
Databricks : Unity Catalog - First Step - Part 2 - Data and Rights Management
We are going to discover the data management with the Unity Catalog solution and more precisely the management of rights (Groups and Users) and storage (Tables).
We will use a Databricks Account on AWS to perfrom this discovery.
Note: Work is based on the state of the Unity Catalog solution at the end of Q1 2023 on AWS and Azure.
Unity Catalog and the object hierarchy
Unity Catalog is the Databricks solution that allows to have a unified and centralized governance for all the data managed by the Databricks resources as well as to secure and facilitate the management and the sharing of the data to all the internal and external actors of an organization.
You can get a more complete overview by reading the official documentation
Reminder concerning the hierarchy of objects :
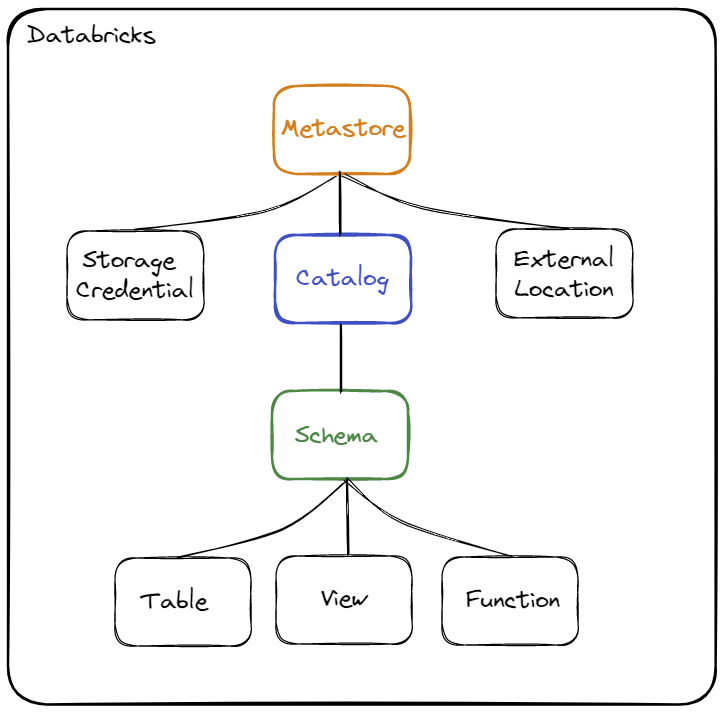
The objects are :
- Storage Credential : This object is directly associated with the Metastore and is used to store access to a cloud provider (for example AWS S3) allowing the Unity Catalog solution to manage data rights
- External Location : This object is associated with the Metastore and allows you to store the path to a cloud provider (for example an AWS S3 resource) in combination with a Storage Credential to manage data access
- Metastore : Top-level object that can contain metadata
- Catalog : 1st level object allowing to organize data by Schema (also called Database)
- Schema : 2nd and last level object used to organize data (contains tables, views and functions)
- Table : Object used to define the structure and storage of data..
- View : Object used to encapsulate a query using one or more objects (table or view)
- Function : Object allowing to define operations on the data
When you want to access an object (for example a table), it will be necessary to use the name of the Catalog and the name of the Schema where the object is defined.
Example : select * from catalog.schema.table
Set-up the environment
For this discovery, we are going to set up a certain number of elements to be able to handle the different concepts.
Synthesis
Regarding Databricks resources :
- The Unity Catalog solution must be activated at the Databricks Account level
- A Unity Catalog Metastore must be attached to the Databricks Workspace
- A SQL Warehouse must exist in the Databricks Workspace
Regarding groups and users,
We will use the following elements:
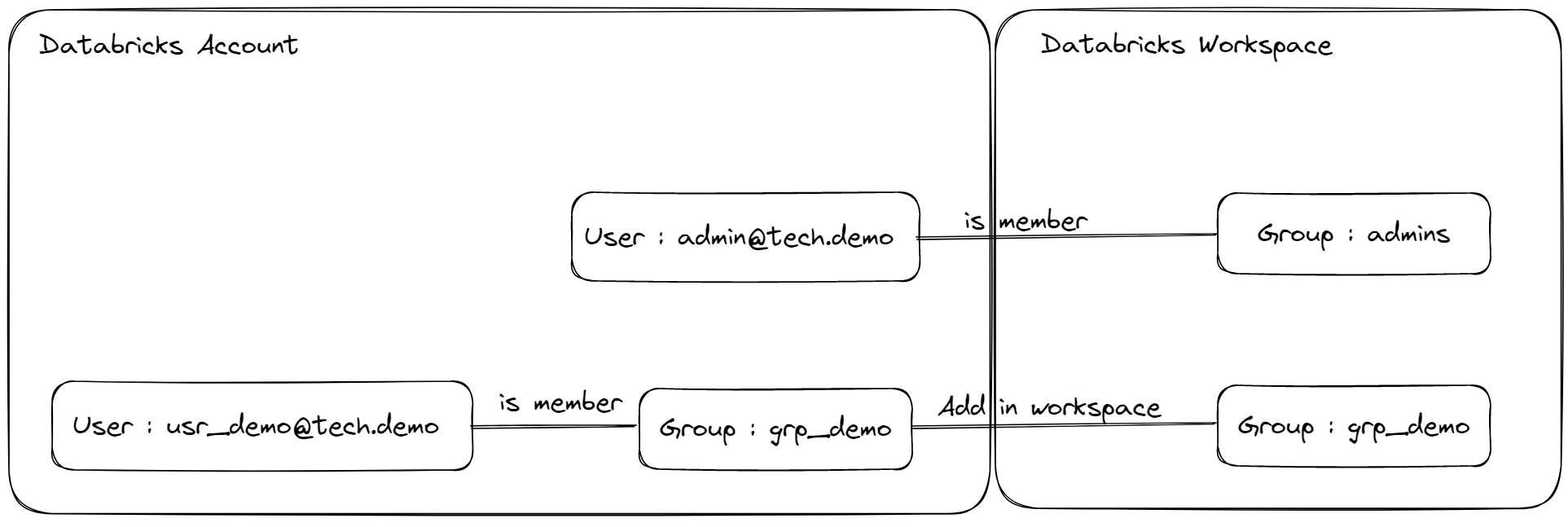
Prerequisites :
- A user with admin rights on the Databricks Account and on the Databricks Workspace
- There must not exist a group named
grp_demoat the Databricks Account level and at the Databricks Workspace level - There must not exist a user named
john.do.dbx@gmail.comat the Databricks Account level and at the Databricks Workspace level
Summary of the actions that will be done :
- Creation of a group named
grp_demoat the Databricks Account level. - Creation of a user named
john.do.dbx@gmail.comat the Databricks Account level. - Addition of the
grp_demogroup created at the Databricks Account level in the Databricks Workspace - Added rights on the Workspace Databricks on the group
grp_demo - Added the needed rights on Unity Catalog objects at the Databricks Workspace level on the
grp_demogroup
Regarding Unity Catalog objects,
We will use the following elements:
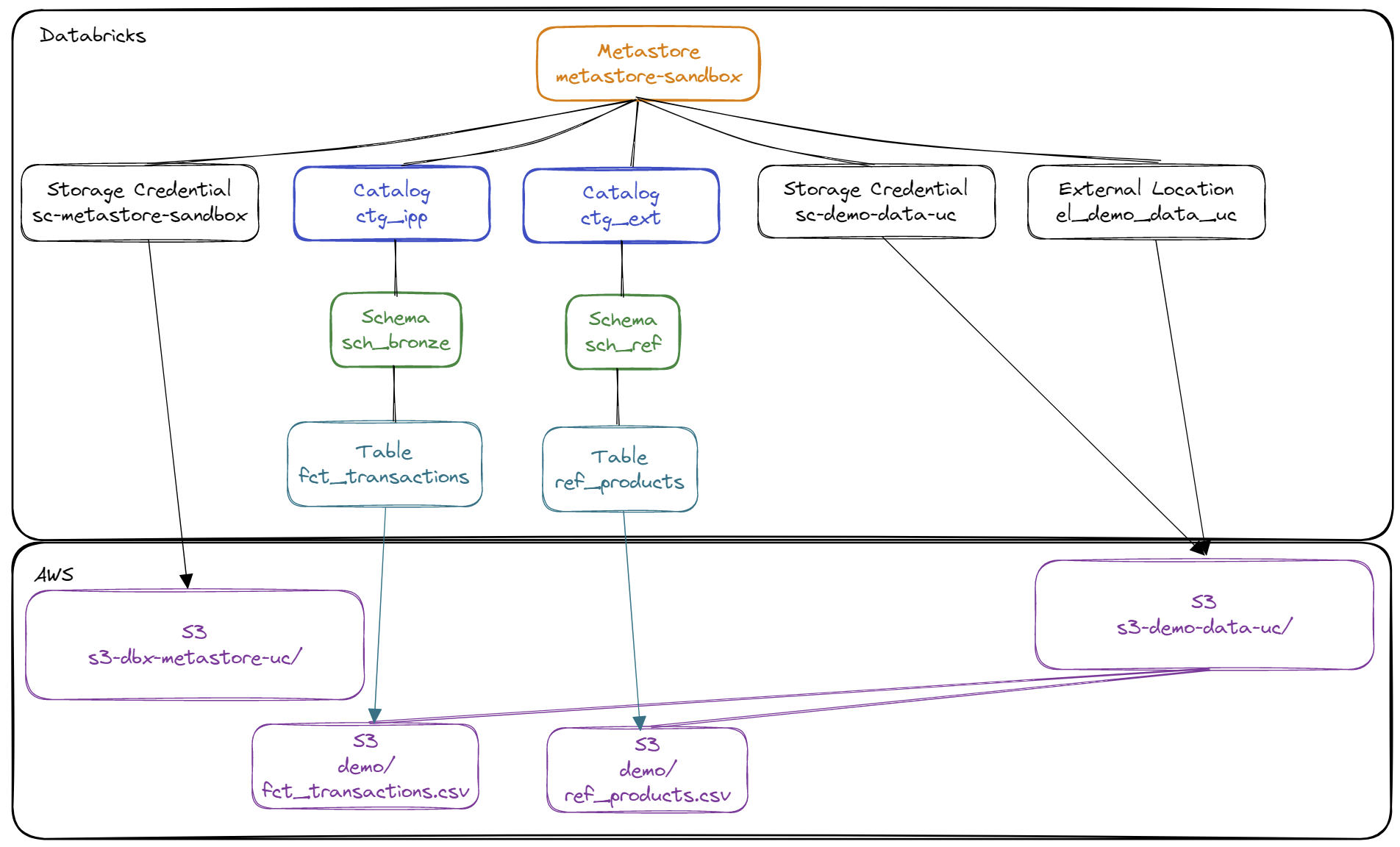
Prerequisites :
- Existence of a Metastore named
metastore-sandboxwith the Storage Credential namedsc-metastore-sandboxto store default data in the AWS S3 resource nameds3-dbx-metastore-uc - Create an AWS S3 resource named
s3-demo-data-uc - Created an AWS IAM role named
role-databricks-demo-data-ucand an AWS IAM policy namedpolicy-databricks-demo-data-ucallowing the Databricks global role to manage access to the AWS S3 resources3-demo-data-uc - Created a Storage Credential named
sc-demo-data-ucallowing the Databricks global role to manage access to the AWS S3 resources3-demo-data-uc
Summary of the actions that will be done :
- Creation of an External Storage to be able to access the data of the AWS S3 resource named
s3-demo-data-ucwith Unity Catalog - Creation of the Catalog
ctg_ippwhich will contain all the managed elements (stored on the AWS S3 resource nameds3-dbx-metastore-ucassociated with the Metastoremetastore-sandbox) - Creation of the Catalog
ctg_extwhich will contain all the external elements (stored on the AWS S3 resource nameds3-demo-data-uc) - Creation of the Schema
ctg_ipp.sch_bronzewhich will create objects managed by Unity Catalog to access data stored on the AWS S3 resource nameds3-dbx-metastore-uc(in Delta format only) - Creation of the Schema
ctg_ext.sch_refwhich will create the objects to access the data stored on the AWS S3 resource nameds3-demo-data-uc(in the form of a CSV file or a Delta file)
Setting up
Setting up a dataset on the AWS S3 resource
Content of the file ref_products.csv:
1id,lib,brand,os,last_maj
21,Pixel 7 Pro,Google,Android,2023-01-01 09:00:00
32,Iphone 14,Apple,IOS,2023-01-01 09:00:00
43,Galaxy S23,Samsung,Android,2023-01-01 09:00:00
Content of the file fct_transactions.csv :
1id_trx,ts_trx,id_product,id_shop,id_client,quantity
21,2023-04-01 09:00:00,1,2,1,1
32,2023-04-01 11:00:00,1,1,1,3
43,2023-04-03 14:00:00,1,2,1,1
54,2023-04-05 08:00:00,3,1,2,9
65,2023-04-06 10:00:00,1,2,1,3
76,2023-04-06 12:00:00,2,2,1,1
87,2023-04-10 18:30:00,2,1,2,11
98,2023-04-10 18:30:00,3,1,2,2
Copying data to the demo directory of the AWS S3 resource named s3-demo-data-uc with the AWS CLI tool :
1aws s3 cp ref_products.csv s3://s3-demo-data-uc/demo/ref_products.csv
2aws s3 cp fct_transactions.csv s3://s3-demo-data-uc/demo/fct_transactions.csv
Setting up the containers on the Unity Catalog Metastore
The steps are as follows : Note: Using a user with admin rights on the Metastore
- Creating of an External Location to allow users to store data into the AWS S3 resource named
s3-demo-data-uc - Creating a Catalog
ctg_ippandctg_ext - Creating a Schema
ctg_ipp.sch_bronzeandctg_ext.sch_ref
1-- 1. Create external location to access data from s3-demo-data-uc resource
2CREATE EXTERNAL LOCATION IF NOT EXISTS el_demo_data_uc
3URL 's3://s3-demo-data-uc'
4WITH (STORAGE CREDENTIAL `sc-demo-data-uc`)
5COMMENT 'External Location to access demo data';
6
7-- 2. Create Catalog ctg_ipp
8CREATE CATALOG IF NOT EXISTS ctg_ipp
9 COMMENT 'Catalog for managed data';
10
11-- 2. Create Catalog ctg_ext (for external data)
12CREATE CATALOG IF NOT EXISTS ctg_ext
13 COMMENT 'Catalog for external data'
14;
15
16-- 3. Create Schema sch_bronze in the Catalog ctg_ipp to store managed data
17CREATE SCHEMA IF NOT EXISTS ctg_ipp.sch_bronze
18 COMMENT 'Schema for Bronze Data'
19;
20
21-- 3. Create Schema sch_ref in the Catalog ctg_ext to store external data
22CREATE SCHEMA IF NOT EXISTS ctg_ext.sch_ref
23 COMMENT 'Schema for External Data'
24;
Group management
Synthesis
A group is an object used to manage access rights on users or other groups. This allow to set up an access organization in relation to teams or profiles rather than going directly through users.
There are two types of groups :
- A group at the Account Databricks level makes it possible to manage access to data using the Unity Catalog solution (centralization)
- A local group at Workspace Databricks level allows to manage access at workspace level only and is not compatible with Unity Catalog solution (this is mainly used with Hive Metastore and for Workspace Databricks rights)
Quota : You can have up to a combination of 10,000 users and 5,000 groups in a Databricks Account
When a Unity Catalog Metastore is attached to a Databricks Workspace, it is no longer possible to create a local group directly from the Databricks Workspace interface.
In the context of access management with Unity Catalog, the recommendations are as follows:
- Manage all rights based on the groups defined at the Databricks Account level
- The creation of a group must be done at the level of the Databricks Account to be added at the level of a Databricks Workspace
- Adding or removing a member (user or group) from a group must be done at the Databricks Account level
- The creation of a user can be done at the Databricks Workspace level. It will be automatically added at the Databricks Account level (Warning: it is strongly recommended to manage users and groups based on an IdP (Identity provider) (Azure Active Directory, AWS IAM, …) to have a centralized and secure Databricks accounts management)
- Data access management is done at the Databricks Workspace level (by the Databricks Workspace administrator or the object owner)
- It is recommended to always define rights at groups level and not users level to facilitate the management of rights over time
- You can manage groups on several levels to organize rights and users
- When importing (creating) a group at the Workspace Databricks level, the Workspace administrator must define the rights (Entitlements) of the group on the Workspace Databricks
- If you want to give the same rights as the user
john.do.dbx@gmail.comto another user, you will only need to add this other user in the same groups as the userjohn.do.dbx@gmail.com
Regarding a group deletion :
- If you delete the group from the Databricks Workspace, it will still exist at the Databricks Account level
- If you remove the group from the Databricks Account, it will automatically be removed from all Databricks Workspaces
Practical application
Prerequisites :
- Have an account with the Databricks Account administration role/right
- Have an account with the Databricks Workspace administration role/right
- Have an existing SQL Warehouse on the Databricks Workspace (so users can run SQL queries on Databricks)
For the creation of the group and the user, the following actions must be done at the Databricks Account level:
- Create a user named
john.do.dbx@gmail.com - Create a group named
grp_demoand add the userjohn.do.dbx@gmail.comto the groupgrp_demo
For the user to be able to access the Databricks Workspace resources, the following actions must be done at the Databricks Workspace level:
3. Importing the grp_demo group into the Databricks Workspace
4. Add Databricks Workspace-level rights to the group
Actions :
- Step n°1
- Go to
Account Administration page > User Management > Users - Click on
Add User - Fill the informations
Email,First nameandLast nameand click onSend invite
- Go to
- Step n°2
- Go to
Account Administration page > User Management > Groups - Click on
Add Group - Fill the information
Group nameand click onsave - Click on
Add membersto add the userjohn.do.dbx@gmail.com
- Go to
- Step n°3
- Go to
Workspace page > username > Admin Settings > Groups - Click on
Add Group - Choose the group (from the list of existing groups at the Databricks Account level) and click on
Add
- Go to
- Step n°4 :
- Go to
Workspace page > username > Admin Settings > Groups - Click on the group
- Click on
Entitlements- Check the
Workspace accessoption to give acces to the Databricks Workspace to all group users - Check the
Databricks SQL accessoption to give acces to the SQL resources on Databricks Workspaces to all group users
- Check the
- Go to
If you want to give access to a SQL Warehouse to a group, follow these steps:
- Go to
Workspace page > SQL > SQL Warehouses - Click on the button with 3 dots and choose the
Permissionsoption - Add the groupe and choose
Can useoption
Note: It is also possible to add the group at the Databricks Workspace level with the Databricks CLI tool
1# Add a group in the Workspace Databricks (the group must exist at the Account Databricks level)
2databricks groups create --group-name "grp_demo"
Rights management
Synthesis
Rights management is done based on the ANSI SQL syntax and more specifically with the instructions GRANT and REVOKE.
You will find an exhaustive list of the rights that can be managed with Unity Catalog on the official documentation
To give a right to a group or a user, the syntax is the following :
1GRANT <Rights with comma separator> ON <Type Object> <Name Object> TO <Group or User>;
To delete a right from a group or a user, the syntax is the following :
1REVOKE <Rights with comma separator> ON <Type Object> <Name Object> FROM <Group or User>;
Note: It is mandatory to have the right USE/USAGE on the Catalog and the Schema to access a table even if you already have the right SELECT on it, otherwise the user (or the group ) will not be able to see the contents of the Catalog and Schema by default.
For example: If the owner of the table ctg_ext.sch_ref.tbl_demo gives the right SELECT to the group grp_demo then the users of the group grp_demo will not be able to read the data of the table tbl_demo as long as they will not have the USE right on the Catalog ctg_ext and on the Schema sch_ref.
It is possible to manage the rights at the object (table/view) level but it is recommended to organize the data and the rights at the Schema level when the organization allows it to facilitate the management of the access rights to the different teams and profiles of the organization.
Practical application
We have already created the Catalogs and Schemas with an admin account and we want to give the possibility to the user john.do.dbx@gmail.com to manage the objects in the different Catalogs and Schemas.
By default, the grp_demo group has no rights to the Metastore Catalogs (and cannot view them).
We will do the necessary actions to ensure that the rights will be sufficient to be able to perform the following manipulations:
- Creation of new schemas in the Catalog
ctg_ipp - Creation of tables in all Schema of Catalog
ctg_ippandctg_ext
The actions to be done are the following :
- Give use rights on Catalogs
1-- Right to view the Catalog ctg_ipp
2GRANT USAGE ON CATALOG ctg_ipp TO grp_demo;
3-- Right to view the Catalog ctg_ext
4GRANT USAGE ON CATALOG ctg_ext TO grp_demo;
- Give schema creation rights at Catalog level
ctg_ipp
1-- Right to create new Schema in Catalog ctg_ipp
2GRANT USE SCHEMA, CREATE SCHEMA ON CATALOG ctg_ipp TO grp_demo;
- Give permissions to access and create objects in the Schema
ctg_ext.sch_refas well as permissions to create External Tables based on the storage defined in the External Location object namedel_demo_data_uc:
1-- Rights to create objects in the Schema ctg_ext.sch_ref
2GRANT USE SCHEMA, SELECT , MODIFY, CREATE TABLE ON SCHEMA ctg_ext.sch_ref TO grp_demo;
3-- Right to create External tables with the External Location
4GRANT CREATE EXTERNAL TABLE ON EXTERNAL LOCATION `el_demo_data_uc` TO grp_demo;
- Grant all rights on Schema
ctg_ipp.sch_bronze
1-- All privileges on the Schema ctg_ipp.sch_bronze
2GRANT ALL PRIVILEGES ON SCHEMA ctg_ipp.sch_bronze TO grp_demo;
If you want a user to be able to create the External Location object to set up access to a new AWS S3 resource, you must give him the following rights:
1-- Right on the Metastore for the group
2GRANT CREATE EXTERNAL LOCATION ON METASTORE TO grp_demo;
3-- Right on the Storage Credential to the group
4GRANT CREATE EXTERNAL LOCATION ON STORAGE CREDENTIAL `sc-demo-data-uc` TO grp_demo;
Example of queries to retrieve all the rights given to the grp_demo group on the objects of the Catalog ctg_ipp and ctg_ext:
1-- How to get all the existing privileges for a group ?
2-- Get privileges from Catalog
3select 'GRANT '||replace(privilege_type,'_',' ')||' ON CATALOG '||catalog_name||' TO '||grantee||';' as grant_query
4from system.INFORMATION_SCHEMA.CATALOG_PRIVILEGES
5where grantee='grp_demo'
6 and grantor <> 'System user'
7 and catalog_name in ('ctg_ipp','ctg_ext')
8 and inherited_from = 'NONE'
9order by catalog_name,privilege_type
10;
11
12-- Get privileges from Schema
13select 'GRANT '||replace(privilege_type,'_',' ')||' ON SCHEMA '||catalog_name||'.'||schema_name||' TO '||grantee||';' as grant_query
14from system.INFORMATION_SCHEMA.SCHEMA_PRIVILEGES
15where grantee='grp_demo'
16 and grantor <> 'System user'
17 and catalog_name in ('ctg_ipp','ctg_ext')
18 and inherited_from = 'NONE'
19order by catalog_name, schema_name,privilege_type;
20
21-- Get privileges from Table
22select 'GRANT '||replace(privilege_type,'_',' ')||' ON TABLE '||table_catalog||'.'||table_schema||'.'||table_name||' TO '||grantee||';' as grant_query
23from system.INFORMATION_SCHEMA.TABLE_PRIVILEGES
24where grantee = 'grp_demo'
25 and grantor <> 'System user'
26 and table_catalog in ('ctg_ipp','ctg_ext')
27 and inherited_from = 'NONE'
28order by table_catalog,table_schema,table_name,privilege_type;
Storage management
Synthesis
The Table object is used to define the structure and storage of data.
Tables and views must be created in a Schema.
By default, if nothing is specified when creating the Catalog and Schema objects, all the data will be managed by Unity Catalog based on the storage (AWS S3 resource) defined at the Metastore level.
If the MANAGED LOCATION option is defined at the Catalog level then all the children elements (Schema and Table) will use this default storage option instead of the storage defined at the Metastore level.
If the MANAGED LOCATION option is defined at the Schema level then all the children elements (Table) will use this default storage option instead of the storage defined at the Metastore level.
Syntax example :
1-- Catalog creation
2CREATE CATALOG XXX
3 MANAGED LOCATION 's3://YYYYYYYYY'
4 COMMENT 'ZZZZZZZZ'
5;
6
7-- Schema creation
8CREATE SCHEMA XXX
9 MANAGED LOCATION 's3://YYYYYYYYY'
10 COMMENT 'ZZZZZZZZ'
11;
Schema and Catalog are just logical container for organizing data. There is no directory creation when creating these objects.
There are two types of tables:
- Managed Table: Metadata and data are managed by Unity Catalog and the storage format used is the Delta format.
- External Table: Only metadata is managed by Unity Catalog. The storage format can be one of the following formats “Delta, CSV, JSON, Avro, Parquet, ORC or Text”
Regarding Managed Table:
- When a Managed Table is created, the data is created in a sub-directory of the storage defined at the Metastore level (in the case where the “MANAGED LOCATION” option is not defined at the Catalog or parent Schema level )
- The path will be the following
<Metastore S3 Path>/<Metastore ID>/tables/<table ID>,- Example:
s3://s3-dbx-metastore-uc/metastore-sandbox/13a746fa-c056-4b32-b6db-9d31c0d1eecf/tables/5c725019-fe8f-4778-a97c-c640eaf9b13e- Metastore S3 Path:
s3-dbx-metastore-uc - Metastore ID:
13a746fa-c056-4b32-b6db-9d31c0d1eecf - Table ID:
5c725019-fe8f-4778-a97c-c640eaf9b13e
- Metastore S3 Path:
- From the storage point of view, all the managed tables at the Metastore level will be found by default in the
tables/directory with a unique identifier defined when they are created.
- Example:
- When deleting the table, metadata as well as data (files) will be deleted
Regarding the External Table :
When creating an External Table, you must define the data full access path (Unity Catalog manages rights based on a Storace Credential object and an External Location object)
- If files already exist, the definition of the table (source data format, schema, etc.) must be compatible with the existing data
- If no file exists, the Delta format log elements will be created in the
_log_deltasubdirectory of the defined path and the data files will be created when adding data to the table
When deleting the table, only metadata is deleted. The data (files) are not impacted by the deletion.
Some limitations:
- If the table is based on a csv file, no action other than reading will be allowed
- If the table is based from data (files) in CSV format (or other format outside Delta) (written by spark processing for example), it will be possible to make insert but not update or delete
- If the table is based from data in Delta format then it will be possible to do exactly the same actions as with a Managed Table
- It is not possible to define two different external tables using exactly the same data files path as external storage
Practical application
Creating an External Table and a Managed Table :
- Creation of an External Table named
ref_productsin the Schemasch_refof the Catalogctg_extfrom a csv file namedref_products.csv - Creation of an Managed Table named
fct_transactionsin the Schemasch_bronzeof the Catalogctg_ipp - Insertion of data into the
fct_transactionstable from a CSV file namedfct_transactions.csv
1-- 1. Creation of external table ref_products
2CREATE TABLE ctg_ext.sch_ref.ref_products (
3 id int
4 ,lib string
5 ,brand string
6 ,os string
7 ,last_maj timestamp
8)
9USING CSV
10OPTIONS (path "s3://s3-demo-data-uc/demo/ref_products.csv",
11 delimiter ",",
12 header "true")
13COMMENT 'Product referential (external)'
14;
15
16
17-- 2. Creation of managed table fct_transactions
18CREATE TABLE ctg_ipp.sch_bronze.fct_transactions (
19 id_trx string
20 ,ts_trx string
21 ,id_product string
22 ,id_shop string
23 ,id_client string
24 ,quantity string
25)
26COMMENT 'Bronze Transactions Data'
27;
28
29
30-- 3. Insert data from CSV files into the fct_transactions table
31COPY INTO ctg_ipp.sch_bronze.fct_transactions
32 FROM 's3://s3-demo-data-uc/demo/fct_transactions.csv'
33 FILEFORMAT = CSV
34 FORMAT_OPTIONS ('encoding' = 'utf8'
35 ,'inferSchema' = 'false'
36 ,'nullValue' = 'N/A'
37 ,'mergeSchema' = 'false'
38 ,'delimiter' = ','
39 ,'header' = 'true'
40 ,'mode' = 'failfast')
41;
Example of an error when updating data from an External Table based on a CSV file
4. Updating ref_products table data in error
5. Deleting data from the ref_products table in error
1-- 4. Error : Try to update the data in the ref_products table
2UPDATE ctg_ext.sch_ref.ref_products
3SET last_maj = current_timestamp()
4WHERE id = 1;
5-- Result : UPDATE destination only supports Delta sources
6
7
8-- 5. Error : Try to delete the data from ref_products table
9DELETE FROM ctg_ext.sch_ref.ref_products
10WHERE id = 1;
11-- Result : Could not verify permissions for DeleteFromTable
Example of data storage management for an External Table (in Delta format) when it is created and deleted:
6. Creating an external table with the appendOnly property
7. Checking the list of files on the AWS S3 resource
8. Inserting data through the Metastore Unity Catalog
9. Checking the list of files on the AWS S3 resource
10. Reading the Delta Data History
11. Deleting data without using the Metastore Unity Catalog table (the appendOnly property blocks the execution of this action)
12. Deleting the external table
13. Checking existence of files with S3
1
2-- 6. Create an external table named "ext_tbl" in schema "ctg_ext.sch_ref" in the location "s3://s3-demo-data-uc/demo/ext_tbl" with the delta properties "appendOnly"
3CREATE TABLE ctg_ext.sch_ref.ext_tbl (
4 col1 int
5 ,col2 timestamp
6)
7COMMENT 'Test External Table with TBLProperties'
8LOCATION 's3://s3-demo-data-uc/demo/ext_tbl'
9TBLPROPERTIES('delta.appendOnly' = 'true')
10;
11
12
13-- 7. Check if the file exists on AWS S3 (with AWS CLI)
14-- aws s3 ls s3://s3-demo-data-uc/demo/ --recursive | grep "ext_tbl" | sed 's/[[:space:]][[:space:]]*/|/g' | cut -d "|" -f 4
15/* Result :
16demo/ext_tbl/_delta_log/
17demo/ext_tbl/_delta_log/.s3-optimization-0
18demo/ext_tbl/_delta_log/.s3-optimization-1
19demo/ext_tbl/_delta_log/.s3-optimization-2
20demo/ext_tbl/_delta_log/00000000000000000000.crc
21demo/ext_tbl/_delta_log/00000000000000000000.json
22*/
23
24
25-- 8. Insert Data into the "ext_tbl" table
26INSERT INTO ctg_ext.sch_ref.ext_tbl VALUES (1,current_timestamp());
27
28-- 9. Check if the file exists on AWS S3 (with AWS CLI)
29-- aws s3 ls s3://s3-demo-data-uc/demo/ --recursive | grep "ext_tbl" | sed 's/[[:space:]][[:space:]]*/|/g' | cut -d "|" -f 4
30/* Result :
31demo/ext_tbl/_delta_log/
32demo/ext_tbl/_delta_log/.s3-optimization-0
33demo/ext_tbl/_delta_log/.s3-optimization-1
34demo/ext_tbl/_delta_log/.s3-optimization-2
35demo/ext_tbl/_delta_log/00000000000000000000.crc
36demo/ext_tbl/_delta_log/00000000000000000000.json
37demo/ext_tbl/_delta_log/00000000000000000001.crc
38demo/ext_tbl/_delta_log/00000000000000000001.json
39demo/ext_tbl/part-00000-097fb1f5-1d7e-464a-a65b-1303bd06e2b0.c000.snappy.parquet
40*/
41
42-- 10. Check Delta History
43DESCRIBE HISTORY ctg_ext.sch_ref.ext_tbl;
44/* Result :
45Version 1 : WRITE
46Version 0 : CREATE TABLE
47*/
48
49-- 11. Delete data without using the Unity Catalog Table
50DELETE FROM DELTA.`s3://s3-demo-data-uc/demo/ext_tbl` WHERE col1 = 1;
51/* Result : This table is configured to only allow appends.*/
52
53
54-- 12. Delete the table "ext_tbl"
55DROP TABLE ctg_ext.sch_ref.ext_tbl;
56
57-- 13. Check if the file exists on AWS S3 (with AWS CLI)
58-- aws s3 ls s3://s3-demo-data-uc/demo/ --recursive | grep "ext_tbl" | sed 's/[[:space:]][[:space:]]*/|/g' | cut -d "|" -f 4
59/* Result :
60demo/ext_tbl/_delta_log/
61demo/ext_tbl/_delta_log/.s3-optimization-0
62demo/ext_tbl/_delta_log/.s3-optimization-1
63demo/ext_tbl/_delta_log/.s3-optimization-2
64demo/ext_tbl/_delta_log/00000000000000000000.crc
65demo/ext_tbl/_delta_log/00000000000000000000.json
66demo/ext_tbl/_delta_log/00000000000000000001.crc
67demo/ext_tbl/_delta_log/00000000000000000001.json
68demo/ext_tbl/part-00000-097fb1f5-1d7e-464a-a65b-1303bd06e2b0.c000.snappy.parquet
69*/
Remarks :
- When creating a table, only the
_delta_logsubdirectory is created to contain the information of version n°0 - When defining a property with the “TBLPROPERTIES” option on the external table, it is also saved on the storage.
- After deleting the table, the data is no longer accessible through the table but is still accessible through the AWS S3 resource path
Regarding the properties that can be used with the Delta format: You can find more information in the official documentation
Clean environment
You will find, below, all the instructions needed to clean the environment.
Drop elements from Unity Catalog using SQL statements:
1-- Delete the Catalog with CASCADE option (to delete all objects)
2DROP CATALOG IF EXISTS ctg_ipp CASCADE;
3DROP CATALOG IF EXISTS ctg_ext CASCADE;
4
5-- Delete the External Location
6DROP EXTERNAL LOCATION IF EXISTS el_demo_data_uc force;
Note regarding the removal of the External Location object:
- Must be the owner
- It must not already be used by a table, otherwise you must use the
forceoption
Deleting data used on the AWS S3 resource:
1# Delete all files stored in the AWS S3 resource
2aws s3 rm "s3://s3-demo-data-uc/demo/" --recursive
Deleting the group from the Databricks Account (this will automatically delete the group at the Databricks Workspace level):
- Go to
Account Databricks page > User management > Groups - Use the search bar to find the desired group
- Click on the button with the 3 dots associated with the group and choose the
Deleteoption - Click on
Confirm Delete
Deleting the user at the Databricks Account level:
- Go to
Account Databricks page > User management > Users - Use the search bar to find the desired user
- Click on the user’s name
- Click on the button with the 3 dots and choose the
Delete useroption - Click on
Confirm Delete
Conclusion
We were able to see a first overview of some features of the Unity Catalog solution, mainly concerning the management of rights and storage with External Table and Managed Table.
Rights management is simplified by the use of ANSI SQL syntax, the use of user groups and the centralization of access management within Unity Catalog..
Group management requires being an Administrator on the Databricks Account (creation and deletion of groups, addition and deletion of users in groups) and an Administrator on the Databricks Workspace to add or delete existing groups at the level of the Databricks Account in the Databricks Workspace.
Warning : The management of rights and groups are not compatible between Unity Catalog and Hive Metastore, it is recommended to migrate the elements from Hive Metastore to Unity Catalog by recreating the necessary elements.
If you want to implement an open data lake by minimizing the use of Databricks, it is possible to use Unity Catalog with external tables in Delta format to be able to use the maximum functionality while using other tools to directly access Delta data (AWS EMR, AWS Glue, AWS Athena, …).
However, if you wish to use the Unity Catalog solution, it is strongly recommended to centralize all data governance in order to be able to manage all access within the Unity Catalog solution.
From the Unity Catalog solution, it is possible to access the data using Clusters, SQL Warehouse or the Delta Sharing functionality to multiply the usage of the data.
Resources
Creation of a SQL Warehouse
Databricks CLI does not support managing SQL Warehouses at the moment, therefore we can use Databricks REST API to do it.
Prerequisites :
- Have the
Curltool installed
Actions:
- Creation of a
.netrcfile to manage access to the REST API:
1# Create the folder where the .netrc file will be stored
2mkdir ~/.databricks
3
4# Create the .netrc file
5echo "machine <url workspace databricks without https://>
6login token
7password <token user databricks>
8" > ~/.databricks/.netrc
9
10# Create an alias to use the tool curl with .netrc file
11echo "alias dbx-api='curl --netrc-file ~/.databricks/.netrc'" >> ~/.alias
- Creation of a warehouse
1
2export DBX_API_URL="<url workspace databricks>"
3
4# Get the list of the existing SQL Warehouses (check if the SQL Warehouse exists)
5dbx-api -X GET ${DBX_API_URL}/api/2.0/sql/warehouses/ | jq .
6
7# Create the temporary config file for the SQL Warehouse
8cat > tmp_databricks_create_warehouse.json <<EOF
9{
10 "name": "DEMO_WH_XXS",
11 "cluster_size": "2X-Small",
12 "min_num_clusters": 1,
13 "max_num_clusters": 1,
14 "auto_stop_mins": 20,
15 "auto_resume": true,
16 "tags": {
17 "custom_tags": [
18 {
19 "key": "owner",
20 "value": "admin@tech.demo"
21 },
22 {
23 "key": "project",
24 "value": "databricks-demo"
25 }
26 ]
27 },
28 "spot_instance_policy":"COST_OPTIMIZED",
29 "enable_photon": "true",
30 "enable_serverless_compute": "false",
31 "warehouse_type": "CLASSIC",
32 "channel": {
33 "name": "CHANNEL_NAME_CURRENT"
34 }
35}
36EOF
37
38
39# Creation of the SQL Warehouse
40dbx-api -X POST -H "Content-Type: application/json" -d "@tmp_databricks_create_warehouse.json" ${DBX_API_URL}/api/2.0/sql/warehouses/
41
42# Delete the temporary config file
43rm tmp_databricks_create_warehouse.json
Some actions that may be useful :
1# Export the SQL Warehouse ID
2export SQL_WH_ID="<SQL Warehouse ID>"
3
4# Check the state of the SQL Warehouse
5dbx-api -X GET ${DBX_API_URL}/api/2.0/sql/warehouses/${SQL_WH_ID} | jq '.state'
6
7# Stop the SQL Warehouse (by default, it starts at creation)
8dbx-api -X POST ${DBX_API_URL}/api/2.0/sql/warehouses/${SQL_WH_ID}/stop
9
10# Start the SQL Warehouse
11dbx-api -X POST ${DBX_API_URL}/api/2.0/sql/warehouses/${SQL_WH_ID}/start
12
13# Delete the SQL Warehouse
14dbx-api -X DELETE ${DBX_API_URL}/api/2.0/sql/warehouses/${SQL_WH_ID}