
Databricks : Unity Catalog - First Step - Part 3 - Data Lineage
We are going to discover the Data Lineage functionality offered by the Unity Catalog solution.
We will use a Databricks Account on AWS to perfrom this discovery.
Note: Work is based on the state of the Unity Catalog solution at the end of Q1 2023 on AWS and Azure.
What’s the Data Lineage
Data Lineage consists of mapping all the objects and their use in order to visualize (and extract information about) the data life cycle.
When you want to set up a data governance, the data lineage provides extremely useful information.
A functional lineage consists of setting up the elements and tools to map the functional objects and their use in the different applications and projects of the company in order to visualize the use of data throughout the organization (teams, applications, projects) This makes it easier to rationalize the global usage of the data and to build a common functional language for the company.
A technical lineage consists of setting up the elements and tools to map the technical objects and the use of the data by the different technical tools. This makes it possible to visualize the relationship between the different objects and to quickly identify the source of the data of an object as well as the elements impacted by the changes of an object.
Some data governance tools automate the capture of metadata to centralize data lineage information such as Apache Atlas, Azure Purview or AWS Glue (and many others)
In our case, we will rely on the Unity Catalog solution proposed by Databricks and more precisely on the capture of information implemented by this solution to map all elements related to Data Lineage.
Note: It is also possible to set up this mapping in a manual way with the use of a Wiki fed manually or with scripts to extract the metadata of the various tools when it is possible. This requires a lot of time and energy to write, maintain, extract and validate the information over time (evolution of tools, evolution of applications, evolution of data, …)
Unity Catalog and the object hierarchy
Unity Catalog is the Databricks solution that allows to have a unified and centralized governance for all the data managed by the Databricks resources as well as to secure and facilitate the management and the sharing of the data to all the internal and external actors of an organization.
You can get a more complete overview by reading the official documentation
Reminder concerning the hierarchy of objects :
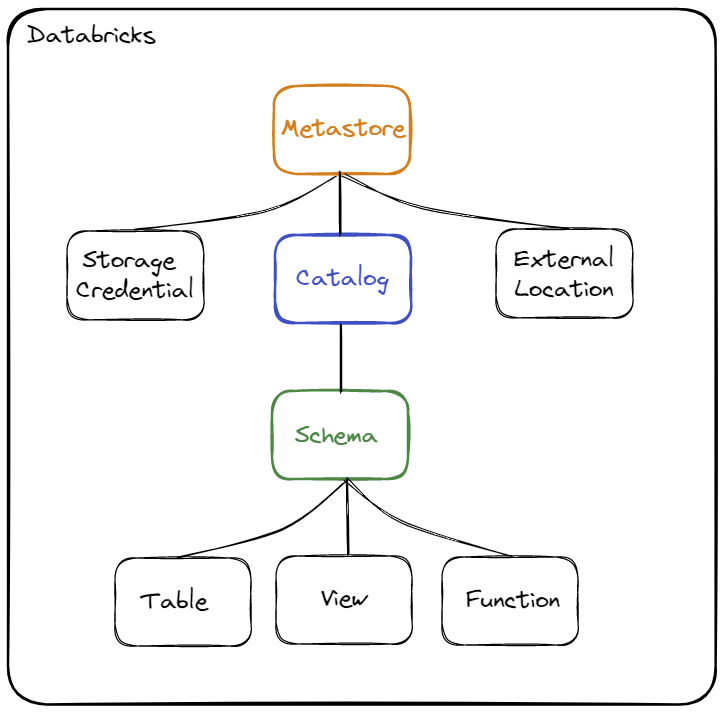
The objects are :
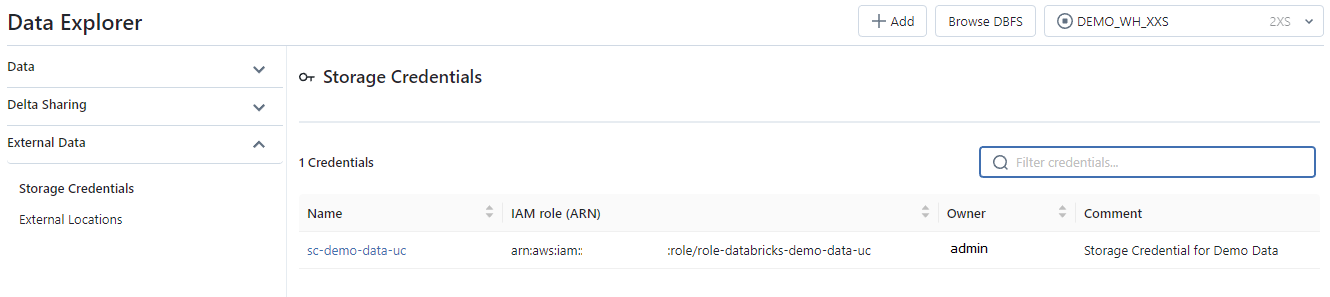
- Storage Credential : This object is directly associated with the Metastore and is used to store access to a cloud provider (for example AWS S3) allowing the Unity Catalog solution to manage data rights
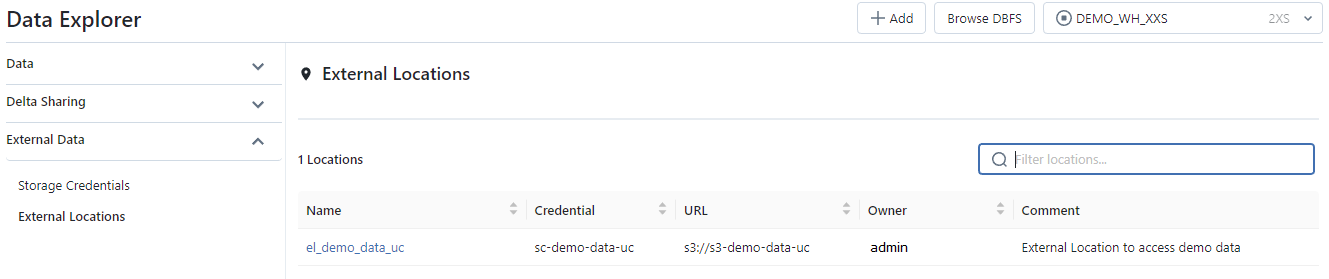
- External Location : This object is associated with the Metastore and allows you to store the path to a cloud provider (for example an AWS S3 resource) in combination with a Storage Credential to manage data access
- Metastore : Top-level object that can contain metadata
- Catalog : 1st level object allowing to organize data by Schema (also called Database)
- Schema : 2nd and last level object used to organize data (contains tables, views and functions)
- Table : Object used to define the structure and storage of data..
- View : Object used to encapsulate a query using one or more objects (table or view)
- Function : Object allowing to define operations on the data
When you want to access an object (for example a table), it will be necessary to use the name of the Catalog and the name of the Schema where the object is defined.
Example : select * from catalog.schema.table
Set-up the environment
We are going to set up a set of elements that will allow us to discover the Data Lineage functionality of the Unity Catalog solution in more detail.
Context
Prerequisite:
- Creation of the
grp_demogroup - Creation of the
john.do.dbx@gmail.comuser and add the user to groupgrp_demo. - Creation of a SQL Warehouse and give the right to use it to the group
grp_demo. - Existence of a Metastore named
metastore-sandboxwith the Storage Credential namedsc-metastore-sandboxallowing to store the data by default in the AWS S3 resource nameds3-dbx-metastore-uc - Creation of an AWS S3 resource named
s3-demo-data-uc - Creation of an AWS IAM role named
role-databricks-demo-data-ucand an AWS IAM policy namedpolicy-databricks-demo-data-ucallowing the global Databricks role to manage access to the AWS S3 resource nameds3-demo-data-uc - Creation of a Storage Credential named
sc-demo-data-ucand an External Location namedel_demo_data_ucallowing the global Databricks role to manage access to the AWS S3 resource nameds3-demo-data-uc
Setting up rights for the grp_demo group :
- Give the right to create catalogs at the Metastore level for the
grp_demogroup - Give the right to read external files from the External Location object named
el_demo_data_uc.
1-- 1. Give Create Catalog right on Metastore to grp_demo
2GRANT CREATE CATALOG ON METASTORE TO grp_demo;
3
4-- 2. Give Read Files right on el_demo_data_uc location to grp_demo
5GRANT READ FILES ON EXTERNAL LOCATION `el_demo_data_uc` TO grp_demo;
Diagram of the environment
Diagram of the 1st level elements of the Metastore corresponding to the pre-requisite :
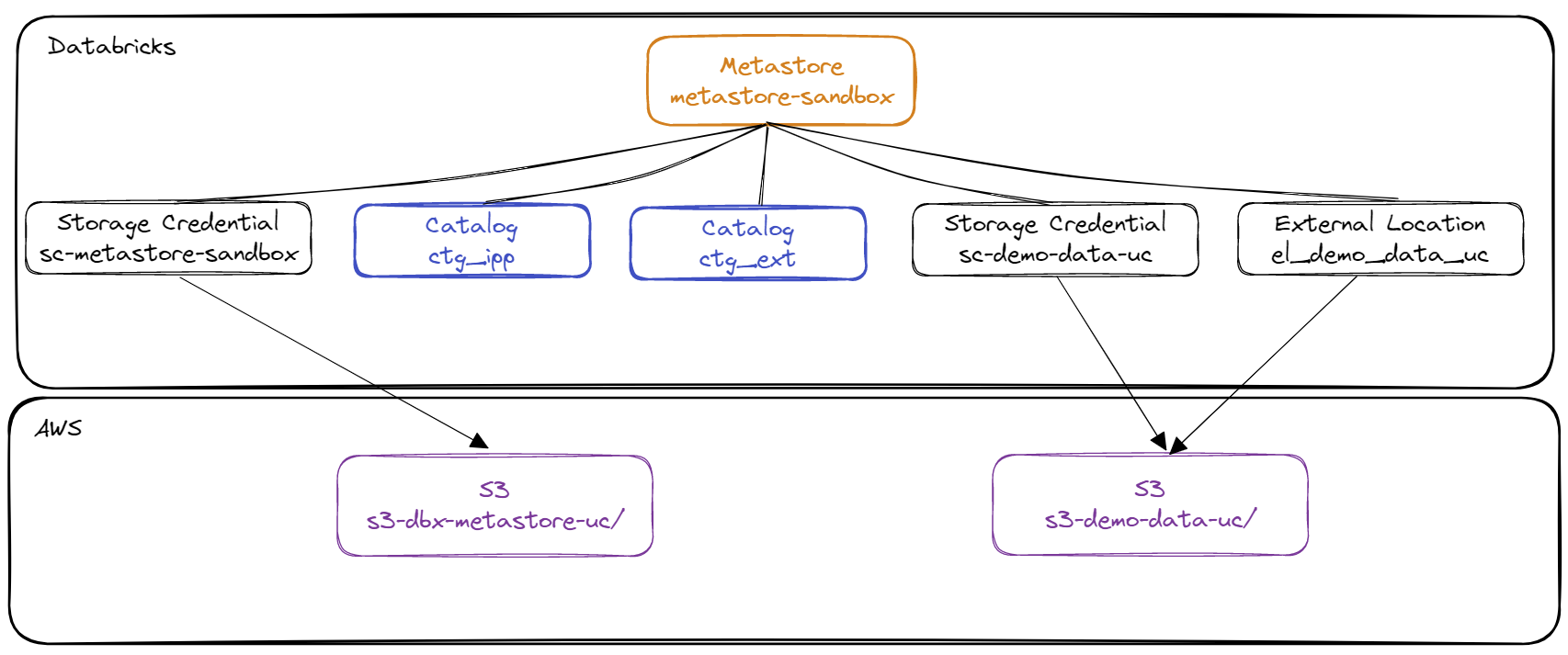
Diagram of the catalogue ctg_ipp content :
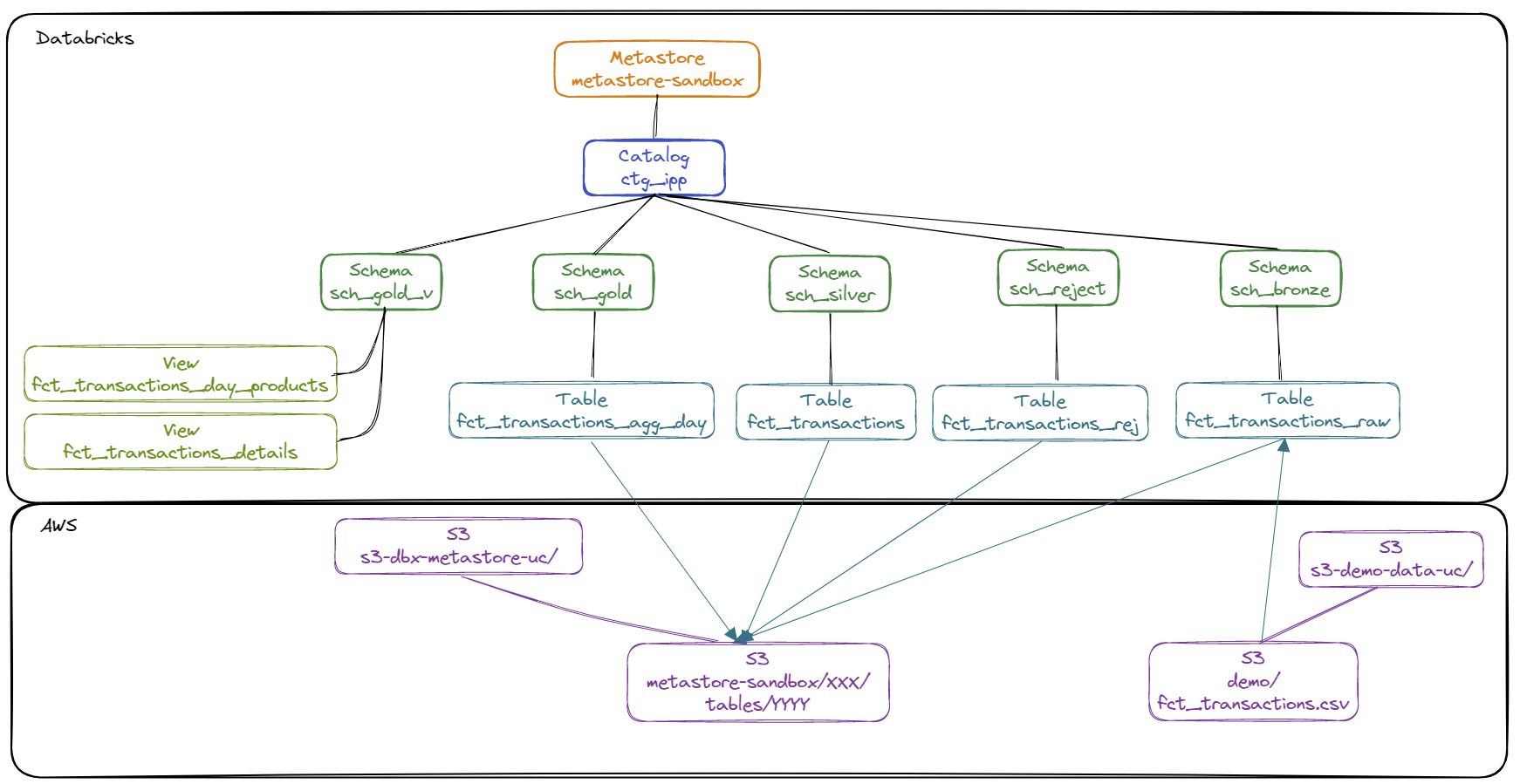
Diagram of the catalogue ctg_ext content :
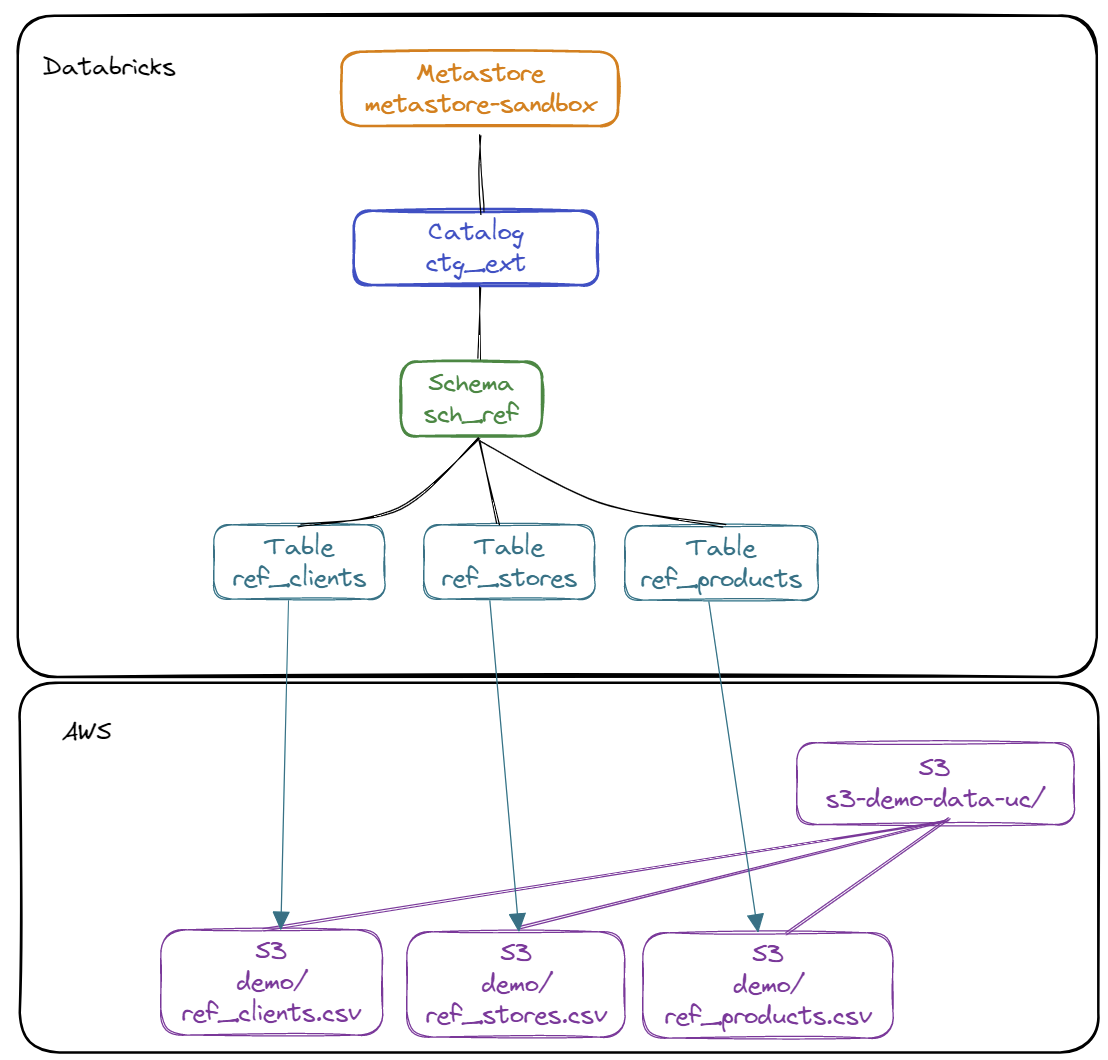
Diagram of the data ingestion between the different objects :

Setting up a dataset on the AWS S3 resource
Content of the file ref_stores.csv :
1id,lib,postal_code,surface,last_maj
21,BustaPhone One,75001,120,2022-01-01 00:00:00
32,BustaPhone Two,79002,70,2022-01-01 00:00:00
Content of the file ref_clients.csv :
1id,lib,age,contact,phone,is_member,last_maj
21,Maxence,23,max1235@ter.tt,+33232301123,No,2023-01-01 11:01:02
32,Bruce,26,br_br@ter.tt,+33230033155,Yes,2023-01-01 13:01:00
43,Charline,40,ccccharline@ter.tt,+33891234192,Yes,2023-03-02 09:00:00
Content of the file ref_products.csv :
1id,lib,brand,os,last_maj
21,Pixel 7 Pro,Google,Android,2023-01-01 09:00:00
32,Iphone 14,Apple,IOS,2023-01-01 09:00:00
43,Galaxy S23,Samsung,Android,2023-01-01 09:00:00
Content of the file fct_transactions.csv :
1id_trx,ts_trx,id_product,id_shop,id_client,quantity
21,2023-04-01 09:00:00,1,2,1,1
32,2023-04-01 11:00:00,1,1,1,3
43,2023-04-03 14:00:00,1,2,1,1
54,2023-04-05 08:00:00,3,1,2,9
65,2023-04-06 10:00:00,1,2,1,3
76,2023-04-06 12:00:00,2,2,1,1
87,2023-04-10 18:30:00,2,1,2,11
98,2023-04-10 18:30:00,3,1,2,2
Copying data to the demo directory of the AWS S3 resource named s3-demo-data-uc with the AWS CLI tool :
1aws s3 cp ref_stores.csv s3://s3-demo-data-uc/demo/ref_stores.csv
2aws s3 cp ref_clients.csv s3://s3-demo-data-uc/demo/ref_clients.csv
3aws s3 cp ref_products.csv s3://s3-demo-data-uc/demo/ref_products.csv
4aws s3 cp fct_transactions.csv s3://s3-demo-data-uc/demo/fct_transactions.csv
Setting up the objects on the Unity Catalog Metastore
Note : Using a user from grp_demo group
- Creation of catalogs
ctg_ipp: Catalog to manage the elements managed by Unity Catalogctg_ext: Catalog to manage external elements
1-- Create Catalog (for managed data)
2CREATE CATALOG IF NOT EXISTS ctg_ipp
3 COMMENT 'Catalog for managed data';
4
5-- Create Catalog (for external data)
6CREATE CATALOG IF NOT EXISTS ctg_ext
7 COMMENT 'Catalog for external data';
- Creation of schemas The list of schemas :
ctg_ext.sch_ref: Schema for grouping external tables to access the referential datactg_ipp.sch_bronze: Schema for storing raw datactg_ipp.sch_silver: Schema for storing refined datactg_ipp.sch_gold: Schema for storing aggregated datactg_ipp.sch_gold_v: Schema to define views for data exposurectg_ipp.sch_reject: Schema for storing rejected data
1-- Create Schema for external data
2CREATE SCHEMA IF NOT EXISTS ctg_ext.sch_ref
3 COMMENT 'Schema for external referential data';
4
5-- Create Schema for managed data
6CREATE SCHEMA IF NOT EXISTS ctg_ipp.sch_bronze
7 COMMENT 'Schema for Bronze Data';
8CREATE SCHEMA IF NOT EXISTS ctg_ipp.sch_silver
9 COMMENT 'Schema for Silver Data';
10CREATE SCHEMA IF NOT EXISTS ctg_ipp.sch_gold
11 COMMENT 'Schema for Gold Data';
12CREATE SCHEMA IF NOT EXISTS ctg_ipp.sch_gold_v
13 COMMENT 'Schema for Gold Views';
14CREATE SCHEMA IF NOT EXISTS ctg_ipp.sch_reject
15 COMMENT 'Schema for Reject Data';
- Creation of external tables to access referential data
1-- Create external table (referential)
2CREATE TABLE ctg_ext.sch_ref.ref_clients (
3 id int
4 ,lib string
5 ,age int
6 ,contact string
7 ,phone string
8 ,is_member string
9 ,last_maj timestamp
10)
11USING CSV
12OPTIONS (path "s3://s3-demo-data-uc/demo/ref_clients.csv",
13 delimiter ",",
14 header "true");
15
16CREATE TABLE ctg_ext.sch_ref.ref_products (
17 id int
18 ,lib string
19 ,brand string
20 ,os string
21 ,last_maj timestamp
22)
23USING CSV
24OPTIONS (path "s3://s3-demo-data-uc/demo/ref_products.csv",
25 delimiter ",",
26 header "true");
27
28CREATE TABLE ctg_ext.sch_ref.ref_shops (
29 id int
30 ,lib string
31 ,postal_code string
32 ,surface int
33 ,last_maj timestamp
34)
35USING CSV
36OPTIONS (path "s3://s3-demo-data-uc/demo/ref_shops.csv",
37 delimiter ",",
38 header "true")
39 ;
40
41
42-- Create managed table
43CREATE TABLE ctg_ipp.sch_bronze.fct_transactions_raw (
44 id_trx string
45 ,ts_trx string
46 ,id_product string
47 ,id_shop string
48 ,id_client string
49 ,quantity string
50)
51COMMENT 'Bronze Transactions Data';
52
53
54CREATE TABLE ctg_ipp.sch_reject.fct_transactions_rej (
55 id_rej int
56 ,ts_rej timestamp
57 ,id_trx string
58 ,ts_trx string
59 ,id_product string
60 ,id_shop string
61 ,id_client string
62 ,quantity string
63)
64COMMENT 'Reject Transactions Data';
65
66
67CREATE TABLE ctg_ipp.sch_silver.fct_transactions (
68 id_trx integer
69 ,ts_trx timestamp
70 ,id_product integer
71 ,id_shop integer
72 ,id_client integer
73 ,quantity integer
74 ,ts_tech timestamp
75)
76COMMENT 'Silver Transactions Data';
77
78
79CREATE TABLE ctg_ipp.sch_gold.fct_transactions_agg_day (
80 dt_trx date
81 ,id_product integer
82 ,is_member boolean
83 ,quantity integer
84 ,ts_tech timestamp
85)
86COMMENT 'Gold Transactions Data Agg Day';
- Ingestion of data in managed tables
1-- Insert Bronze Data
2COPY INTO ctg_ipp.sch_bronze.fct_transactions_raw
3 FROM 's3://s3-demo-data-uc/demo/fct_transactions.csv'
4 FILEFORMAT = CSV
5 FORMAT_OPTIONS ('encoding' = 'utf8'
6 ,'inferSchema' = 'false'
7 ,'nullValue' = 'N/A'
8 ,'mergeSchema' = 'false'
9 ,'delimiter' = ','
10 ,'header' = 'true'
11 ,'mode' = 'failfast')
12;
13
14
15-- Insert Reject Data
16INSERT INTO ctg_ipp.sch_reject.fct_transactions_rej (
17 id_rej
18 ,ts_rej
19 ,id_trx
20 ,ts_trx
21 ,id_product
22 ,id_shop
23 ,id_client
24 ,quantity
25)
26SELECT 1 as id_rej
27 ,current_timestamp() as ts_rej
28 ,id_trx
29 ,ts_trx
30 ,id_product
31 ,id_shop
32 ,id_client
33 ,quantity
34FROM ctg_ipp.sch_bronze.fct_transactions_raw
35WHERE TRY_CAST(quantity AS integer) IS NULL
36 OR TRY_CAST(quantity AS integer) < 1 ;
37
38
39
40-- Insert Silver Data
41INSERT INTO ctg_ipp.sch_silver.fct_transactions (
42 id_trx
43 ,ts_trx
44 ,id_product
45 ,id_shop
46 ,id_client
47 ,quantity
48 ,ts_tech
49)
50SELECT
51 case when (id_trx = 'N/A') then -1 else cast(id_trx as integer) end as id_trx
52 ,case when (ts_trx='N/A') then cast('1900-01-01 00:00:00' as timestamp) else cast(ts_trx as timestamp) end as ts_trx
53 ,case when (id_product = 'N/A') then -1 else cast(id_product as integer) end as id_product
54 ,case when (id_shop = 'N/A') then -1 else cast(id_shop as integer) end as id_shop
55 ,case when (id_client = 'N/A') then -1 else cast(id_client as integer) end as id_client
56 ,case when (quantity = 'N/A') then 0 else cast(quantity as integer) end as quantity
57 ,current_timestamp() as ts_tech
58FROM ctg_ipp.sch_bronze.fct_transactions_raw
59WHERE case when (quantity = 'N/A') then 0 else cast(quantity as integer) end > 0 ;
60
61
62
63-- Insert Gold Data
64INSERT INTO ctg_ipp.sch_gold.fct_transactions_agg_day (
65 dt_trx
66 ,id_product
67 ,is_member
68 ,quantity
69 ,ts_tech
70)
71SELECT cast(trx.ts_trx as date) as dt_trx
72 ,trx.id_product
73 ,case when (rc.is_member = 'Yes') then true else false end is_member
74 ,sum(trx.quantity) as quantity
75 ,current_timestamp() as ts_tech
76FROM ctg_ipp.sch_silver.fct_transactions trx
77INNER JOIN ctg_ext.sch_ref.ref_clients rc
78ON (rc.id = trx.id_client)
79GROUP BY dt_trx
80 ,trx.id_product
81 ,rc.is_member;
- Creation of views
1-- Create Views
2CREATE OR REPLACE VIEW ctg_ipp.sch_gold_v.fct_transactions_day_products
3AS
4SELECT atd.dt_trx
5 ,rp.lib as lib_product
6 ,atd.quantity
7 ,atd.ts_tech
8FROM ctg_ipp.sch_gold.fct_transactions_agg_day atd
9LEFT OUTER JOIN ctg_ext.sch_ref.ref_products rp
10ON (rp.id = atd.id_product)
11where is_member = true;
12
13
14CREATE OR REPLACE VIEW ctg_ipp.sch_gold_v.fct_transactions_detail
15AS SELECT trx.id_trx
16 ,trx.ts_trx
17 ,rp.lib as lib_product
18 ,rp.brand as brand_product
19 ,rp.os as os_product
20 ,rs.lib as lib_shop
21 ,rs.postal_code as postal_code_shop
22 ,rc.lib as name_client
23 ,case when is_member('admins') then rc.contact else 'XXX@XXX.XX' end as contact_client
24 ,trx.ts_tech
25FROM ctg_ipp.sch_silver.fct_transactions trx
26INNER JOIN ctg_ext.sch_ref.ref_clients rc
27ON (trx.id_client = rc.id)
28LEFT OUTER JOIN ctg_ext.sch_ref.ref_shops rs
29ON (trx.id_shop = rs.id)
30LEFT OUTER JOIN ctg_ext.sch_ref.ref_products rp
31ON (trx.id_product = rp.id);
Data Explorer
The Data Explorer tool provides a user interface for exploring and managing data (Catalog, Schema, Tables, Views, Rights) and provides a lot of information about the different objects and their use.
This tool is accessible in all views of the Databricks Workspace (Data Science & Engineering, Machine Learning, SQL) by clicking on the Data option of the side menu.
This tool uses the access rights of the Databricks Workspace user, therefore it is necessary to have sufficient rights on the objects.
To be able to explore the elements without having the right to read the data, it is necessary to have the USE right on the different objects (Catalog, Schema, Table, View)
To be able to access a sample of the data or the history of a table in Delta format, you must have the SELECT right in addition to the USE right.
It is possible to access the metadata of all Unity Catalog objects without using a SQL Warehouse. For the following actions, it is necessary to have an active SQL Warehouse to read the necessary data:
- Access to the
hive_metastorecatalog objects - Access to a sample of the data from a table
- Access to the history of a Delta table
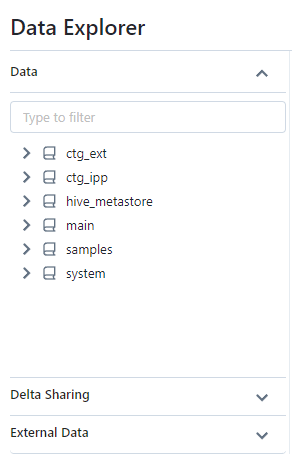
The Explorer menu (sidebar) provides access to the following elements :
Dataoption : Allows to navigate in the hierarchy of the Metastore elements (Catalogs, Schemas, Tables, Views, …)External Dataoption : Contains the list of elements concerning the Storage Credential and the External Location.
Screenshot of Data option :
Screenshot of External Data option :
The Main interface provides access to the following elements :
- Display the list of catalogs, visible by the user, with for each catalog the timestamp of creation and the owner (creator by default)
- Allows you to create, rename or delete a catalog
Screenshot of Main interface :
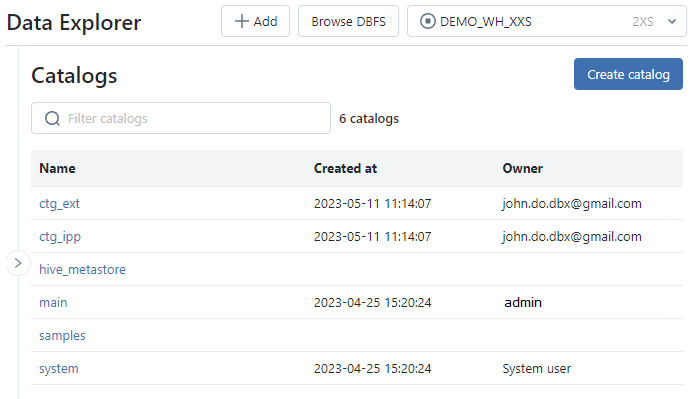
Catalog interface :
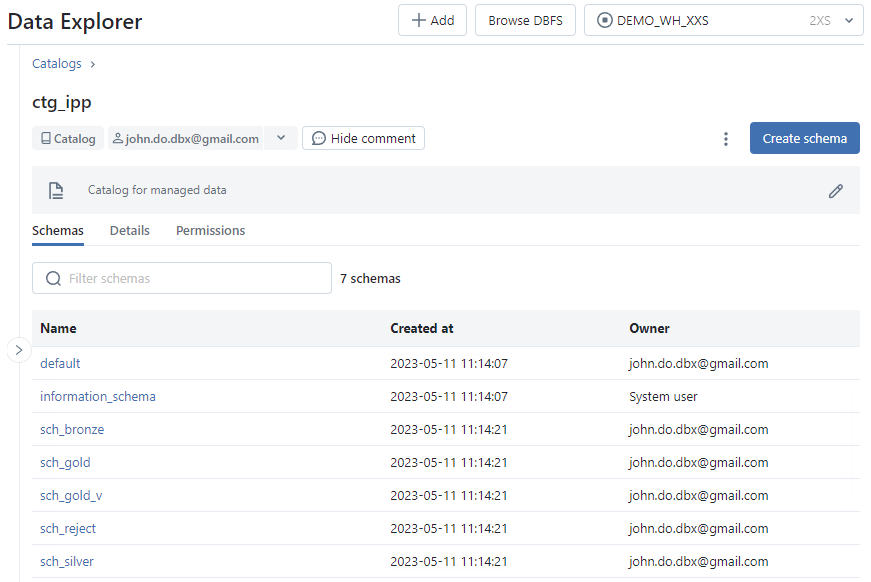
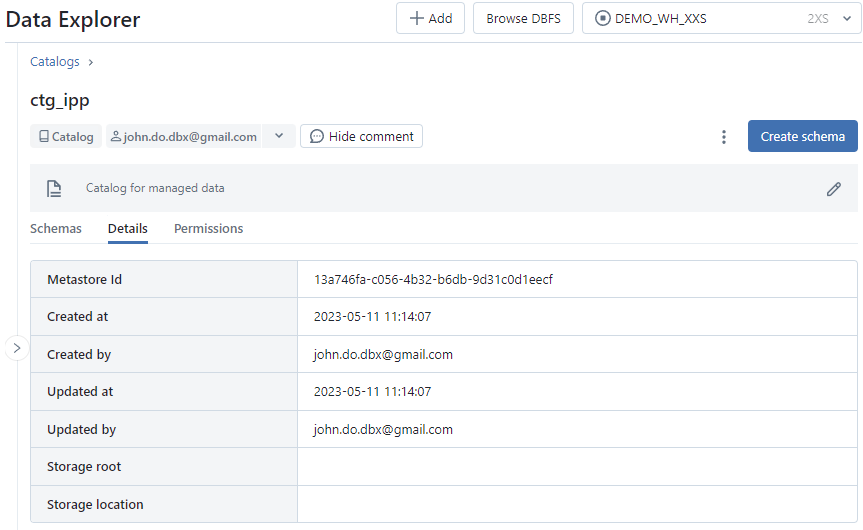
Schemastab : Display of the list of schemas in the catalog, visible by the user, with for each schema the creation timestamp and the owner (creator by default)Detailtab : Display of detailed information about the catalog (Metastore Id, …)Permissionstab : Rights management on the catalog
Screenshot of Schemas tab of Catalog interface :
Screenshot of Details tab of Catalog interface :
The Schema interface of a catalog :
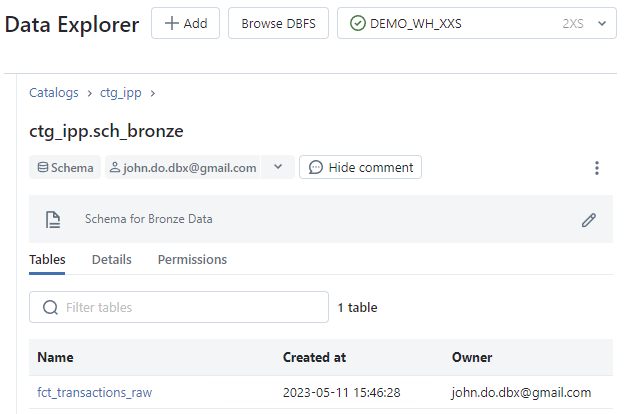
Tablestab: Display of the list of objects (tables and views) in the schema, visible to the user, with their creation timestamp and owner (creator by default)Detailstab: Display of detailed information about the schemaPermissionstab : Rights management on the catalog
Screenshot of Tables tab of Schema interface :
Screenshot of Details tab of Schema interface :
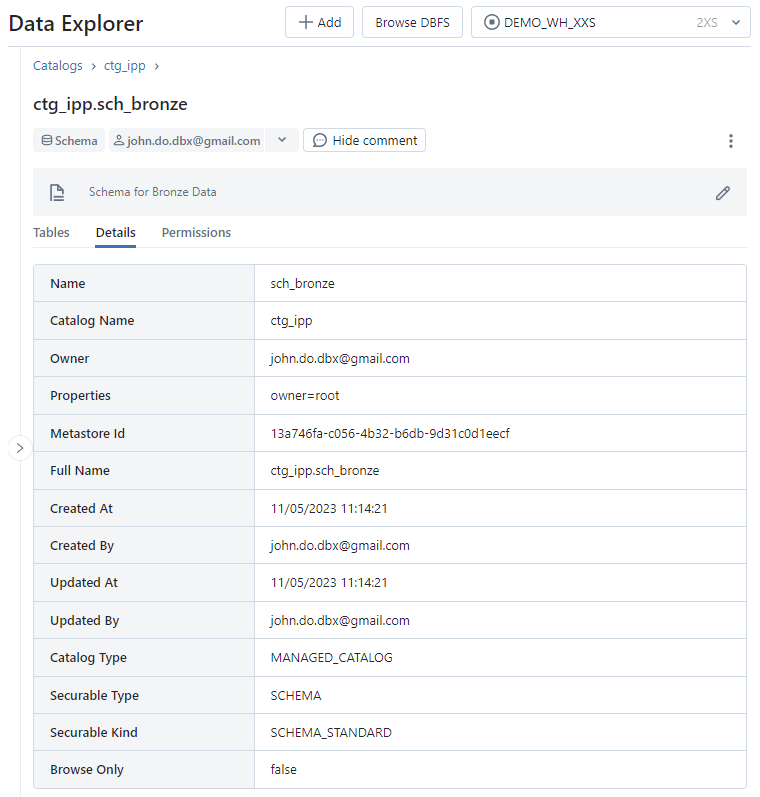
Table interface of a schema :
Columnstab : Display of the list of columns (name and type of data) and management of comments on the columnsSample Datatab: Display a sample of the object dataDetailtab : Display of detailed information about the objectPermissionstab : Rights management on the catalogHistorytab : Displays the version history of the object (when it is a Delta table only)Lineagetab : Display Data Lineage information related to the object- Additional information:
- It is possible to create a query or a dashboard directly from Data Explorer by clicking on
Createand selecting one of the options (QueryorQuick dashboard) - It is possible to rename or delete an object by clicking on the button with the 3 dots and selecting one of the options (
RenameorDelete) - The header of the interface displays information about the object such as type, data format, owner name, data size and comment
- It is possible to create a query or a dashboard directly from Data Explorer by clicking on
Screenshot of Columns tab of Table interface :
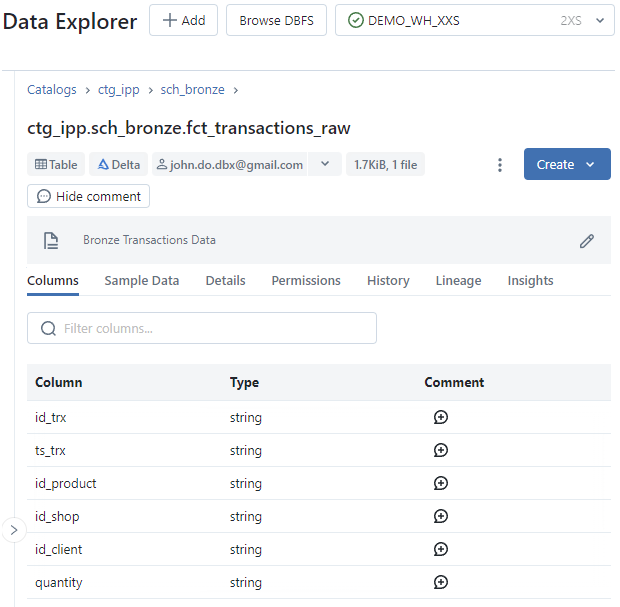
Screenshot of Sample Data tab of Table interface :
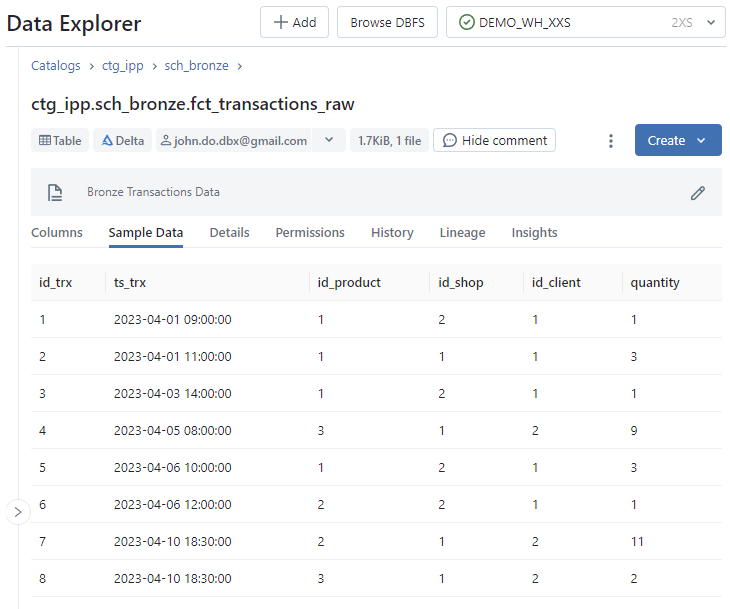
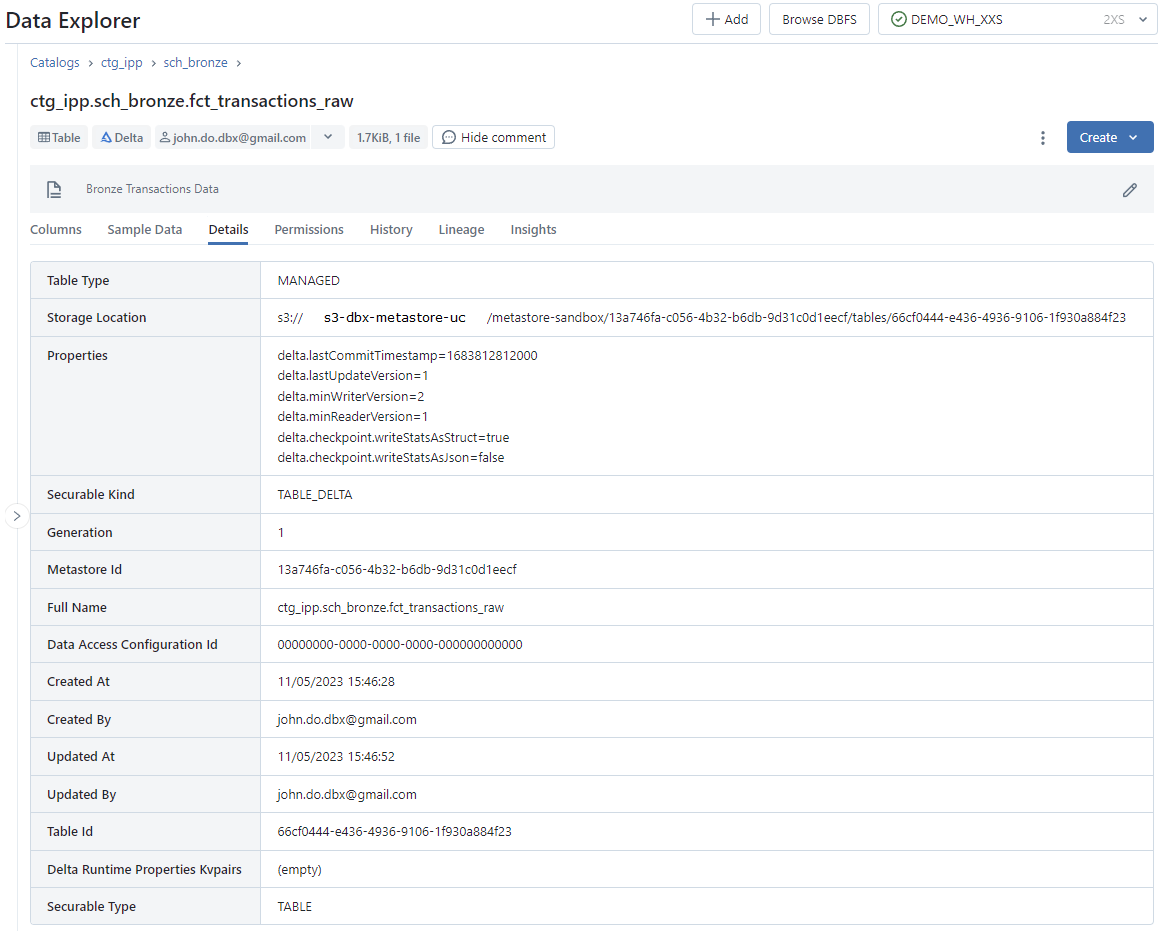
Screenshot of Detail tab of Table interface :
Screenshot of History tab of Table interface :
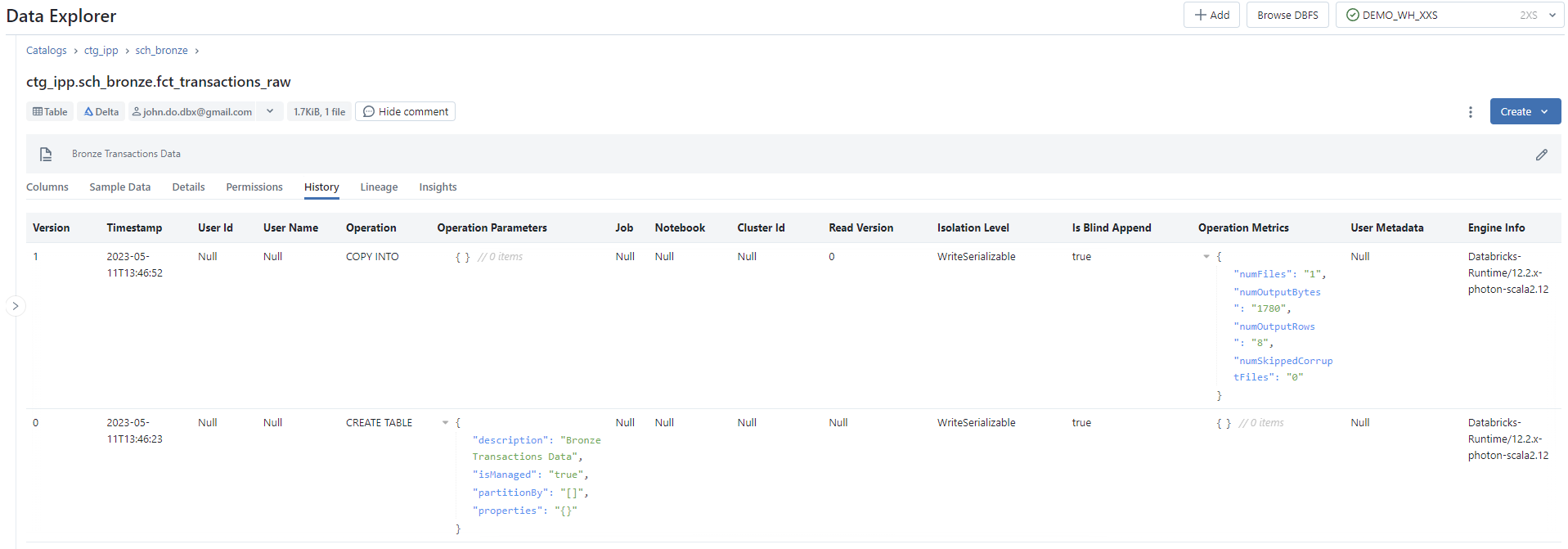
Data Lineage
Synthesis
This feature is enabled by default when the Unity Catalog solution is set up.
The access to the data of the Data Lineage functionality proposed by the Unity Catalog solution can be done in 3 different ways:
- Access the
Lineagetab of an object (Table or View) with the Data Explorer tool - Using Databricks REST API to extract information from the Unity Catalog solution
- Use of a data governance tool that has a Databricks connector to extract information from the Unity Catalog solution to a third party application
We will focus on using the Data Explorer tool to find out what information is captured by default by the Unity Catalog solution. To access at the Data Lineage information:
- Go to
Workspace Databricks page > Data. - Click on the desired catalog
- Click on the desired schema
- Click on the desired object (table or view)
- Click on the
Lineageoption
Constraint for capturing Data Lineage information for an object :
- The object must be defined in a Metastore catalog
- Queries must use the Spark Dataframe API or the Databricks SQL interface
- Capturing information based on processing using the Structured Streaming API between Delta tables is only supported in Runtime 11.3 LTS (DBR) and higher
- To access Data Lineage information on objects (tables or views), the user must have the
SELECTright on these objects.
Information about the capture :
- Data Lineage information is captured from the execution logs of the different tools (notebooks, sql queries, workflow, …) over the last 30 days (rolling window)
- This means that Data Lineage information about the execution logs of processes older than 30 days is not available
- The capture is done down to the column granularity of each object
Limitation :
- When an object is renamed, the Data Lineage information is no longer available
- Data Lineage information is captured based on the name of the object and not on the unique identifier of the table
- To have the Data Lineage information again, you have to wait the execution of the treatments using the object
- When a column is renamed, the Data Lineage information is no longer available on the column of the object in the same way as for the renaming of an object
- Note :
- It is possible to rename an object (table or view) or a column with the old name again to make available all the data lineage information already captured
- When renaming an object (for an managed object in the Metastore), the object ID (and storage path) does not change. Only the name of the object or column is modified.
For each object, the information of the Data Lineage is composed of the following elements
- Display of the full graph (all the source and target elements based on the object) and possibility to navigate in it
Upstreamoption : Allows to filter the set of elements used as source of the object’s power supply (1st level)Downstreamoption : Allows to filter all the elements using the data of the object (1st level)
The elements that can be captured by Unity Catalog for an object (Table or View) are :
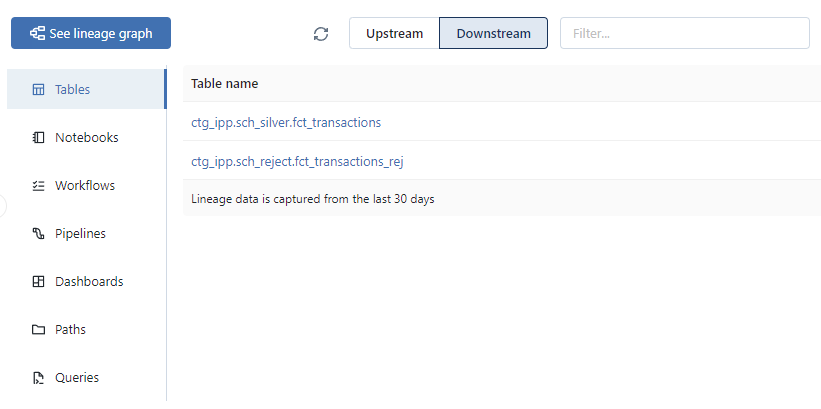
- Tables: All the objects (Tables, Views) in the Metastore related to the concerned object
- Notebooks: All the notebooks that have used the concerned object (ingest or read)
- Workflows: All the workflows having a treatment that have used the concerned object (ingest or read)
- Pipelines : All the pipelines having a treatment that have used the concerned object (ingest or read)
- Dashboards: All the dashboards build with SQL queries that have used the concerned object
- Queries: All the SQL queries (notebook format using the SQL Warehouse) that have used the concerned object
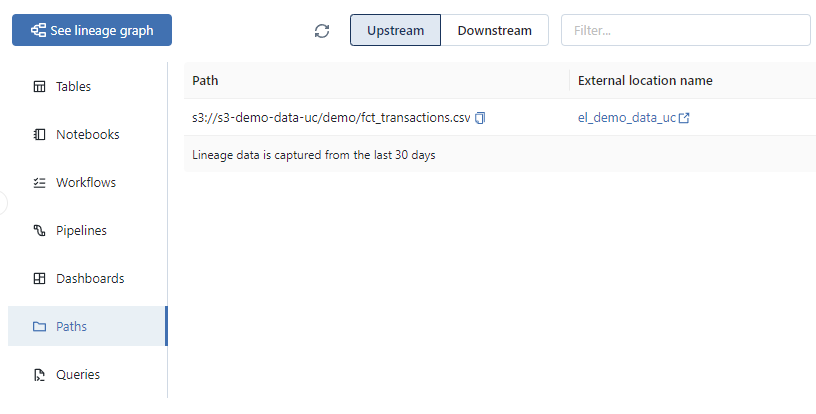
- Data access paths: All the external data access paths used by the concerned object
Visualization
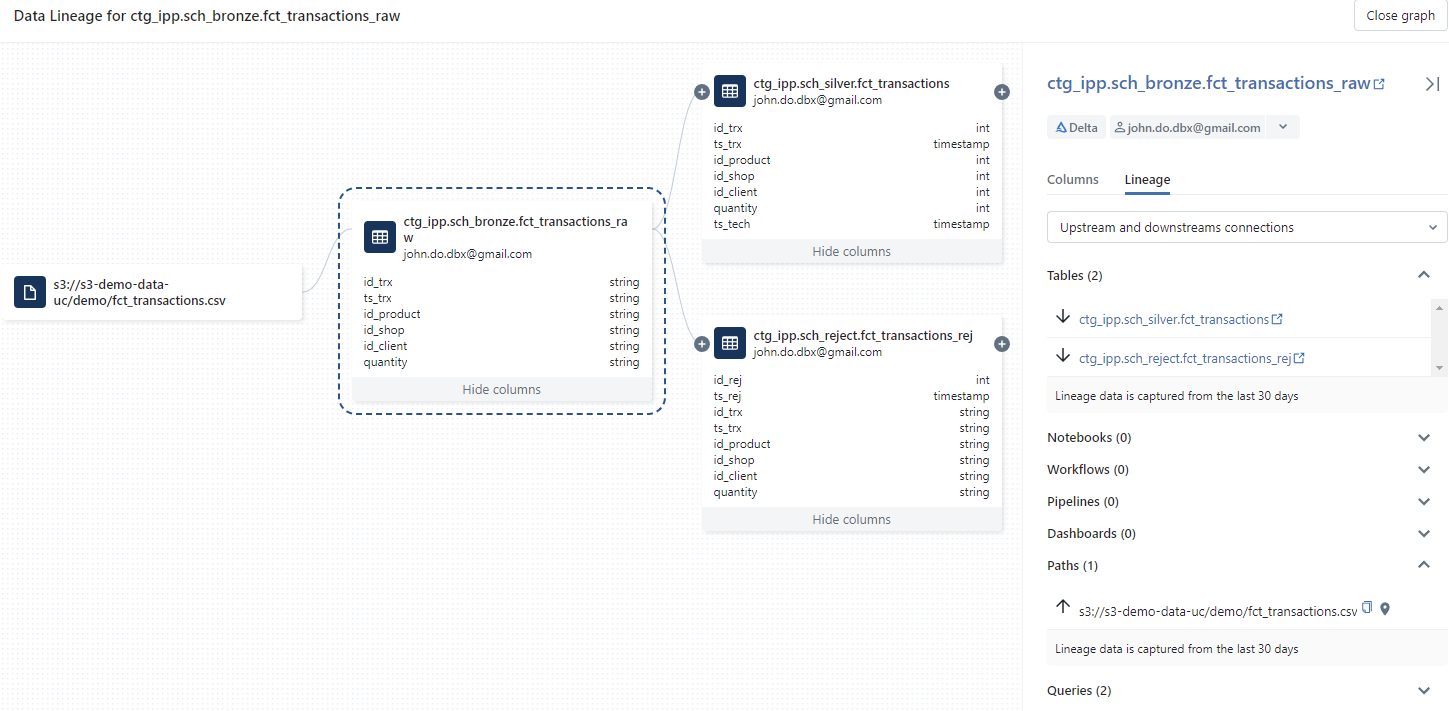
Visualization of the Data Lineage based on the ctg_ipp.sch_bronze.fct_transactions_raw table limited to the first level relation :
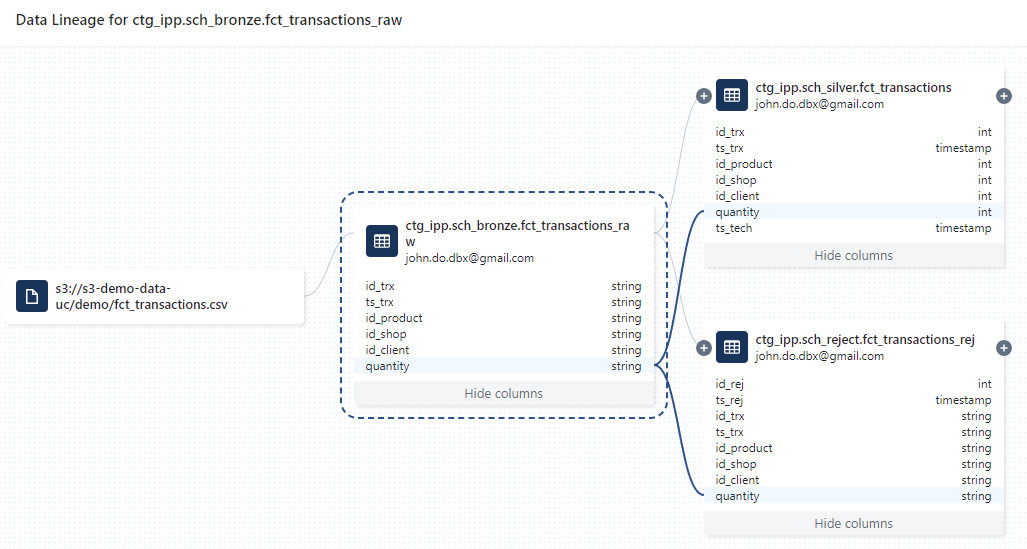
Visualization of the Data Lineage based on the quantity column of the ctg_ipp.sch_bronze.fct_transactions_raw table :
Visualization of the Data Lineage based from ctg_ipp.sch_bronze.fct_transactions_raw by taking all the related objects up to the views of the ctg_ipp.sch_gold_v schema :
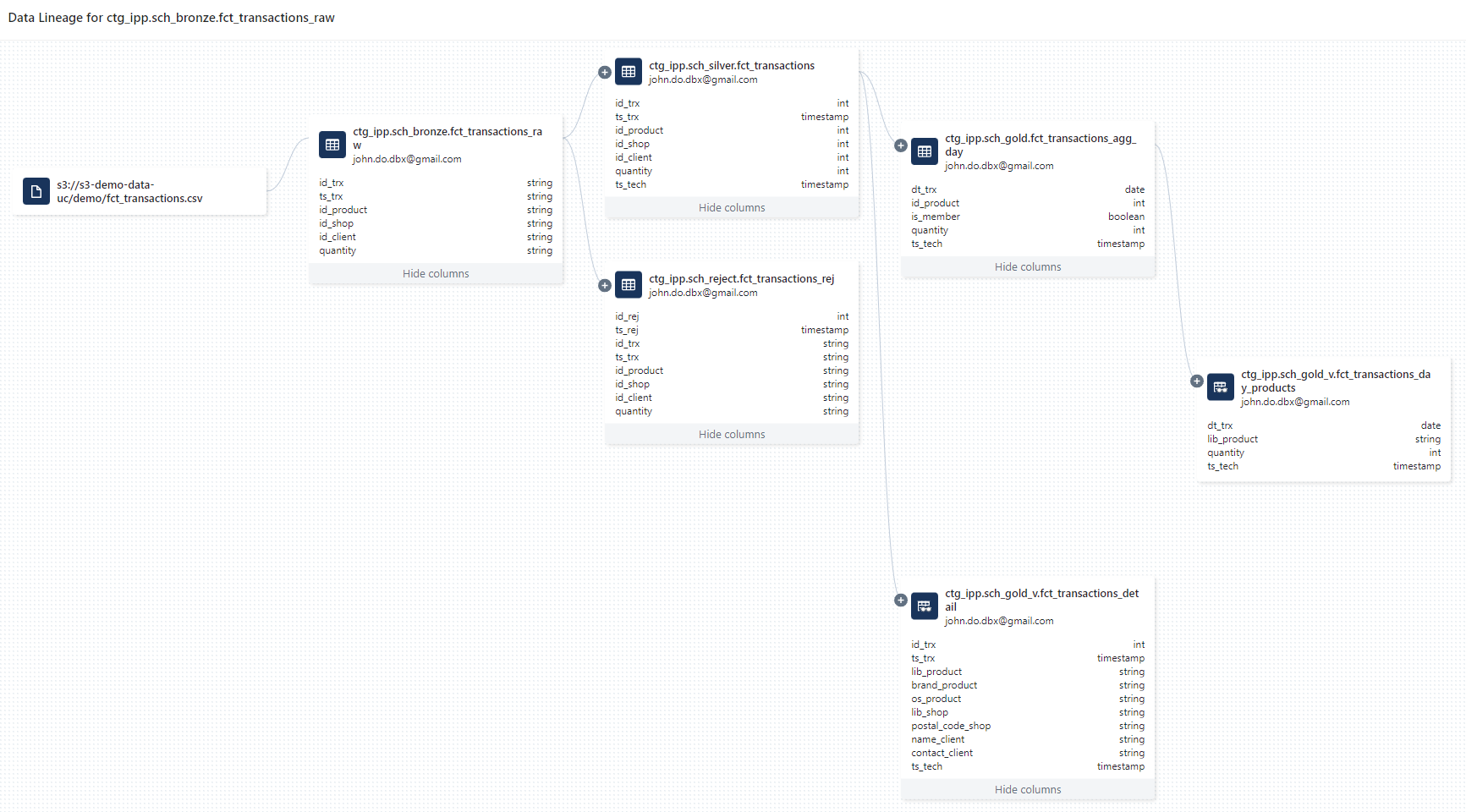
Display of the list of source data used by the ingestion into the ctg_ipp.sch_bronze.fct_transactions_raw table :
Display of the list of objects that have the ctg_ipp.sch_bronze.fct_transactions_raw table as one of their data sources :
Data Lineage information export with Databricks REST API
Prerequisite :
- Have the
Curltool installed - Have the
jqtool installed
Set up the REST API access and environment variables :
- Creation opf a
.netrcfile to mange the access to the REST API :
1# Create the folder where the .netrc file will be stored
2mkdir ~/.databricks
3
4# Create the .netrc file
5echo "machine <url workspace databricks without https://>
6login token
7password <token user databricks>
8" > ~/.databricks/.netrc
- Creation of the environment variables and alias :
1# Create an alias to use the tool curl with .netrc file
2alias dbx-api='curl --netrc-file ~/.databricks/.netrc'
3
4# Create an environment variable with Databricks API Url
5export DBX_API_URL="<url workspace databricks with https://>"
Get informations at the ctg_ipp.sch_silver.fct_transactions object level :
1# 1. Get the list of upstreams elements from an object
2dbx-api -X GET -H 'Content-Type: application/json' ${DBX_API_URL}/api/2.0/lineage-tracking/table-lineage -d '{"table_name": "ctg_ipp.sch_silver.fct_transactions", "include_entity_lineage": true}}' | jq '.upstreams[]'
3
4# 2. Get the list of downstreams elements from an object
5dbx-api -X GET -H 'Content-Type: application/json' ${DBX_API_URL}/api/2.0/lineage-tracking/table-lineage -d '{"table_name": "ctg_ipp.sch_silver.fct_transactions", "include_entity_lineage": true}}' | jq '.downstreams[]'
JSON result of the list of elements used to ingest data into the ctg_ipp.sch_silver.fct_transactions object :
1{
2 "tableInfo": {
3 "name": "fct_transactions_raw",
4 "catalog_name": "ctg_ipp",
5 "schema_name": "sch_bronze",
6 "table_type": "TABLE"
7 },
8 "queryInfos": [
9 {
10 "workspace_id": 1198890856567221,
11 "query_id": "40af215d-e21d-4933-b207-c478b78a38d6"
12 }
13 ]
14}
JSON result of the list of elements using the ctg_ipp.sch_silver.fct_transactions object
1{
2 "tableInfo": {
3 "name": "fct_transactions_detail",
4 "catalog_name": "ctg_ipp",
5 "schema_name": "sch_gold_v",
6 "table_type": "PERSISTED_VIEW"
7 },
8 "queryInfos": [
9 {
10 "workspace_id": 1198890856567221,
11 "query_id": "40af215d-e21d-4933-b207-c478b78a38d6"
12 },
13 {
14 "workspace_id": 1198890856567221,
15 "query_id": "bf2570b5-bfd8-444d-b2a7-d896192f063f"
16 }
17 ]
18}
19{
20 "tableInfo": {
21 "name": "fct_transactions_agg_day",
22 "catalog_name": "ctg_ipp",
23 "schema_name": "sch_gold",
24 "table_type": "TABLE"
25 },
26 "queryInfos": [
27 {
28 "workspace_id": 1198890856567221,
29 "query_id": "40af215d-e21d-4933-b207-c478b78a38d6"
30 },
31 {
32 "workspace_id": 1198890856567221,
33 "query_id": "bf2570b5-bfd8-444d-b2a7-d896192f063f"
34 }
35 ]
36}
Get information from ctg_ipp.sch_silver.fct_transactions object at the quantity column level :
1# 1. Get the list of upstreams columns from a column
2dbx-api -X GET -H 'Content-Type: application/json' ${DBX_API_URL}/api/2.0/lineage-tracking/column-lineage -d '{"table_name": "ctg_ipp.sch_silver.fct_transactions", "column_name": "quantity"}}' | jq '.upstream_cols[]'
3
4# 2. Get the list of downstreams columns from a column
5dbx-api -X GET -H 'Content-Type: application/json' ${DBX_API_URL}/api/2.0/lineage-tracking/column-lineage -d '{"table_name": "ctg_ipp.sch_silver.fct_transactions", "column_name": "quantity"}}' | jq '.downstream_cols[]'
JSON result of the list of columns used to ingest data into the quantity column of the ctg_ipp.sch_silver.fct_transactions object :
1{
2 "name": "quantity",
3 "catalog_name": "ctg_ipp",
4 "schema_name": "sch_bronze",
5 "table_name": "fct_transactions_raw",
6 "table_type": "TABLE",
7 "path": "s3://s3-dbx-metastore-uc/metastore-sandbox/13a746fa-c056-4b32-b6db-9d31c0d1eecf/tables/66cf0444-e436-4936-9106-1f930a884f23"
8}
JSON result of the list of columns using the quantity column from the ctg_ipp.sch_silver.fct_transactions object :
1{
2 "name": "quantity",
3 "catalog_name": "ctg_ipp",
4 "schema_name": "sch_gold",
5 "table_name": "fct_transactions_agg_day",
6 "table_type": "TABLE",
7 "path": "s3://s3-dbx-metastore-uc/metastore-sandbox/13a746fa-c056-4b32-b6db-9d31c0d1eecf/tables/9c724ab7-e48b-40fb-8105-a8bc292b591c"
8}
Clean environment
You will find, below, all the instructions needed to clean the environment.
Drop elements from Unity Catalog using SQL statements:
1-- Delete the Catalog with CASCADE option (to delete all objects)
2DROP CATALOG IF EXISTS ctg_ipp CASCADE;
3DROP CATALOG IF EXISTS ctg_ext CASCADE;
Deleting data used on the AWS S3 resource:
1# Delete all files stored in the AWS S3 resource
2aws s3 rm "s3://s3-demo-data-uc/demo/" --recursive
Conclusion
The Data Explorer tool makes it easy to explore data in the Unity Catalog Metastore and to manage rights on objects without knowing SQL commands.
The Data Lineage information captured by the Unity Catalog solution allows to have a certain amount of information on the data life cycle as well as on the list of elements using a specific object. This makes it easy to have a list of elements (notebooks, workflows, pipelines, queries, etc.) that use the object and may be impacted by a modification of an object. This also allows for visualization and navigation based on Data Lineage information (links between objects down to the column level).
Warning: The constraint of the last 30 days (rolling window) for the capture of information can be very limiting in the context of an application having treatments with a frequency greater than or equal to one month.