result_creation_policy.json
104# Get Policy ARN
105export AWS_IAM_POLICY_DBX_UC_ARN=`cat tmp_result_creation_policy.json | jq '.Policy.Arn'`
106# Add tags
107aws iam tag-policy --policy-arn ${AWS_IAM_POLICY_DBX_UC_ARN} --tags ${AWS_TAGS}
108
109
110# Attach Policy to the Role
111aws iam attach-role-policy --role-name ${AWS_IAM_ROLE_DBX_UC} --policy-arn ${AWS_IAM_POLICY_DBX_UC_ARN}
112
113
114# Delete temporary JSON files
115rm tmp_role_document_update.json
116rm tmp_role_document.json
117rm tmp_policy_document.json
118rm tmp_result_creation_policy.json
Step n°3 : Creation of a Metastore
Create a Unity Catalog Metastore in the same region as the Workspace we want to use it with.
Execute the following commands using the Databricks CLI :
1# Create metastore
2databricks unity-catalog metastores create --name ${DBX_METASTORE_NAME} \
3 --storage-root s3://${AWS_S3_DBX_UC}/${DBX_METASTORE_NAME}
4
5
6# Get the metastore ID
7export DBX_METASTORE_ID=`databricks unity-catalog metastores get-summary | jq 'select(.name == $ENV.DBX_METASTORE_NAME) | .metastore_id'`
8
9# Check the metastore ID (it must not be empty)
10echo ${DBX_METASTORE_ID}
Step n°4 : Creation of a Storage Credential
Created a Storage Credential to store access for the global Databricks role on the AWS S3 resource used to store Metastore data.
Execute the following commands using the Databricks CLI :
1# Create JSON config file
2cat > tmp_databricks_metastore_storagecredential.json <<EOF
3{
4 "name": ${DBX_METASTORE_SC},
5 "aws_iam_role": {
6 "role_arn": ${AWS_IAM_ROLE_DBX_UC_ARN}
7 },
8 "comment" : "Storage Credential for Unity Catalog Storage"
9}
10EOF
11
12# Create Storage Credential
13databricks unity-catalog storage-credentials create --json-file tmp_databricks_metastore_storagecredential.json
14
15# Get Storage Credential ID
16export DBX_METASTORE_SC_ID=`databricks unity-catalog storage-credentials get --name ${DBX_METASTORE_SC} | jq '.id'`
17
18# Delete temporary files
19rm tmp_databricks_metastore_storagecredential.json
Step n°5 : Association of the Databricks Storage Credentiel with the Databricks Metastore
In order for the Metastore to use the Storage Credential to access the AWS S3 resource and to be able to manage access on the data for all users, we need to associate the Storage Credential with the Metastore.
Execute the following commands using the Databricks CLI :
1# Create JSON config file
2cat > tmp_databricks_metastore_update_sc.json <<EOF
3{
4 "default_data_access_config_id": ${DBX_METASTORE_SC_ID},
5 "storage_root_credential_id": ${DBX_METASTORE_SC_ID}
6}
7EOF
8
9# Update Metastore with the Storage Credential
10databricks unity-catalog metastores update --id ${DBX_METASTORE_ID} \
11 --json-file tmp_databricks_metastore_update_sc.json
12
13# Delete temporary files
14rm tmp_databricks_metastore_update_sc.json
Step n°6 : Association of the Databricks Metastore with the Databricks Workspace
To be able to use the Metastore with a Databricks Workspace, it is necessary to assign the Metastore to the Databricks Workspace at the Databricks account level. Note: it is possible to define the name of the Catalog by default for the users of the Workspace.
Execute the following commands using the Databricks CLI :
1databricks unity-catalog metastores assign --workspace-id ${DBX_WORKSPACE_ID} \
2 --metastore-id ${DBX_METASTORE_ID} \
3 --default-catalog-name main
Step n°7 : Cleaning of environment variables
We can unset all the environment variables used when setting up Unity Catalog solution.
1# Clean the AWS & Databricks Attributes
2unset AWS_S3_DBX_UC
3unset AWS_IAM_ROLE_DBX_UC
4unset AWS_IAM_POLICY_DBX_UC
5unset AWS_TAGS
6unset DBX_WORKSPACE_ID
7unset DBX_METASTORE_NAME
8unset DBX_METASTORE_SC
9unset AWS_IAM_ROLE_DBX_UC_ARN
10unset AWS_IAM_POLICY_DBX_UC_ARN
11unset DBX_METASTORE_ID
12unset DBX_METASTORE_SC_ID
Conclusion
With the help of the Databricks CLI and AWS CLI tools, we were able to easily set up a Metastore on our Databricks Workspace in order to use the Unity Catalog solution.
This allowed us to easily set up a solution to manage our centralized metadata repository for all the data managed and manipulated by our Databricks resources (Cluster and SQL Warehouse).
Les avantages de l’utilisation de la solution Unity Catalog :
- Unity Catalog permet de simplifier et centraliser la gestion des droits sur l’ensemble des objets gérés.
- Unity Catalog permet de sécuriser, faciliter et multiplier les usages sur les données grâce aux nombreux connecteurs pour SQL Warehouse ainsi que la possibilité d’exporter les informations vers d’autres outils de gestion de catalogue de données.
- Unity Catalog est un outil qui s’améliore régulièrement et qui devrait devenir la référence pour la gouvernance des données pour toutsceux qui utilisent Databricks.
The advantages of using the Unity Catalog solution :
- Unity Catalog simplifies and centralizes the management of rights on all managed objects.
- Unity Catalog allows you to secure, facilitate and multiply the usages of data by using the numerous connectors for SQL Warehouse as well as the possibility of exporting information to other data catalog management tools.
- Unity Catalog is a tool that is regularly improved and that should become the reference for data governance for all those who use Databricks.
Some information about the limitations on the Unity Catalog solution:
- The Workspace must be at least at the premium plan to use Unity Catalog
- A Metastore must contain all the elements concerning a region.
- It is recommended to use a cluster with Databricks Runtime version 11.3 LTS or higher
- The creation of a Storage Credential is only possible with an AWS IAM role when the Databricks Account is on AWS
- Part of the management of users and groups must be done at the account level and not only at the workspace level
- The groups defined locally in a workspace cannot be used with Unity Catalog, it is necessary to recreate the groups at the Databricks account level to be used by Unity Catalog (Migration).
Resources
Glossary
- Account Databricks : Highest level for Databricks administration
- Cluster Databricks : A set of computational resources for running Spark processing with Databricks
- Databricks Workspace ID : Identifier of the Databricks workspace
- Storage Credential : Object used to store the access for the Unity Catalog solution
- Data Lake : Used to store structured, semi-structured and unstructured data
- Data Warehouse : Used to store structured data (relational database)
- Lakehouse : Data management architecture that combines the benefits of a Data Lake with the management capabilities of a Data Warehouse
- AWS S3 : AWS Simple Storage Service for storing data/objects
- AWS IAM : AWS Identity and Access Management Service to control access to AWS services and resources.
Connection management for the AWS CLI tool
Install the tool
AWS CLIon macOS with Homebrewbrew install awscliDefine a specific user for AWS CLI :
- Go to
IAM > Users - Click on
Add users - Fill the “User Name” :
usr_adm_cliand click onNext - If you have an admin group defined :
- Choose
Add user to group - Choose the desired group name :
FullAdminand click onNext
- Choose
- If you have a policy defined :
- Choose
Attach policies directly - Choose the desired policy name :
AdministratorAccessand click onNext
- Choose
- If you need to define Tag : Click on
Add new tagand add the needed tag - Click on
Create user - Click on the created user
usr_adm_cli - Click on
Security credentials - Click on
Create access key - Choose
Command Line Interface (CLI), check the boxI understand the above .... to proceed to create an access keyand click onNext - Fill the
Description tag value:administrationand click onCreate access key - Copy the
Access keyand theSecret access keyto be able to use it with AWS CLI
- Go to
Create configuration for AWS CLI to use the new user :
- Execute the command :
aws configure- Fill
AWS Access Key IDwith theAccess keyof the new userusr_adm_cli - Fill
AWS Secret Access Keywith theSecret access keyof the new userusr_adm_cli - Fill
Default region namewith the default location :eu-west-1 - Fill
Default output formatwith the default output formatjson
- Fill
- Execute the command :
Check the AWS CLI configuration
- Execute the commande
aws s3api list-buckets - Result :
- Execute the commande
1{
2 "Buckets": [
3 {...}
4 ]
5}
Connection management for the Databricks CLI tool
Install the tool
Databricks CLIwithpip(requires python3)- Execute the command :
pip install databricks-cli - Check the result with the command :
databricks --version(Result :Version 0.17.6)
- Execute the command :
Create a Databricks Token
- Go to your Databricks workspace
- Click on your user and click on
User Settings - Click on
Access tokens - Click on
Generate new token - Fill the comment and define the token life time
- Click on
Generate - Copy the Databricks Token to be able to use it with Databricks CLI
Configure Databricks CLI
- Execute the command :
databricks configure --token - Fill the
Databricks Host (should begin with https://):with your workspace url :https://dbc-0a000411-23e7.cloud.databricks.com - Fill the
Access Tokenwith the Databricks Token created :dapi2c0000aa000a0r0a00e000000000000
- Execute the command :
You can see your credential with the commandcat ~/.databrickscfg