
Databricks : Unity Catalog - First Step - Part 5 - Delta Live Tables
We are going to discover the Delta Live Tables framework with the Unity Catalog solution (instead of the Hive Metastore).
We’re going to focus on the specific elements from the Unity Catalog solution.
The use of the Unity Catalog solution with the Delta Live Tables framework was in “Public Preview” at the time of writing this article in early June 2023.
We’re going to use a Databricks account on AWS to make this discovery.
What’s Delta Live Tables
Overview
Delta Live Tables is a declarative framework for defining all the elements of an ETL processing pipeline.
This framework allows you to work in Python or SQL.
This framework lets you define objects in a Python script or in a Python or SQL notebook, which is then executed by a DLT (Delta Live Tables) pipeline using the “Workflows” functionality.
This framework is based on the following three types of objects to manage the orchestration of all the tasks in a DLT pipeline :
- Streaming Table : This corresponds to the SQL term
STREAMING TABLE <objet> - Materialized View : This corresponds to the SQL term
LIVE TABLE <objet> - View : This corresponds to the SQL term
TEMPORARY LIVE VIEW <objet>orTEMPORARY STREAMING LIVE VIEW <objet>
You could find full details of costs and features available for each edition type with this link A concise overview of the different editions :
- DLT Core :
- Allows you to manage basic functionality
- DLT Pro :
- Allows you to manage all the functions of the “DLT Core” edition, including Change Data Capture (CDC) and Slow Changing Dimension (SCD) type 2 object (very useful for simplifying referential data management when you want to keep track of changes)
- DLT Advanced :
- Allows you to manage all the functions of the “DLT Pro” edition, as well as all data quality management functions (mainly the definition of constraints (expectations) and their observability (metrics)).
Regarding objects
Regarding the Streaming Table object :
- This object can be used to manage the streaming of a data source and read a record only once (Spark Structured Streaming).
- Element management (checkpoint, etc.) is handled by default by the DLT framework.
- Data source must be append-only
- If the data source is managed with Auto Loader, an additional column named
_rescued_datawill be created by default to handle malformed data. - Expectations can be defined at object level
- To read a “Streaming table” object in the same DLT pipeline, use the syntax
STREAM(LIVE.<object>)(SQL) ordlt.read_stream("<object>")(Python). - It is possible to define the ingestion of data from a “Streaming Table” object with a type 2 Slow Changing Dimension process automatically managed by the DLT framework.
- This makes it very easy to set up history management for referential data from a source using CDC (Change Data Capture) or CDF (Change Data Feed).
- Since objects are managed by the DLT framework when a DLT pipeline is executed, it’s not recommended to changes data (update, delete, insert) outside the DLT pipeline.
- It is possible to perform modifications (DML-type queries) with certain limitations on “Streaming Table” objects, but this is not recommended and not all operations are supported.
Regarding the Materialized View object :
- This object is used to manage the refresh of object data according to its state when the DLT pipeline is executed. The DLT framework defines what it should update according to the state of the sources and the target.
- Expectations can be defined at object level
- To read a “Materialized View” object in the same DLT pipeline, use the syntax
LIVE.<object>(SQL) ordlt.read("<object>")(Python). - It is not possible to execute DML (Update, Delete, Insert) queries on a “Materialized View” object, as the accessible object is not defined as a Delta table.
- To read a “Materialized View” object outside the DLT pipeline, you need to use a Shared Cluster or a SQL Warehouse Pro or Serverless (recommended).
Regarding the View object :
- This object is used to define a temporary view (encapsulated query) of a data source, which will only exist during execution of the DLT pipeline.
- The encapsulated query is executed each time the object is read
- Expectations can be defined at object level
Regarding data quality management
Data quality management is done by declaring constraints (expectations) on objects:
- SQL Syntax :
CONSTRAINT expectation_name EXPECT (expectation_expr) [ON VIOLATION { FAIL UPDATE | DROP ROW }]
When you define a constraint (expectation) on an object, the DLT framework will check when ingesting the record and perform the defined action :
CONSTRAINT expectation_name EXPECT (expectation_expr): When there is no action defined, the records not respecting the constraint will be inserted in the object and information will be added in the event logs of the DLT pipeline with the number of records concerned for this object.CONSTRAINT expectation_name EXPECT (expectation_expr) ON VIOLATION FAIL UPDATE: When the action defined is “FAIL UPDATE”, the DLT pipeline will stop in error at the first record not respecting the constraint with the error message in the event logs of the DLT pipeline.CONSTRAINT expectation_name EXPECT (expectation_expr) ON VIOLATION DROP ROW: When the action defined is “DROP ROW”, the records that do not respect the constraint will not be inserted into the object and information will be added in the event logs of the DLT pipeline with the number of records concerned for this object.
Regarding DLT pipeline
In order to be able to run a script (Python) or notebook (SQL or Python) with the DLT framework, it is necessary to create a DLT pipeline specifying the desired edition.
The definition of the DLT pipeline is done using the “Workflows” functionality. Access is as follows :
- Click on the “Data Science & Engineering” view in the sidebar
- Click on “Workflows” option in the sidebar
- Click on the “Delta Live Tables” tab
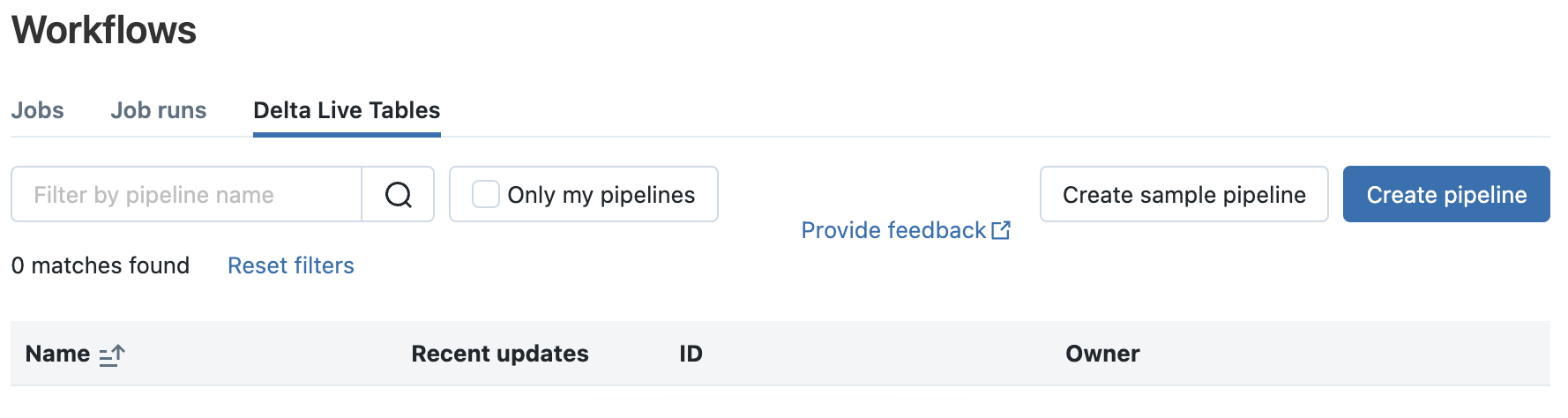
From this screen, you will be able to manage DLT pipelines (creation, deletion, configuration, modification) and view the different executions (within the limit of the observability data retention period defined for each pipeline)
Useful information for creating a DLT pipeline:
- General :
- Product edition : Edition to be chosen among DLT Core, DLT Pro and DLT Advanced, this will define the usable functionalities as well as one of the criteria of the cost of the DLT pipeline execution
- Pipeline mode :
- Triggered : Allows to manage the execution in batch mode and therefore to stop the cluster after execution of the DLT pipeline
- Continuous : Allows to manage the execution in streaming mode and therefore to execute the pipeline continuously to process the data as soon as it arrives.
- Source Code : Allows to define the script (Python) or the Notebook (Python or SQL) to be executed by the DLT pipeline
- Destination
- Storage Option : Choose Unity Catalog to use the Unity Catalog solution with the DLT framework
- Catalog : Define the target catalog for the DLT pipeline (catalog that contains the target schema of the DLT pipeline)
- Target schema : Define the target schema for the DLT pipeline (schema that will be used to manage DLT pipeline objects)
- Compute
- Cluster mode : To define whether you want a fixed number of workers (Fixed size) or which adapts to the workload within the limits indicated (Enhanced autoscaling, Legacy autoscaling)
- Workers : Allows you to define the number of workers if the mode is fixed or the minimum and maximum number of workers if the mode is not fixed
Useful information after creating the DLT pipeline :
- Execution Mode :
- Development : In this mode, the cluster used by the DLT pipeline will stop only after 2h (by default) to avoid the restart time of a cluster and there is no automatic restart management.
- It is possible to modify the delay time before cluster shutdown by configuring the parameter
pipelines.clusterShutdown.delaywith the desired value (for example “300s” for 5 minutes) - Example :
{"configuration": {"pipelines.clusterShutdown.delay": "300s"}})
- It is possible to modify the delay time before cluster shutdown by configuring the parameter
- Production : In this mode, the cluster stops automatically after the execution of the DLT pipeline and it restarts automatically in the event of a technical issue (memory leak, authorizations, startup, etc.)
- Development : In this mode, the cluster used by the DLT pipeline will stop only after 2h (by default) to avoid the restart time of a cluster and there is no automatic restart management.
- Schedule :
- Allows you to define a trigger constraint for the DLT pipeline execution
- Execution :
- Start : To run the DLT pipeline considering only new available data
- Start with Full refresh all : To run the DLT pipeline considering all available data
- Select tables for refresh : To define the objects that we want to update during the DLT pipeline execution (partial execution)
Warning :
- It is not possible to run the defined script or notebook locally or with a Databricks cluster.
- You will get the following message :
This Delta Live Tables query is syntactically valid, but you must create a pipeline in order to define and populate your table.
- You will get the following message :
- A DLT pipeline corresponds to one script or one notebook only, therefore if you want to run several scripts or notebooks, you must use the “Job” feature (from the “Workflows” feature) to orchestrate the execution of several DLT pipelines.
- Execute the “Job” will run the DLT pipelines with the defined constraints and orchestration
- It is only possible to access an object with the syntax of the DLT framework within the same DLT pipeline, if you need to read an object outside the DLT pipeline then it will be accessed as an external object and he will not be tracked in the graph and in the event logs of the DLT pipeline.
- Syntax for accessing an object within the same DLT pipeline :
dlt.read(<object>)ordlt.read_stream(<object>)with Python andLIVE.<object>orSTREAM(LIVE.<object>)with SQL.
- Syntax for accessing an object within the same DLT pipeline :
Regarding the data management associated with a DLT pipeline (maintenance) :
- The DLT framework performs automatic maintenance of each object (Delta table) updated within 24h after the last execution of a DLT pipeline.
- By default, the system performs a full OPTIMIZE operation, followed by a VACUUM operation
- If you do not want a Delta table to be automated by default, you must use the
pipelines.autoOptimize.managed = falseproperty when defining the object (TBLPROPERTIES).
- When you delete a DLT pipeline, all objects defined in the DLT pipeline and located in the target schema will be deleted automatically, and the internal Delta tables will be deleted during automatic maintenance (within 24 hours after the last action on the DLT pipeline).
Restrictions :
- It is not possible to mix the use of Hive Metastore with the Unity Catalog solution or to switch between the two metastores for the target of the DLT pipeline after its creation.
- All tables created and updated by a DLT pipeline are Delta tables
- Objects managed by the DLT framework can only be defined once, that means they can only be the target in one DLT pipeline only (can’t define the same object in the same target schema in two different DLT pipelines )
- A Databricks Workspace is limited to 100 DLT pipeline updates
How it works with Unity Catalog
Overview
In order to use Unity Catalog, when creating the DLT pipeline you must fill the destination with the Unity Catalog information (with target catalog and target schema).
It is not possible to use the recommended “three namespaces” notation catalog.schema.object to access an object managed by the DLT framework.
Objects are defined by name only, and it is the definition of the target catalog and target schema in the DLT pipeline that defines where the objects will be created.
Note: read access to objects not managed by the DLT framework is possible using classic spark syntax (spark.table("catalog.schema.object")).
In order to use Unity Catalog with Delta Live Tables, you must have the following rights as the owner of the DLT pipeline :
- You must have “USE CATALOG” rights on the target catalog
- You must have “USE SCHEMA” rights on the target schema
- You must have “CREATE MATERIALIZED VIEW” rights on the target schema to be able to create “Materialized View” objects
- You must have “CREATE TABLE” rights on the target schema to be able to create “Streaming table” objects
Advice on file ingestion :
- When retrieving information (metadata) about ingested files, it is not possible to use the
input_file_namefunction, which is not supported by Unity Catalog.- Use the
_metadatacolumn to retrieve the necessary information, such as the file name_metadata.file_name - You will find the list of information available in the
_metadatacolumn on the official documentation
- Use the
Regarding object management by the DLT framework (during DLT pipeline execution)
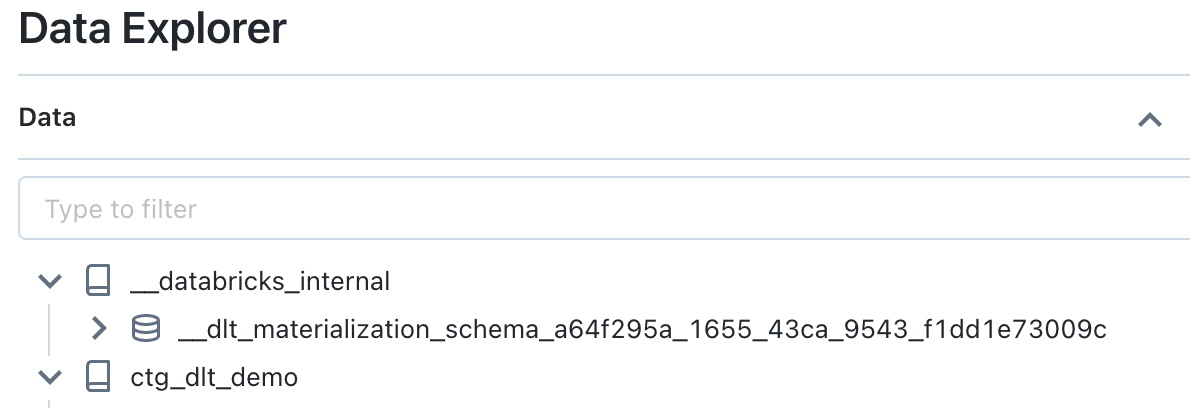
In reality, when you define an object with the DLT framework, an object will be created in the target schema indicated in the DLT pipeline (with a specific type that will not be a Delta table directly) and a Delta table will be created in an internal schema (managed by the system and not accessible by default to users) to manage the storage of data from the object defined with the DLT framework.
The internal schema is located in the catalog named __databricks__internal and owned by System.
The default schema name is : __dlt_materialization_schema_<pipeline_id>.
In this schema, you’ll find all the Delta tables whose storage is managed directly by the DLT framework (the owner of the Delta tables is the owner of the DLT pipeline), as well as the Delta table __event_log, which will contain all the event logs of DLT pipeline executions.
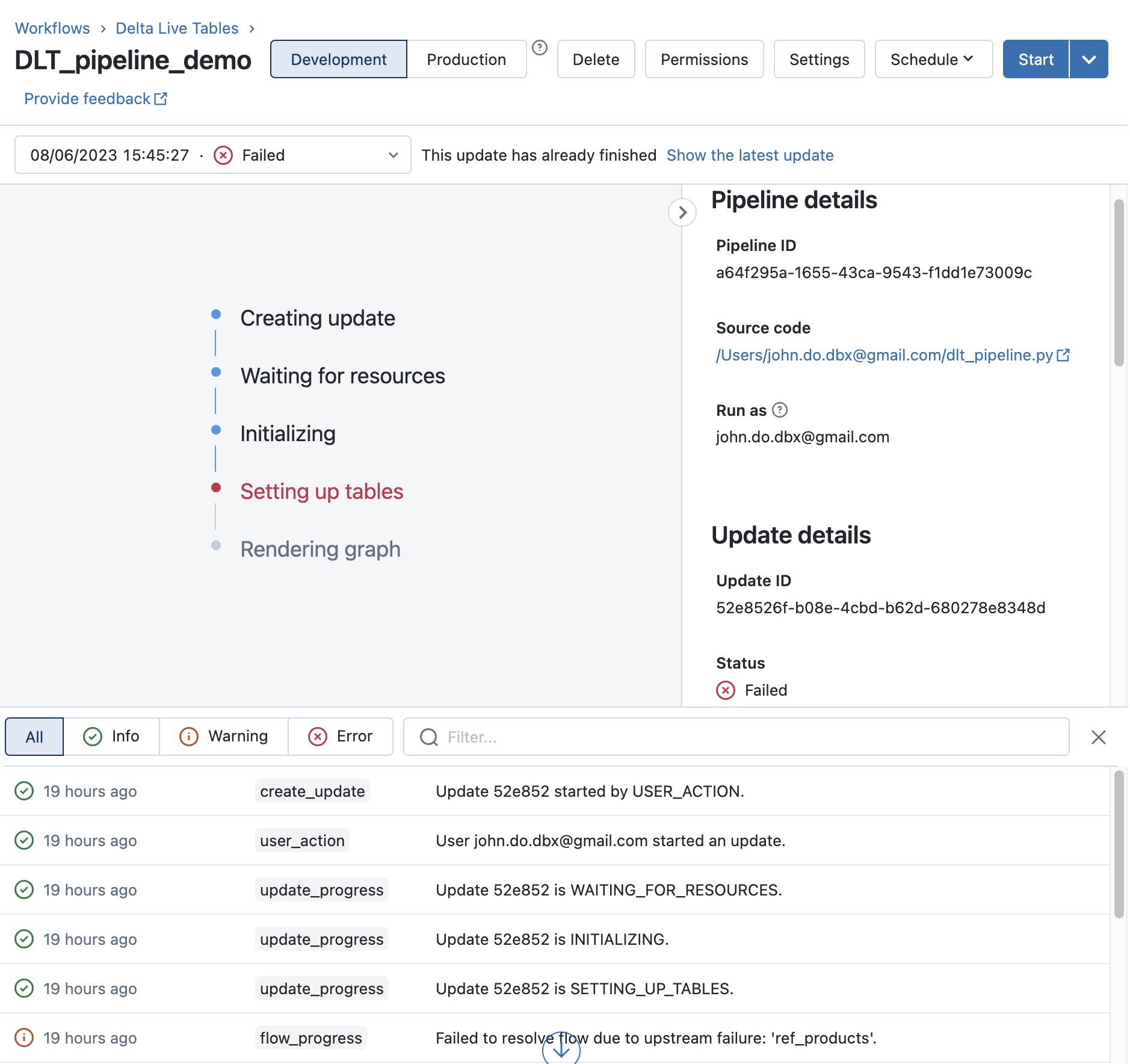
Example of the definition of a “Streaming Table” object in the “ctg.sch” schema in a DLT pipeline whose identifier is “0000”. The data management will be done as follows:
- Creating a Delta table (with a unique identifier) in an internal system-maintained schema named
__databricks__internal.__dlt_materialization_schema_0000- With subdirectory (at the Delta data storage level)
_dlt_metadatacontaining acheckpointsdirectory to manage the information needed to manage streaming data ingestion
- With subdirectory (at the Delta data storage level)
- Creation of an object of type “STREAMING_TABLE” in the schema “ctg.sch” which refers to the Delta table created in the internal schema
__databricks__internal.__dlt_materialization_schema_0000- This allows accessing data from the internal Delta table with some constraints
Example of the definition of a “Materialized View” object in the “ctg.sch” schema in a DLT pipeline whose identifier is “0000”. The data management will be done as follows:
- Creating a Delta table (with a unique identifier) in an internal system-maintained schema named
__databricks__internal.__dlt_materialization_schema_0000- With subdirectory (at the Delta data storage level)
_dlt_metadatacontaining a_enzyme_logdirectory to manage the information needed by the Enzyme Project to manage the refresh of object data
- With subdirectory (at the Delta data storage level)
- Creation of an object of type “MATERIALIZED_VIEW” in the schema “ctg.sch” which refers to the Delta table created in the internal schema
__databricks__internal.__dlt_materialization_schema_0000- This allows accessing data from the internal Delta table with some constraints
Note: The “View” object does not require object creation in the target or internal schema.
Restrictions
It is also possible to take advantage of the Data Lineage functionality of the Unity Catalog solution with the following limitations:
- There is no trace of source objects that are not defined in a DLT pipeline, so the lineage view is incomplete when the DLT pipeline does not contain all elements.
- For example, if a referential data source is used as the source of a “Materialized View” object, the lineage will not have the information about this source.
- Lineage doesn’t take temporary views into account, and this can prevent a link being made between the view sources and the target object.
Limitations (non-exhaustive) when using Unity Catalog with Delta Live Table :
- It is not possible to change the owner of a pipeline using Unity Catalog.
- Objects are managed/stored only in Unity Catalog’s default Metastore storage, it is not possible to define another path (managed or external).
- Delta Sharing cannot be used with objects managed by the DLT framework.
- DLT pipeline event logs can only be read by the DLT pipeline (by default).
- Access to data on certain objects can only be made using a SQL Warehouse (Pro or Serverless) or a Cluster (Shared).
Set-up the environment
Context
Prerequisite :
- Creation of the
grp_demogroup - Create
john.do.dbx@gmail.comuser and add user togrp_demogroup. - Create a SQL Warehouse and give use rights to the
grp_demogroup - Metastore named
metastore-sandboxwith Storage Credential namedsc-metastore-sandboxto store default data in AWS S3 resource nameds3-dbx-metastore-uc. - Add the right to create a catalog on the Metastore Unity Catalog and the right to access files
1GRANT CREATE CATALOG on METASTORE to grp_demo;
2GRANT SELECT ON ANY FILE TO grp_demo;
To make the examples easier to understand, we’ll use the following list of environment variables:
1# Create an alias to use the tool curl with .netrc file
2alias dbx-api='curl --netrc-file ~/.databricks/.netrc'
3
4# Create an environment variable with Databricks API URL
5export DBX_API_URL="<Workspace Databricks AWS URL>"
6
7# Init local variables
8export LOC_PATH_SCRIPT="<Local Path for the folder with the Python script>"
9export LOC_PATH_DATA="<Local Path for the folder with the CSV files>"
10# Name for DLT Script (Python)
11export LOC_SCRIPT_DLT="dlt_pipeline.py"
12# List CSV files for the first execution
13export LOC_SCRIPT_DATA_1=(ref_products_20230501.csv ref_clients_20230501.csv fct_transactions_20230501.csv)
14# List CSV files for the second execution
15export LOC_SCRIPT_DATA_2=(ref_clients_20230601.csv fct_transactions_20230601.csv)
16
17# Init Databricks variables (Workspace)
18# Path to store the CSV files
19export DBX_PATH_DATA="dbfs:/mnt/dlt_demo/data"
20# Name for the DLT pipeline
21export DBX_DLT_PIPELINE_NAME="DLT_pipeline_demo"
22# DLT pipeline Target Catalog
23export DBX_UC_CATALOG="CTG_DLT_DEMO"
24# DLT pipeline Target Schema
25export DBX_UC_SCHEMA="SCH_DLT_DEMO"
26# Path to store the DLT Script (Python)
27export DBX_USER_NBK_PATH="/Users/john.do.dbx@gmail.com"
28
29# Init Pipeline variable
30export DBX_DLT_PIPELINE_ID=""
Schématisation de l’environnement
Diagram of the DLT pipeline we are going to set up :
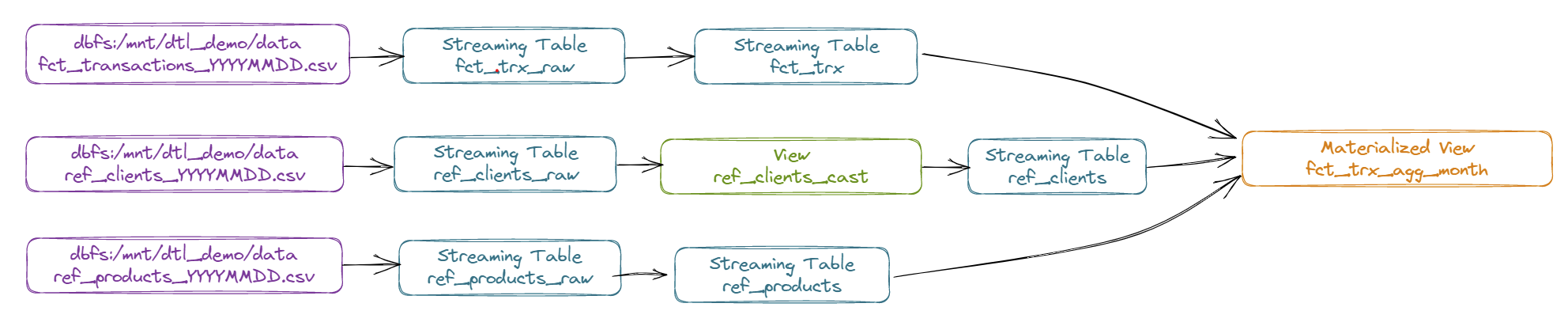
Details of the DLT pipeline:
- Stream product referential data from CSV file (ref_products_YYYMMDD.csv) to a “Streaming Table” object named “REF_PRODUCTS_RAW”.
- Stream data from the “REF_PRODUCTS_RAW” object to a “Streaming Table” object named “REF_PRODUCTS”.
- Stream customer referential data from CSV file (ref_clients_YYYMMDD.csv) to a “Streaming Table” object named “REF_CLIENTS_RAW” (with Change Data Feed enabled)
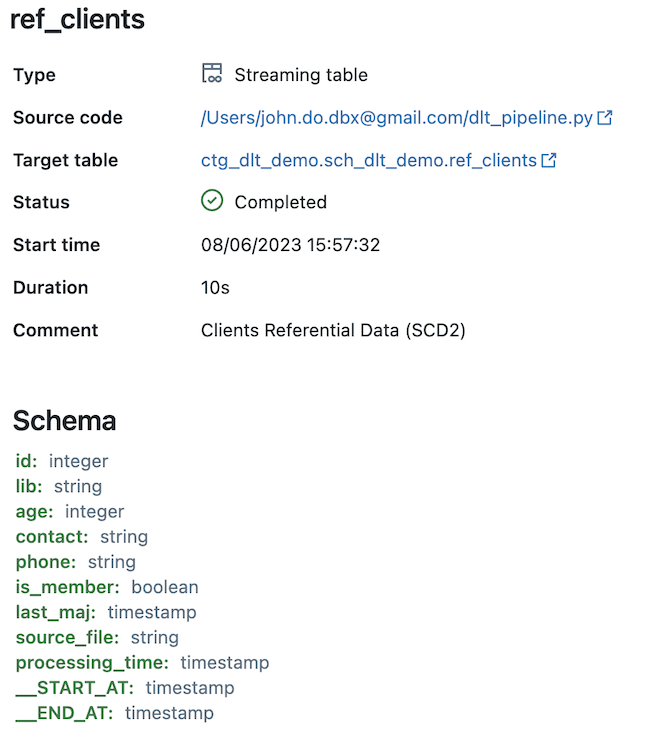
- Stream data from the “REF_PRODUCTS_RAW” object to a “Streaming Table” object using SCD Type 2 functionality and named “REF_CLIENTS”.
- Using a view named “REF_CLIENTS_CAST” to transform upstream data
- Stream transaction data from CSV file (fct_transactions_YYYMMDD.csv) to a “Streaming Table” object named “FCT_TRX_RAW”.
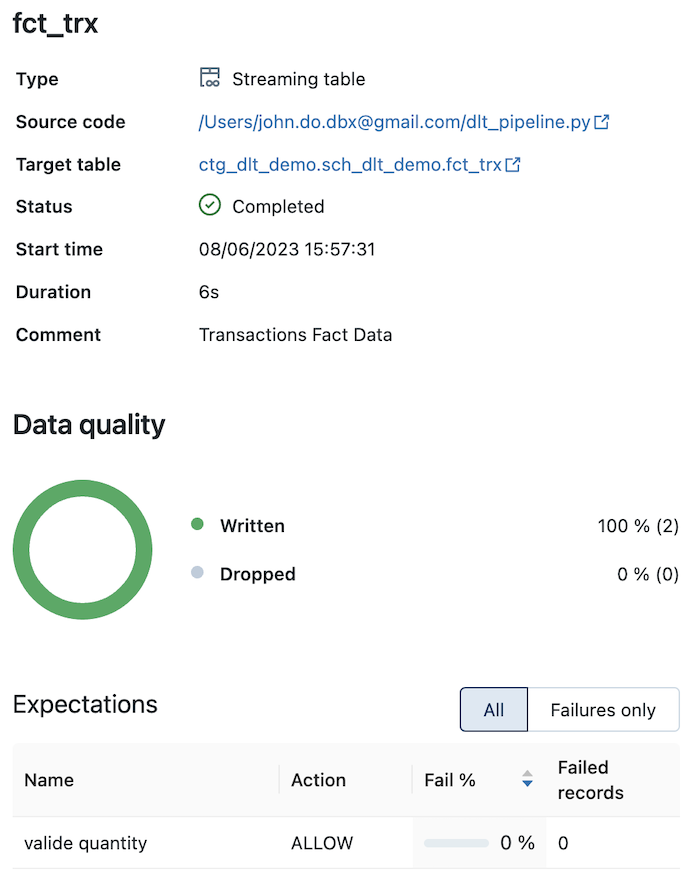
- Ingest data in a “Streaming Table” object named “FCT_TRX” from the “FCT_TRX_RAW” object, applying a constraint on the “quantity” information which must not be equal to 0.
- Feed a “Materialized View” object named “FCT_TRX_AGG_MONTH” from the “FCT_TRX”, “REF_CLIENTS” and “REF_PRODUCTS” objects to aggregate sales by month, customer and product.
Setting up a dataset
The dataset will be build of two batches in order to run two executions and put data refreshment into practice.
Dataset for batch n°1 (first execution of the DLT pipeline) :
Content of the file ref_clients_20230501.csv :
1id,lib,age,contact,phone,is_member,last_maj
21,Maxence,23,max1235@ter.tt,+33232301123,No,2023-01-01 11:01:02
32,Bruce,26,br_br@ter.tt,+33230033155,Yes,2023-01-01 13:01:00
43,Charline,40,ccccharline@ter.tt,+33891234192,Yes,2023-03-02 09:00:00
Content of the file ref_products_20230501.csv :
1id,lib,brand,os,last_maj
21,Pixel 7 Pro,Google,Android,2023-01-01 09:00:00
32,Iphone 14,Apple,IOS,2023-01-01 09:00:00
43,Galaxy S23,Samsung,Android,2023-01-01 09:00:00
Content of the file fct_transactions_20230501.csv :
1id_trx,ts_trx,id_product,id_shop,id_client,quantity
21,2023-04-01 09:00:00,1,2,1,1
32,2023-04-01 11:00:00,1,1,1,3
Dataset for batch n°2 (second execution of the DLT pipeline) :
Content of the file ref_clients_20230601.csv :
1id,lib,age,contact,phone,is_member,last_maj
22,Bruce,26,br_br@ter.tt,+33990033100,Yes,2023-04-01 12:00:00
Content of the file fct_transactions_20230601.csv :
1id_trx,ts_trx,id_product,id_shop,id_client,quantity
23,2023-04-03 14:00:00,1,2,1,1
34,2023-04-05 08:00:00,3,1,2,9
45,2023-04-06 10:00:00,1,2,1,3
56,2023-04-06 12:00:00,2,2,1,1
67,2023-01-01 13:00:00,1,2,1,0
78,2023-04-10 18:30:00,2,1,2,11
89,2023-04-10 18:30:00,3,1,2,2
Setting up the objects on the Unity Catalog Metastore
Steps for creating the necessary objects :
- Create a catalog named
ctg_dlt_demo. - Create a schema named
sch_dlt_demo.
1-- 1. Create Catalog
2CREATE CATALOG IF NOT EXISTS ctg_dlt_demo
3COMMENT 'Catalog to store the dlt demo objects';
4
5-- 2. Create Schema
6CREATE SCHEMA IF NOT EXISTS ctg_dlt_demo.sch_dlt_demo
7COMMENT 'Schema to store the dlt demo objects';
Creation of the python script containing the objects definition for the DLT framework
The script is named dlt_pipeline.py and will be copied to the Databricks Workspace (it will be used by the DLT pipeline).
The Python script contains the following code :
1"""Pipeline DLT demo"""
2import dlt
3from pyspark.sql.functions import col, current_timestamp, expr, sum
4
5# Folder to store data for the demo
6PATH_DATA = "dbfs:/mnt/dlt_demo/data"
7
8
9###################
10## Products Data ##
11###################
12
13# Create the streaming table named REF_PRODUCTS_RAW
14@dlt.table(
15 name="REF_PRODUCTS_RAW",
16 comment="Raw Products Referential Data",
17 table_properties={"quality" : "bronze"},
18 temporary=False)
19def get_products_raw():
20 return spark.readStream.format("cloudFiles") \
21 .option("cloudFiles.format", "csv") \
22 .option("delimiter",",") \
23 .option("header","true") \
24 .load(PATH_DATA+"/ref_products_*.csv") \
25 .select("*"
26 ,col("_metadata.file_name").alias("source_file")
27 ,current_timestamp().alias("processing_time"))
28
29# Create the streaming table named REF_PRODUCTS
30@dlt.table(
31 name="REF_PRODUCTS",
32 comment="Products Referential Data",
33 table_properties={"quality" : "silver"},
34 temporary=False)
35def get_products():
36 return dlt.read_stream("REF_PRODUCTS_RAW") \
37 .where("_rescued_data is null") \
38 .select(col("id").cast("INT")
39 ,col("lib")
40 ,col("brand")
41 ,col("os")
42 ,col("last_maj").cast("TIMESTAMP")
43 ,col("source_file")
44 ,col("processing_time"))
45
46
47###################
48## Clients Data ##
49##################
50
51# Create the streaming table named REF_CLIENTS_RAW
52@dlt.table(
53 name="REF_CLIENTS_RAW",
54 comment="Raw Clients Referential Data",
55 table_properties={"quality" : "bronze", "delta.enableChangeDataFeed" : "true"},
56 temporary=False)
57def get_products_raw():
58 return spark.readStream.format("cloudFiles") \
59 .option("cloudFiles.format", "csv") \
60 .option("delimiter",",") \
61 .option("header","true") \
62 .load(PATH_DATA+"/ref_clients_*.csv") \
63 .select("*"
64 ,col("_metadata.file_name").alias("source_file")
65 ,current_timestamp().alias("processing_time"))
66
67# Create the temporary view named REF_CLIENTS_RAW_CAST
68@dlt.view(
69 name="REF_CLIENTS_RAW_CAST"
70 ,comment="Temp view for Clients Raw Casting")
71def view_clients_cast():
72 return dlt.read_stream("REF_CLIENTS_RAW") \
73 .select(expr("cast(id as INT) as id")
74 ,col("lib")
75 ,expr("cast(age as INT) as age")
76 ,col("contact")
77 ,col("phone")
78 ,expr("(is_member = 'Yes') as is_member")
79 ,expr("cast(last_maj as timestamp) as last_maj")
80 ,col("source_file")
81 ,col("processing_time"))
82
83# Create the streaming table named REF_CLIENTS (and using SCD Type 2 management)
84dlt.create_streaming_table(
85 name = "REF_CLIENTS",
86 comment = "Clients Referential Data (SCD2)"
87)
88
89# Apply modification (for SCD Type 2 management) based on the temporary view
90dlt.apply_changes(target = "REF_CLIENTS",
91 source = "REF_CLIENTS_RAW_CAST",
92 keys = ["id"],
93 sequence_by = col("last_maj"),
94 stored_as_scd_type = 2)
95
96
97#######################
98## Transactions Data ##
99#######################
100
101# Create the streaming table named FCT_TRX_RAW
102@dlt.table(
103 name="FCT_TRX_RAW",
104 comment="Raw Transactions Fact Data",
105 table_properties={"quality" : "bronze"},
106 partition_cols=["dt_tech"],
107 temporary=False)
108def get_transactions_raw():
109 return spark.readStream.format("cloudFiles") \
110 .option("cloudFiles.format", "csv") \
111 .option("delimiter",",") \
112 .option("header","true") \
113 .load(PATH_DATA+"/fct_transactions_*.csv") \
114 .select("*"
115 ,col("_metadata.file_name").alias("source_file")
116 ,current_timestamp().alias("processing_time")
117 ,expr("current_date() as dt_tech"))\
118
119
120# Create the streaming table named FCT_TRX (with expectation)
121@dlt.table(
122 name="FCT_TRX",
123 comment="Transactions Fact Data",
124 table_properties={"quality" : "silver"},
125 partition_cols=["dt_trx"],
126 temporary=False)
127@dlt.expect("valide quantity","quantity <> 0")
128def get_transactions():
129 return dlt.read_stream("FCT_TRX_RAW") \
130 .where("_rescued_data IS NULL") \
131 .select(expr("cast(id_trx as INT) as id_trx")
132 ,expr("cast(ts_trx as timestamp) as ts_trx")
133 ,expr("cast(id_product as INT) as id_product")
134 ,expr("cast(id_shop as INT) as id_shop")
135 ,expr("cast(id_client as INT) as id_client")
136 ,expr("cast(quantity as DOUBLE) as quantity")
137 ,col("source_file")
138 ,col("processing_time")
139 ,col("dt_tech")) \
140 .withColumn("_invalid_data",expr("not(coalesce(quantity,0) <> 0)")) \
141 .withColumn("dt_trx",expr("cast(ts_trx as date)"))
142
143
144# Create the Materialized View named FCT_TRX_AGG_MONTH
145@dlt.table(
146 name="FCT_TRX_AGG_MONTH",
147 comment="Transactions Fact Data Aggregate Month",
148 table_properties={"quality" : "gold"},
149 partition_cols=["dt_month"],
150 temporary=False)
151def get_transactions_agg_month():
152 data_fct = dlt.read("FCT_TRX").where("not(_invalid_data)")
153 data_ref_products = dlt.read("REF_PRODUCTS")
154 data_ref_clients = dlt.read("REF_CLIENTS").where("__END_AT IS NULL")
155 return data_fct.alias("fct").join(data_ref_products.alias("rp"), data_fct.id_product == data_ref_products.id, how="inner") \
156 .join(data_ref_clients.alias("rc"),data_fct.id_client == data_ref_clients.id, how="inner") \
157 .withColumn("dt_month",expr("cast(substring(cast(fct.dt_trx as STRING),0,7)||'-01' as date)")) \
158 .groupBy("dt_month","rc.lib","rc.contact","rp.brand") \
159 .agg(sum("fct.quantity").alias("sum_quantity")) \
160 .select(col("dt_month")
161 ,col("rc.lib")
162 ,col("rc.contact")
163 ,col("rp.brand")
164 ,col("sum_quantity").alias("quantity")
165 ,expr("current_timestamp() as ts_tech"))
Creating a DLT Pipeline
To create the DLT pipeline, we will follow these steps:
- Create a directory in the DBFS directory to store CSV files
- Copy the Python script to the Databricks Workspace
- Create the DLT pipeline (taking as source the Python script copied to the Workspace Databricks)
- Retrieve the DLT pipeline identifier in an environment variable named “DBX_DLT_PIPELINE_NAME”
Using Databricks REST APIs :
1# 1. Create the directory to store CSV files (on the DBFS)
2dbx-api -X POST ${DBX_API_URL}/api/2.0/dbfs/mkdirs -H 'Content-Type: application/json' -d "{
3 \"path\": \"${DBX_PATH_DATA}\"
4}"
5
6# 2. Copy the Python script into the Workspace
7dbx-api -X POST ${DBX_API_URL}/api/2.0/workspace/import -H 'Content-Type: application/json' -d "{
8 \"format\": \"SOURCE\",
9 \"path\": \"${DBX_USER_NBK_PATH}/${LOC_SCRIPT_DLT}\",
10 \"content\" : \"$(base64 -i ${LOC_PATH_SCRIPT}/${LOC_SCRIPT_DLT})\",
11 \"language\": \"PYTHON\",
12 \"overwrite\": \"true\"
13}"
14
15# 3. Create the DLT Pipeline based on the Python script
16dbx-api -X POST ${DBX_API_URL}/api/2.0/pipelines -H 'Content-Type: application/json' -d "
17{
18 \"continuous\": false,
19 \"name\": \"${DBX_DLT_PIPELINE_NAME}\",
20 \"channel\": \"PREVIEW\",
21 \"catalog\": \"${DBX_UC_CATALOG}\",
22 \"target\": \"${DBX_UC_SCHEMA}\",
23 \"development\": true,
24 \"photon\": false,
25 \"edition\": \"ADVANCED\",
26 \"allow_duplicate_names\": \"false\",
27 \"dry_run\": false,
28 \"configuration\": {
29 \"pipelines.clusterShutdown.delay\": \"600s\"
30 },
31 \"clusters\": [
32 {
33 \"label\": \"default\",
34 \"num_workers\": 1
35 }
36 ],
37 \"libraries\": [
38 {
39 \"notebook\": {
40 \"path\": \"${DBX_USER_NBK_PATH}/${LOC_SCRIPT_DLT}\"
41 }
42 }
43 ]
44}"
45
46# 4. Retrieve the Pipeline ID
47export DBX_DLT_PIPELINE_ID=`dbx-api -X GET ${DBX_API_URL}/api/2.0/pipelines | jq -r '.statuses[]|select(.name==$ENV.DBX_DLT_PIPELINE_NAME)|.pipeline_id'`
Running and Viewing a DLT Pipeline
Running a DLT Pipeline
In order to be able to run the first execution of the DLT pipeline, the following actions must be done :
- Copy the CSV data from batch n°1 to the DBFS directory (on the Databricks Workspace)
- Run the DLT pipeline
- Retrieve DLT pipeline status
Using Databricks REST APIs :
1# 1. Upload CSV Files (for execution)
2for file in ${LOC_SCRIPT_DATA_1}; do
3 dbx-api -X POST ${DBX_API_URL}/api/2.0/dbfs/put -H 'Content-Type: application/json' -d "{
4 \"path\": \"${DBX_PATH_DATA}/${file}\",
5 \"contents\": \"$(base64 -i ${LOC_PATH_DATA}/${file})\",
6 \"overwrite\": \"true\"
7 }"
8done
9
10# 2. Execute the DLT Pipeline
11dbx-api -X POST ${DBX_API_URL}/api/2.0/pipelines/${DBX_DLT_PIPELINE_ID}/updates -H 'Content-Type: application/json' -d "
12{
13 \"full_refresh\": false,
14 \"cause\": \"USER_ACTION\"
15}"
16
17# 3. Retrieve the status of the DLT Pipeline execution
18dbx-api -X GET ${DBX_API_URL}/api/2.0/pipelines/${DBX_DLT_PIPELINE_ID}/events | jq '.events[0]|.details'
In order to be able to run the second execution of the DLT pipeline, the following actions must be done :
- Copy the CSV data from batch n°2 to the DBFS directory (on the Databricks Workspace)
- Run the DLT pipeline
- Retrieve DLT pipeline status
Using Databricks REST APIs :
1# 1. Upload CSV Files (for execution)
2for file in ${LOC_SCRIPT_DATA_2}; do
3 dbx-api -X POST ${DBX_API_URL}/api/2.0/dbfs/put -H 'Content-Type: application/json' -d "{
4 \"path\": \"${DBX_PATH_DATA}/${file}\",
5 \"contents\": \"$(base64 -i ${LOC_PATH_DATA}/${file})\",
6 \"overwrite\": \"true\"
7 }"
8done
9
10# 2. Execute the DLT Pipeline
11dbx-api -X POST ${DBX_API_URL}/api/2.0/pipelines/${DBX_DLT_PIPELINE_ID}/updates -H 'Content-Type: application/json' -d "
12{
13 \"full_refresh\": false,
14 \"cause\": \"USER_ACTION\"
15}"
16
17# 3. Retrieve the status of the DLT Pipeline execution
18dbx-api -X GET ${DBX_API_URL}/api/2.0/pipelines/${DBX_DLT_PIPELINE_ID}/events | jq '.events[0]|.details'
DLT Pipeline Visualization
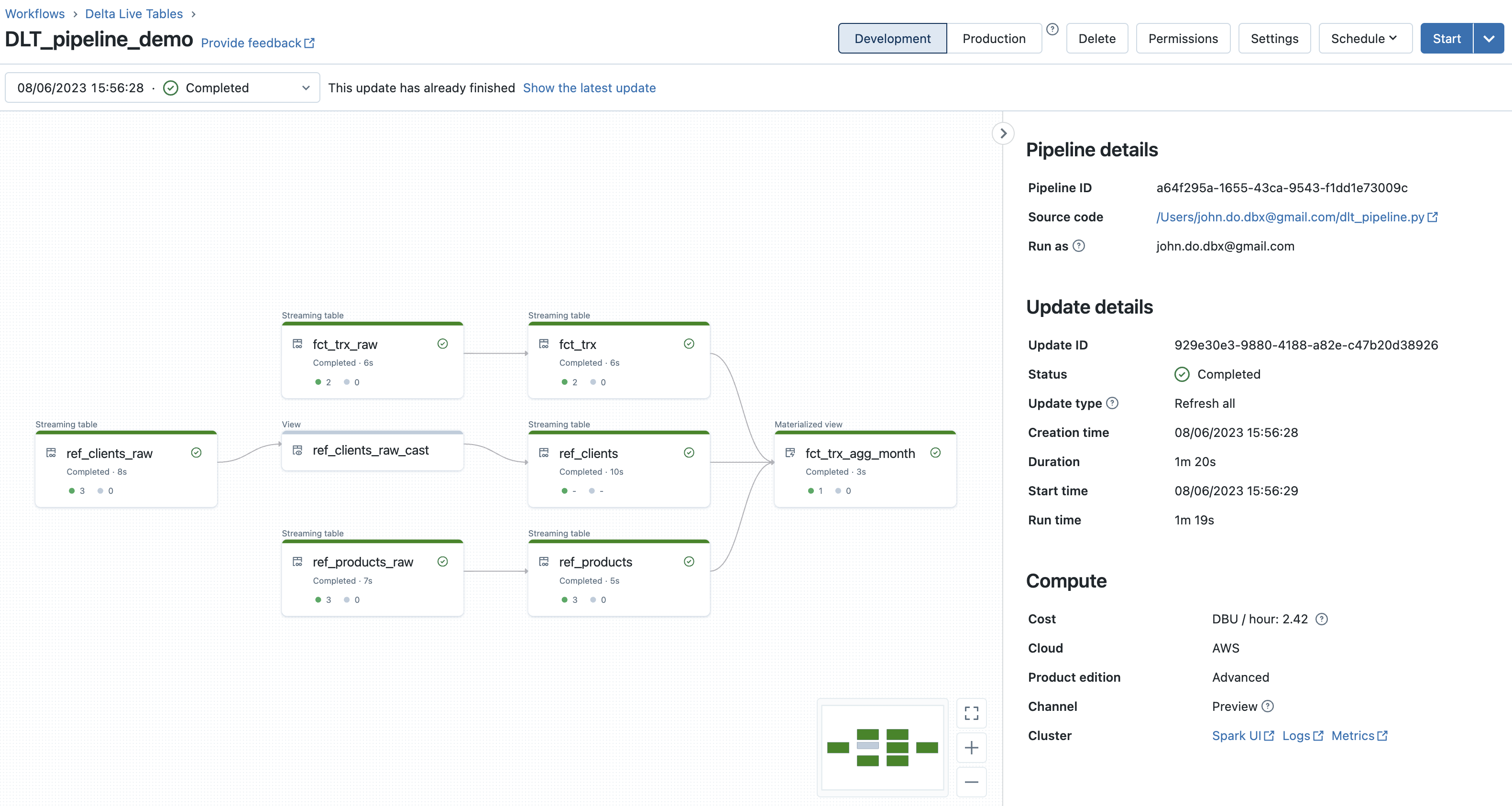
Result after the first execution of the DLT pipeline :
Detail of the “FCT_TRX” object (with the constraint/expectation on the “quantity” information) :
Detail of the “REF_CLIENTS” object (feeded by the SCD type 2 process) :
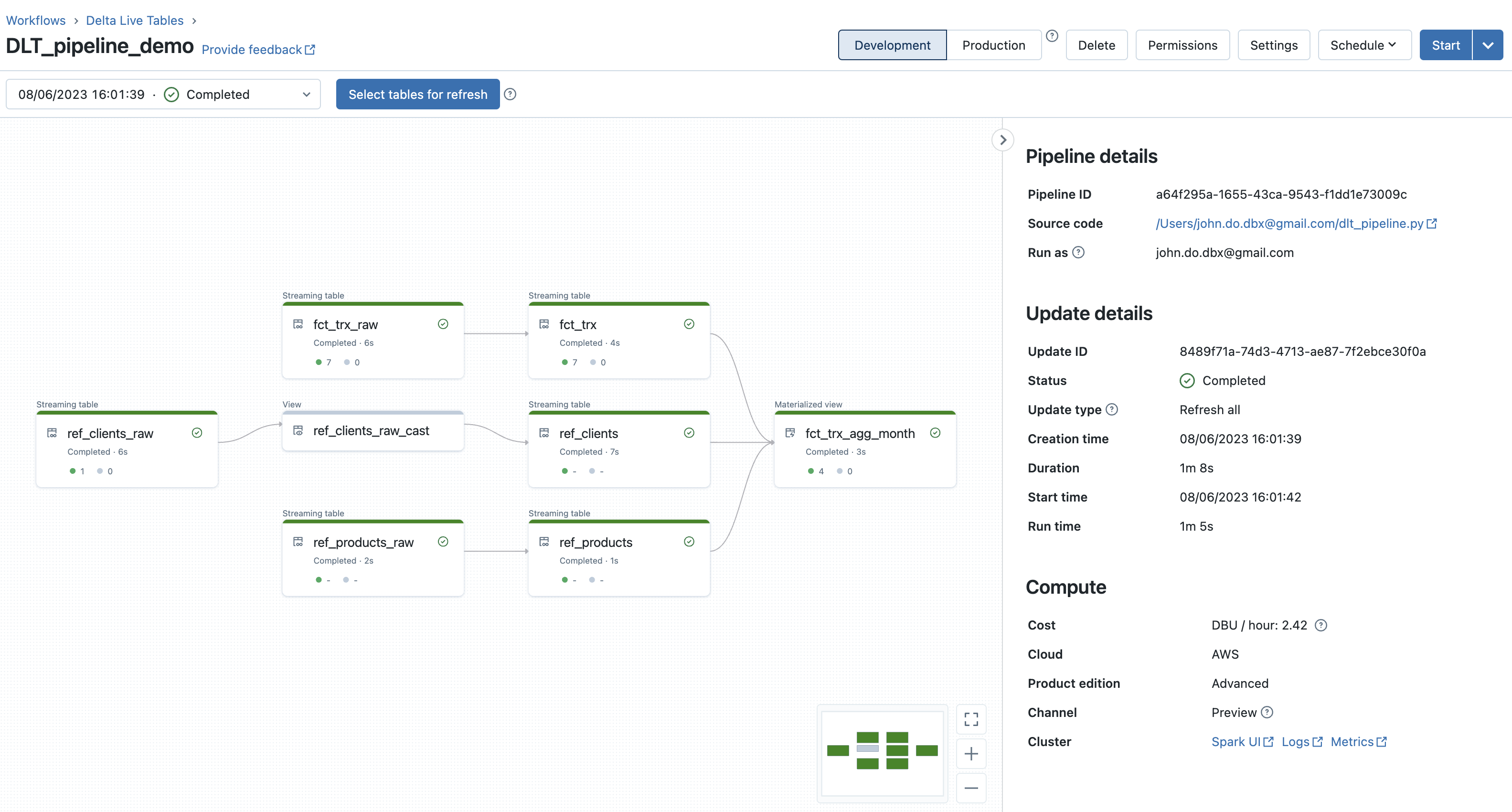
Result after the seoncd execution of the DLT pipeline ::
Detail of the “FCT_TRX” object (with the constraint/expectation on the “quantity” information) :
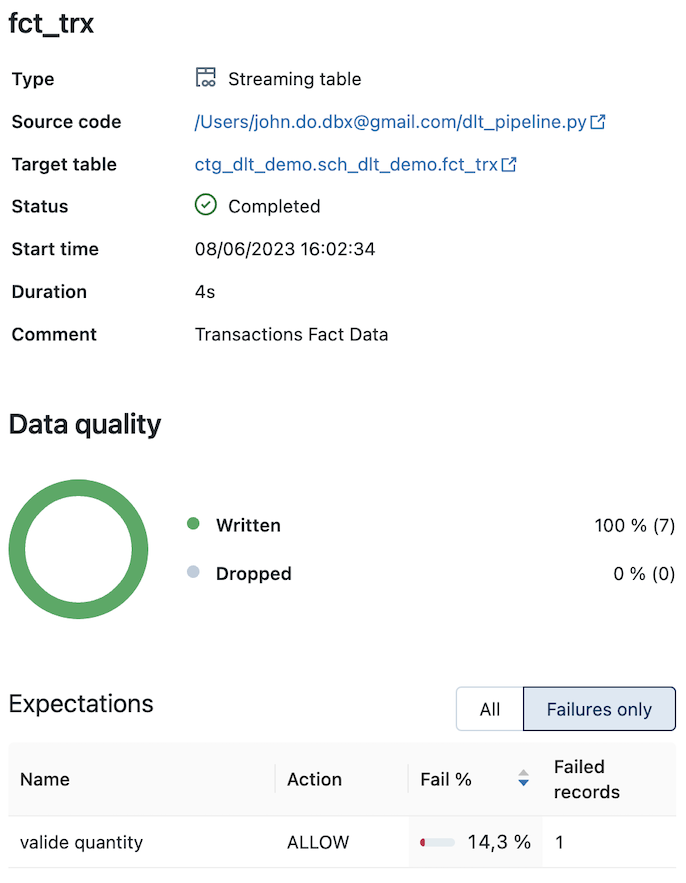
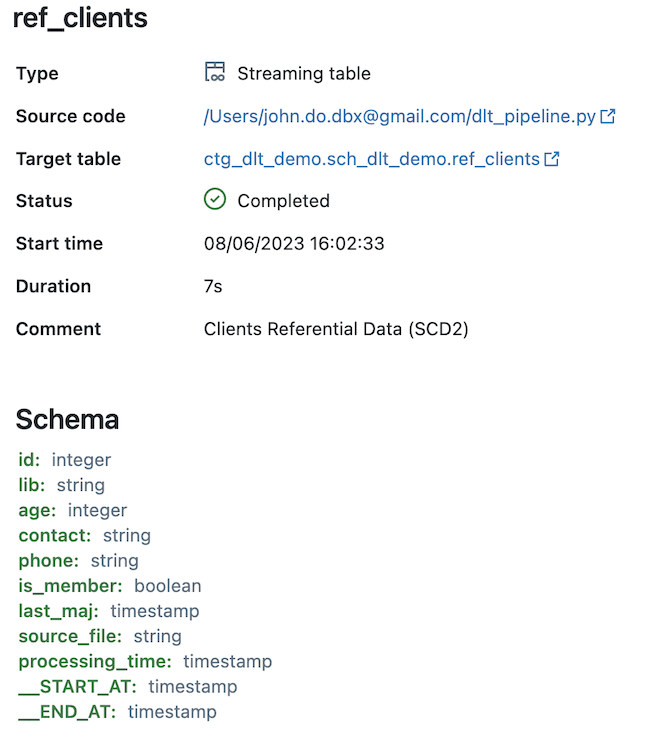
Detail of the “REF_CLIENTS” object (feeded by the SCD type 2 process) :
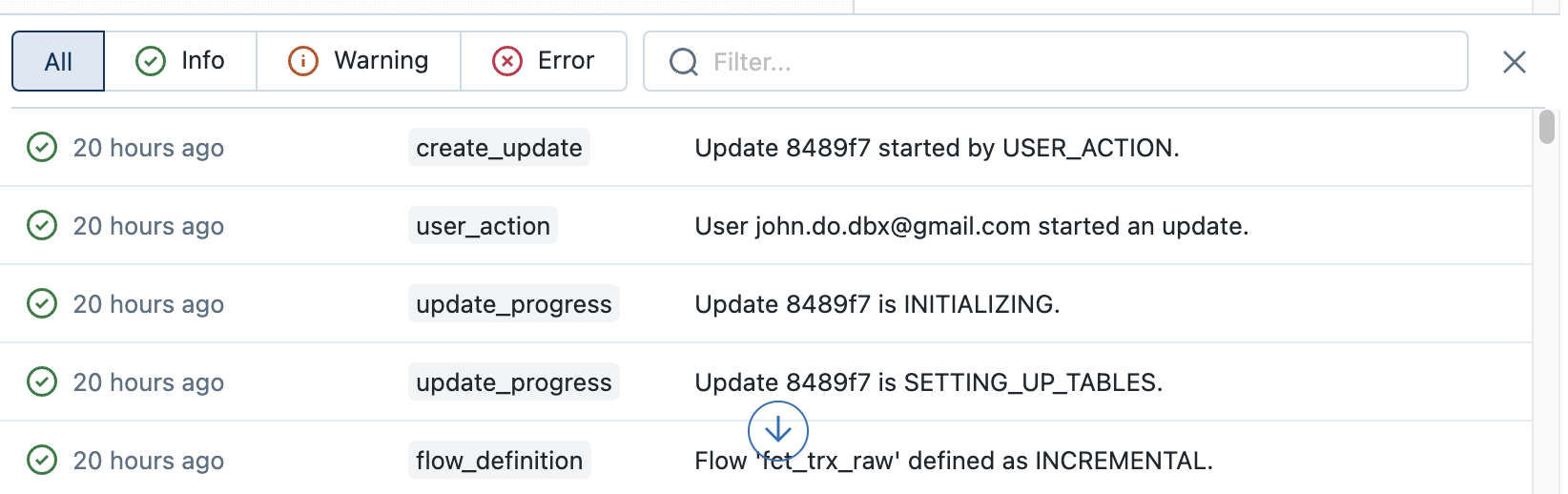
Example of the tab containing the event logs of the second execution of the DLT pipeline :
Oberservation :
- The DLT pipeline graph makes it very easy to visualize the lineage of the data as well as the number of records processed (or deleted) during each step (object)
- When we click on an object, we can have metrics on the object (number of records written and deleted, number of records violating a constraint, schema of the object, date and time of execution, duration, . ..)
- At the bottom of the screen, we have access to all the event logs of the execution of the DLT pipeline and it is possible to filter them on the options “All”, “Info”, “Warning” and " Error" or on the description of the events.
- It is possible to choose the execution you want to view by selecting it from the drop-down list (by execution timestamp and containing the last execution status).
Visualization with Unity Catalog
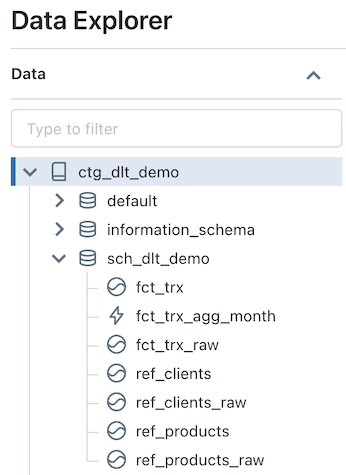
Visualization of the objects in the “sch_dlt_demo” schema in the “ctg_dlt_demo” catalog:
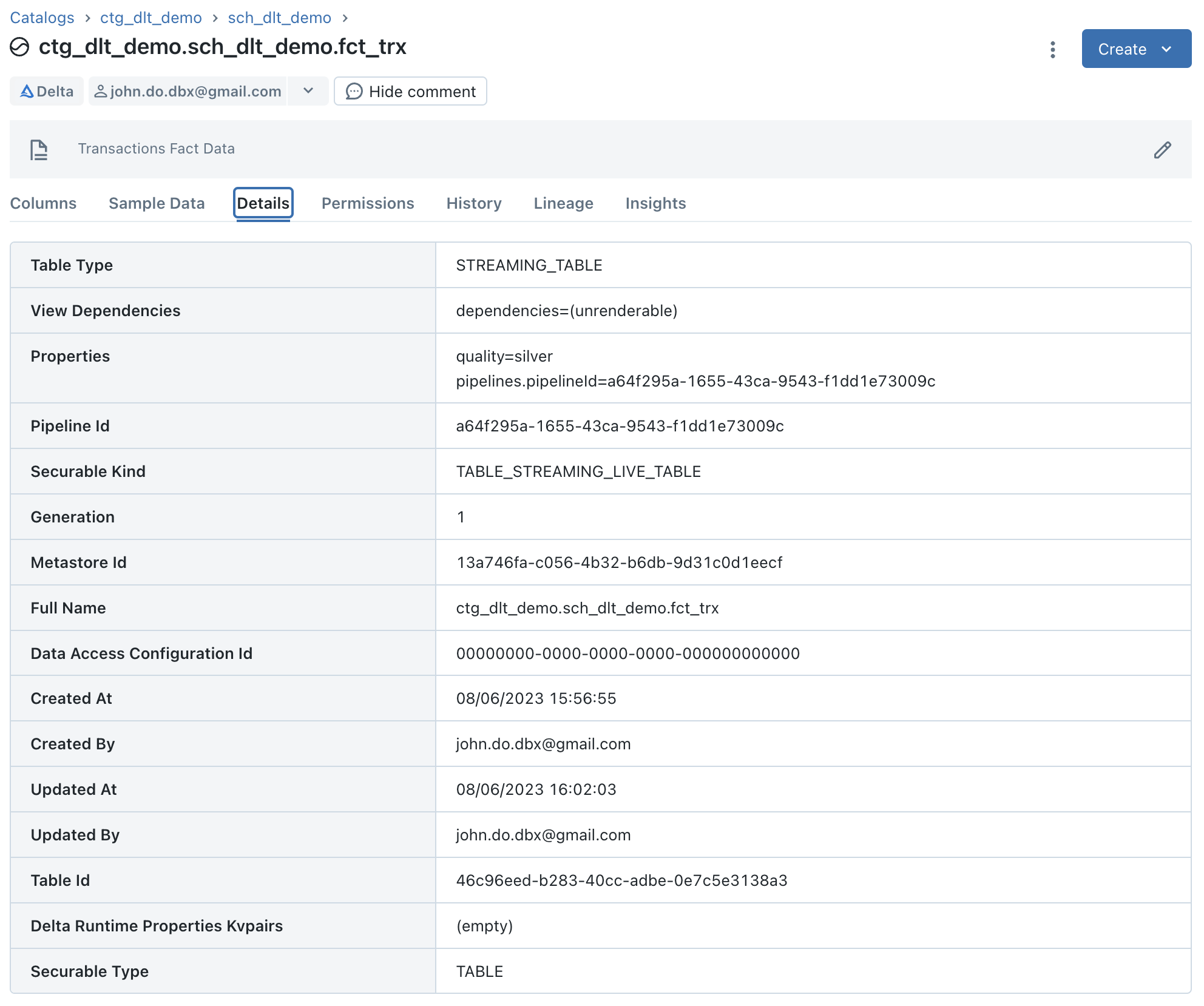
Viewing details for the “FCT_TRX” object which is a “Streaming Table” object :
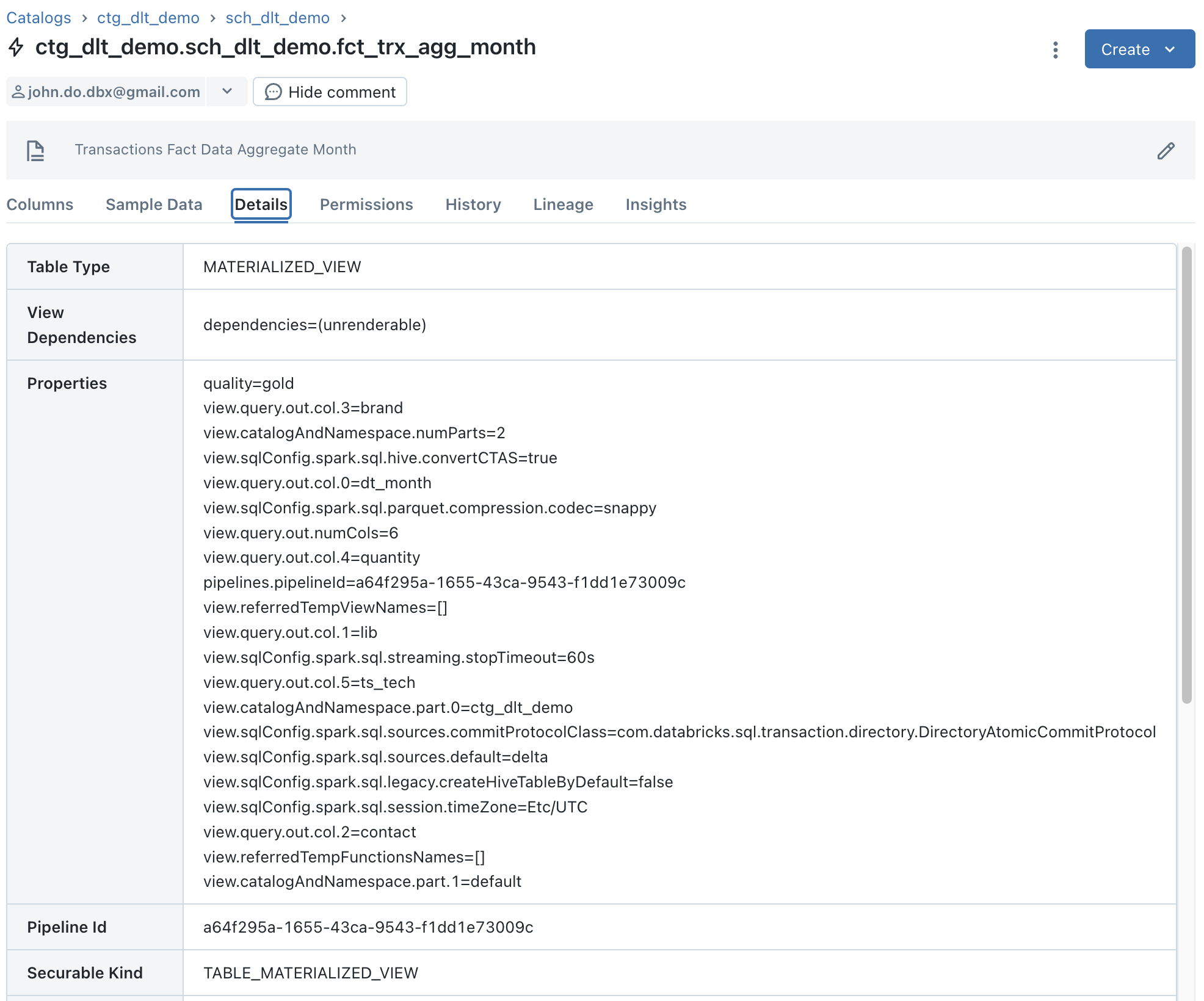
Viewing details for the “FCT_TRX_AGG_MONTH” object which is a “Materialized View” object :
Observation :
- We can see that the “Storage Location” information does not exist because they are not actually Delta tables but they can be seen as logical objects.
Regarding Data Lineage :
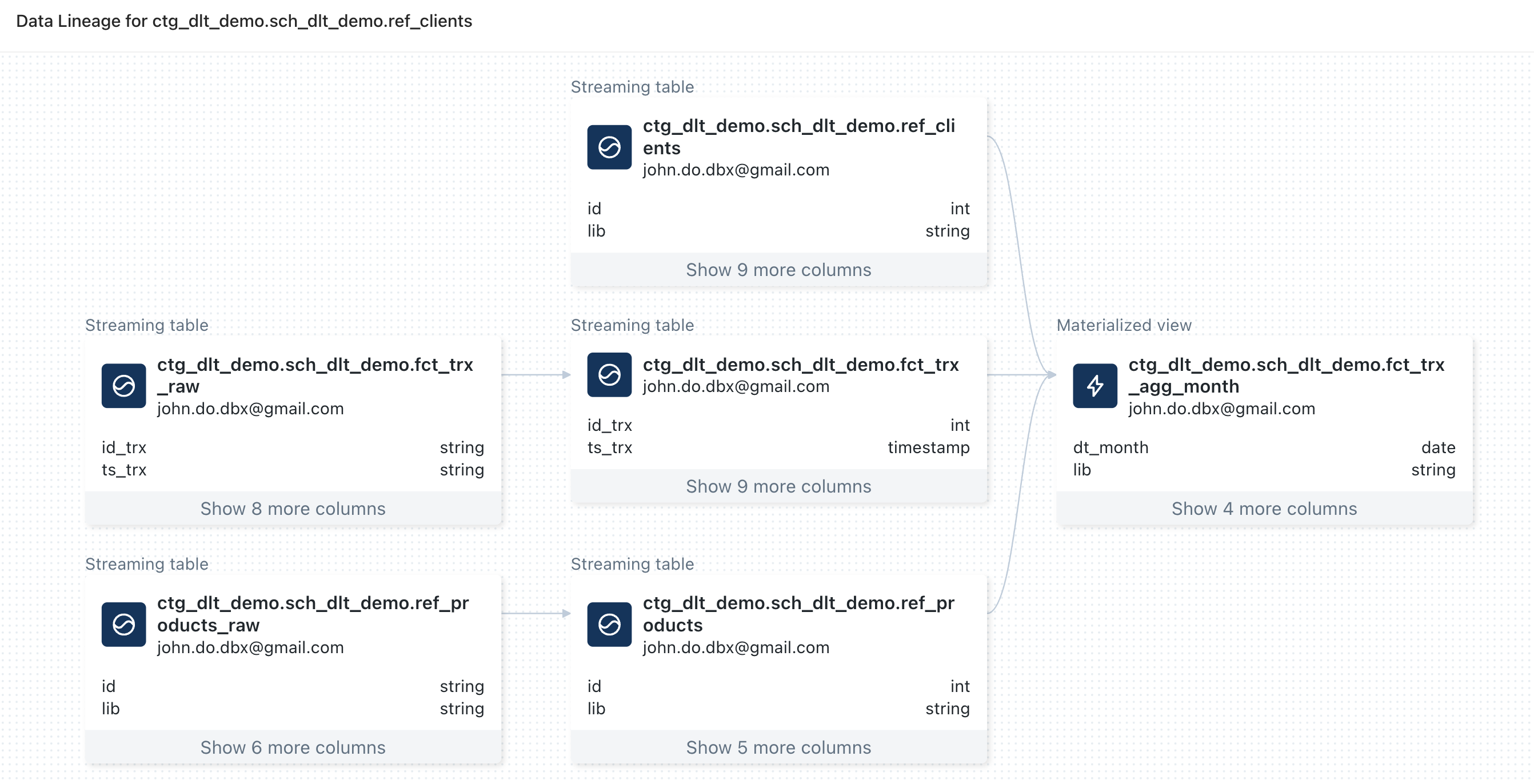
Visualization of the lineage starting from the “REF_CLIENTS” object :
 Observation :
Observation :
- We can observe that there is information for the objects defined in the DLT pipeline except for the data source of the object “REF_CLIENTS” which is named “REF_CLIENTS_RAW”
- We can observe that there is no information about data sources (CSV files)
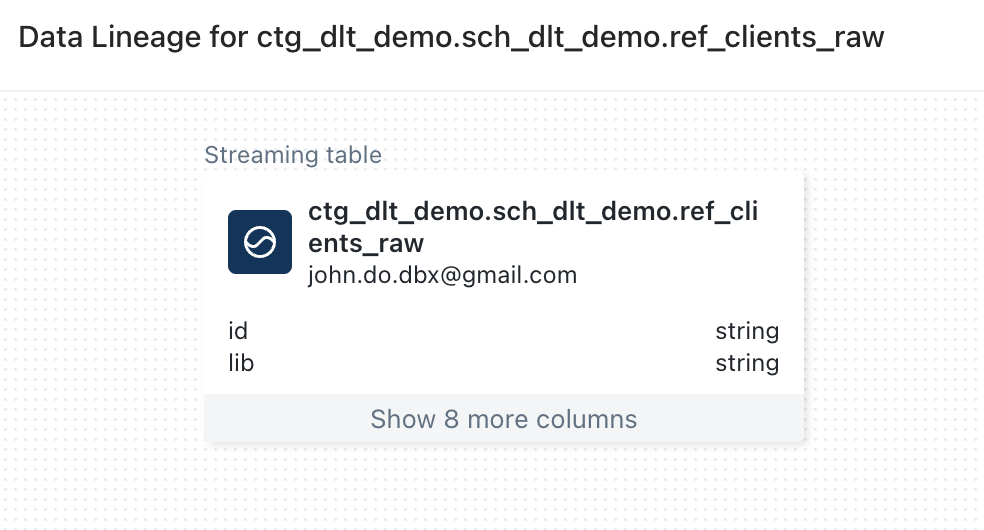
Visualization of the lineage starting from the “REF_CLIENTS_RAW” object :
 Observation :
Observation :
- We can observe that the “REF_CLIENTS_RAW” object has no lineage information while it is the source of the “REF_CLIENTS” object’s in the DLT pipeline
Regarding internal objects : Warning: To be able to view them, you must have the following rights
1GRANT USE_CATALOG ON CATALOG __databricks_internal TO <user or group>;
2GRANT USE_SCHEMA ON SCHEMA __databricks_internal.__dlt_materialization_schema_<pipeline_id> TO <user or group>;
Visualizing the __databricks_internal internal catalog with Data Explorer
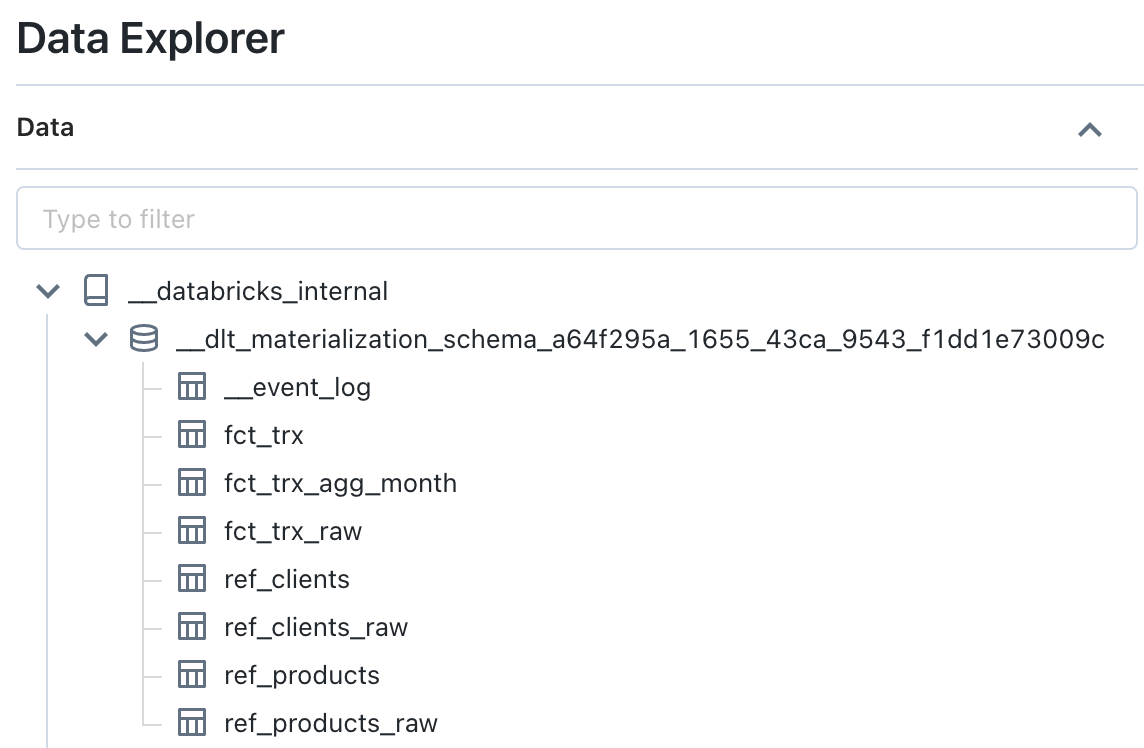
Visualization of details for the “FCT_TRX” internal object (which contains the data of a “Streaming Table” object) :
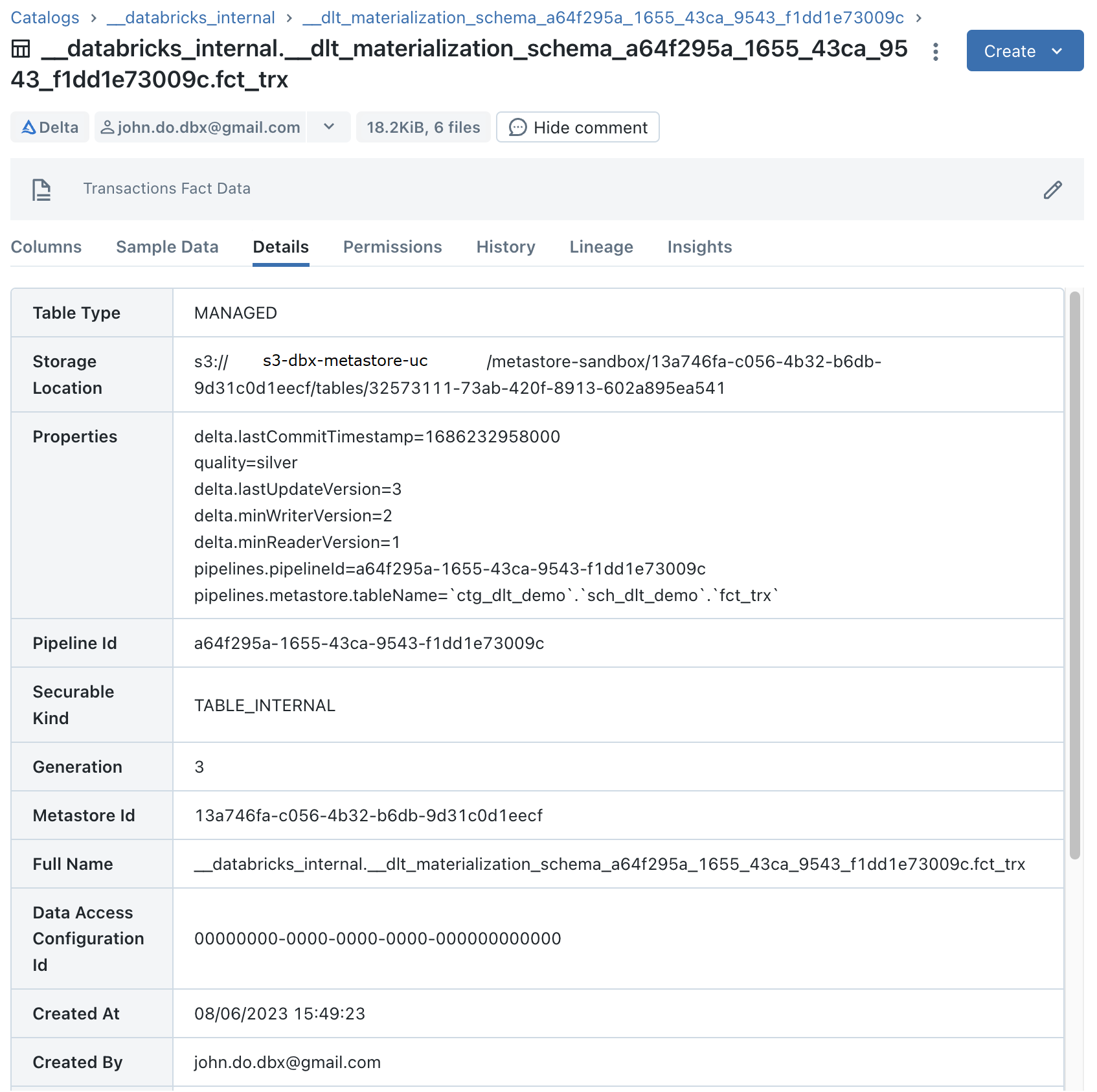
Visualization of details for the “FCT_TRX_AGG_MONTH” internal object (which contains the data of a “Materialized View” object) :
Observation :
- We can observe that these are Delta tables
Monitoring a DLT pipeline
Monitoring a DLT pipeline relies on event logs related to the execution of the DLT pipeline, including audit, data quality, and lineage logs. This enables analysis of executions and status of DLT pipelines.
The __event_log internal object is a Delta table which contains a subdirectory named _dlt_metadata and containing an _autoloader directory with information allowing to manage the loading of data by the system with Auto Loader.
There are four methods of accessing event logs regarding the DLT pipelines execution :
- The 1st method is to use the Databricks Workspace user interface
- Click on the “Workflows” option in the side menu
- Click on the “Delta Live Tables” tab
- Select the desired DLT pipeline
- Select the desired DLT pipeline run (sorted by descending start timestamp)
- All event logs can be found in the tab at the bottom of the interface
- The 2nd method is to use the Databricks REST API
- The 3rd method is to use the
event_log(<pipeline_id)function (table valued function), this is the method recommended by Databricks - The 4th method is to access the Delta table
__event_loglocated in the internal schema linked to the DLT pipeline- This method requires having the “USE” right on the internal schema and on the corresponding internal catalog
1GRANT USE_CATALOG ON CATALOG __databricks_internal TO <user or group>;
2GRANT USE_SCHEMA ON SCHEMA __databricks_internal.__dlt_materialization_schema_<pipeline_id> TO <user or group>;
DLT pipeline event log storage is physically separated for each DLT pipeline and there is no default view that provides an aggregated view of event logs. You will find detail of the event logs schema in the official documentation
The types of existing events are as follows (not exhaustive):
- user_action: Information about user actions (creation of a DLT pipeline, execution of a DLT pipeline, stop of a DLT pipeline)
- create_update: Information about the DLT pipeline execution request (origin of the request)
- update_progress: Information about the execution steps of the DLT pipeline (WAITING_FOR_RESOURCES, INITIALIZING, SETTING_UP_TABLES, RUNNING, COMPLETED, FAILED)
- flow_definition: Information about the definition of objects (Type of update (INCREMENTAL, CHANGE, COMPLETE), object schema, …)
- dataset_definition: Information about the definition of objects (schema, storage, type, …)
- graph_created: Information about the creation of the graph during the execution of the DLT pipeline
- planning_information: Information about the refresh schedule for “Materialized View” objects
- flow_progress: Information about the execution steps of all the elements defined in the DLT pipeline (QUEUED, STARTING, RUNNING, COMPLETED, FAILED)
- cluster_resources: Information about DLT pipeline cluster resource management
- maintenance_progress: Information about the maintenance operations on the data within 24 hours after the last execution of the DLT pipeline
Warning :
- When you delete a DLT pipeline, the event logs will no longer be accessible using the
event_log(<pipeline_id)function, but will still be accessible by directly accessing the Delta table concerned (as long as it is not deleted). - Metrics are not captured for “Streaming Table” objects feeded with the Type 2 Slow Changing Dimension (SCD) process managed by the DLT framework
- Nevertheless, it is possible to have metrics by accessing the history of the internal Delta table directly
- When there are records that do not respect the constraints on an object, we have access to the metrics on the number of records but not the details of the records concerned.
It is very easy to set up event logs based dashboards or exports to centralize information from the Databricks REST API, SQL Warehouse or by adding processing (in a Job) after the execution of each DLT pipeline to retrieve the necessary information.
We will use the 3rd method to give examples of queries to analyze the DLT pipeline.
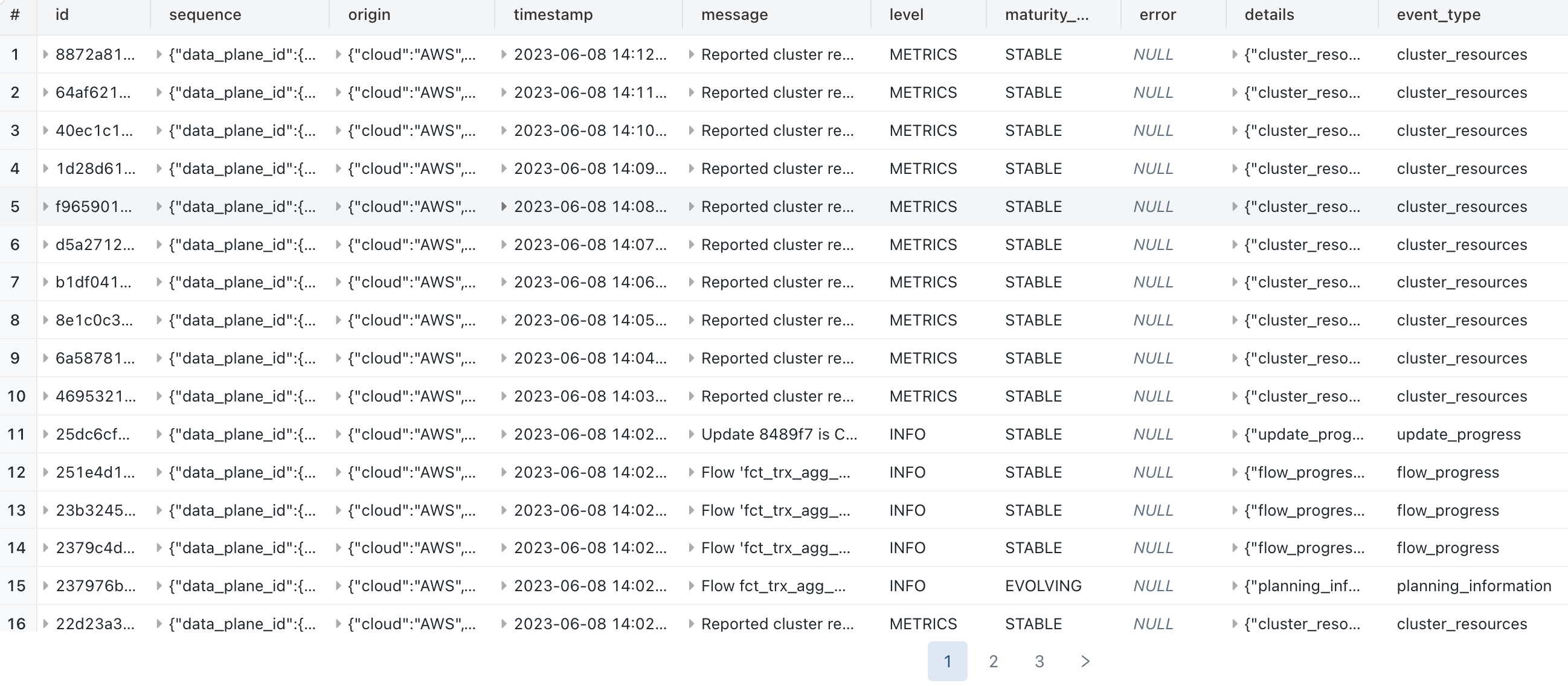
1/ Example query to retrieve all information for the last run of the DLT pipeline :
1with updid (
2 select row_number() over (order by ts_start_pipeline desc) as num_exec_desc
3 ,update_id
4 ,ts_start_pipeline
5 from (
6 select origin.update_id as update_id,min(timestamp) as ts_start_pipeline
7 from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c')
8 where origin.update_id is not null
9 group by origin.update_id
10 )
11)
12select l.*
13from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c') l
14where l.origin.update_id = (select update_id from updid where num_exec_desc = 1)
15order by timestamp desc
Result :
2/ Example of a query to retrieve the number of lines written for each object during the two executions of the DLT pipeline :
1with updid (
2 select row_number() over (order by ts_start_pipeline desc) as num_exec_desc
3 ,update_id
4 ,ts_start_pipeline
5 from (
6 select origin.update_id as update_id,min(timestamp) as ts_start_pipeline
7 from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c')
8 where origin.update_id is not null
9 group by origin.update_id
10 )
11)
12select l.origin.flow_name
13 ,u.ts_start_pipeline
14 ,sum(l.details:['flow_progress']['metrics']['num_output_rows']) as num_output_rows
15 ,sum(l.details:['flow_progress']['metrics']['num_upserted_rows']) as num_upserted_rows
16 ,sum(l.details:['flow_progress']['metrics']['num_deleted_rows']) as num_deleted_rows
17from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c') l
18inner join updid u
19on (l.origin.update_id = u.update_id)
20and event_type = 'flow_progress'
21and details:['flow_progress']['metrics'] is not null
22group by l.origin.flow_name
23 ,u.ts_start_pipeline
24order by l.origin.flow_name
25 ,u.ts_start_pipeline
Comments :
- When the object is a “Streaming Table”, the metrics are captured with the event that has the “RUNNING” status
- Special case for the “Streaming Table” object using the SCD Type 2 process whose metrics are not captured
- When the object is a “Materialized View”, the metrics are captured with the event which has the status “COMPLETED”
- When the object is a “View”, no metrics are captured
Result :
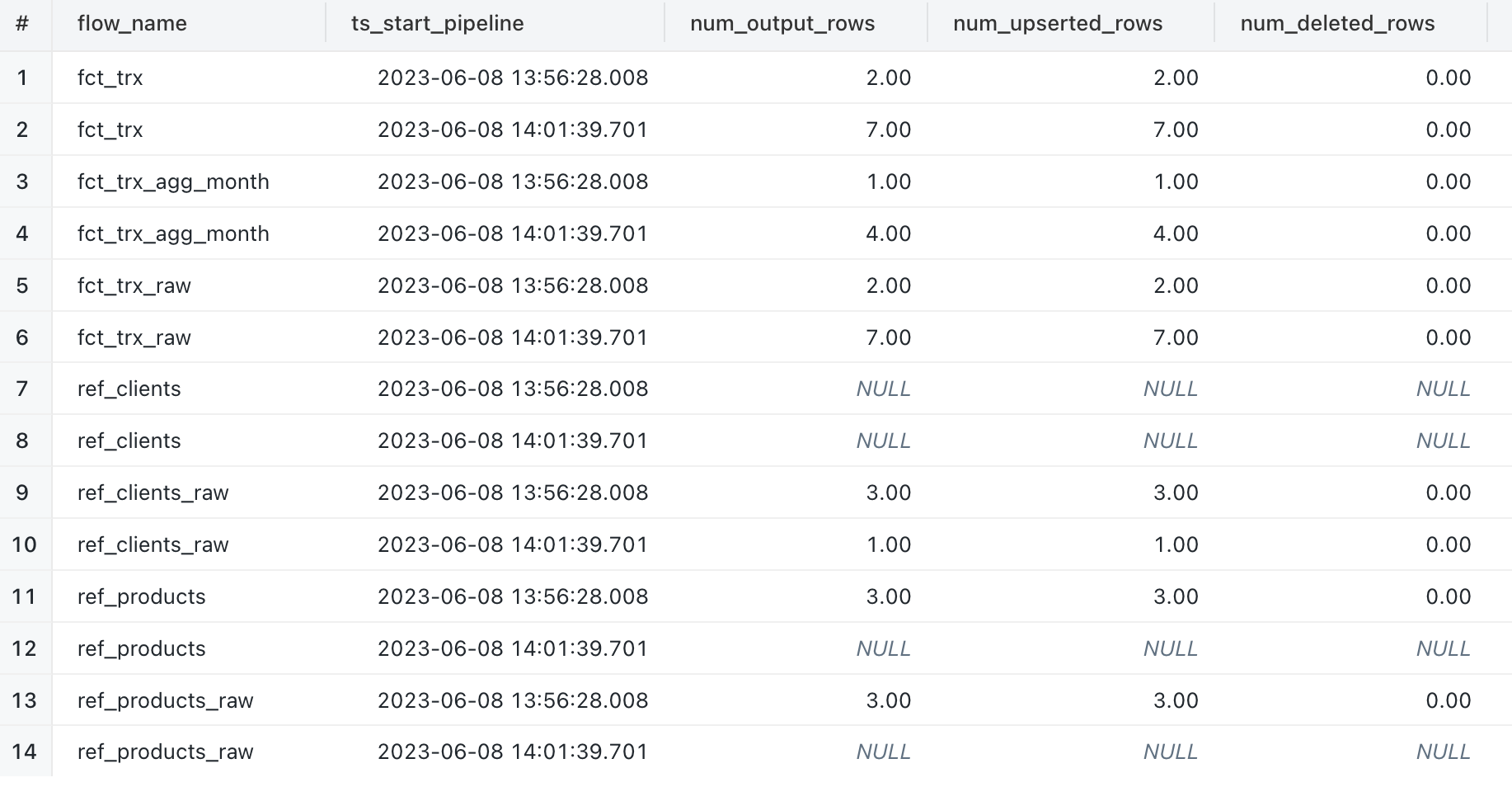
Comments :
- We can observe that the “REF_PRODUCTS” and “REF_PRODUCTS_RAW” objects had no new data on the second run
- We can observe that the “REF_CLIENT” object has no information while the “REF_CLIENT_RAW” source object has retrieved only the new data during each execution of the DLT pipeline
3/ Example query to retrieve the number of records violating the constraints for the “FCT_TRX” object during each execution of the DLT pipeline:
1with updid (
2 select row_number() over (order by ts_start_pipeline desc) as num_exec_desc
3 ,update_id
4 ,ts_start_pipeline
5 from (
6 select origin.update_id as update_id,min(timestamp) as ts_start_pipeline
7 from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c')
8 where origin.update_id is not null
9 group by origin.update_id
10 )
11)
12select flow_name
13 ,metrics.name
14 ,ts_start_pipeline
15 ,sum(metrics.passed_records) as passed_records
16 ,sum(metrics.failed_records) as failed_records
17from (
18 select l.origin.flow_name as flow_name
19 ,u.ts_start_pipeline as ts_start_pipeline
20 ,explode(from_json(l.details:['flow_progress']['data_quality']['expectations'][*], 'array<struct<name string, passed_records int, failed_records int >>')) as metrics
21 from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c') l
22 inner join updid u
23 on (l.origin.update_id = u.update_id)
24 and event_type = 'flow_progress'
25 and origin.flow_name = "fct_trx"
26 and details:['flow_progress']['data_quality'] is not null
27) wrk
28group by flow_name
29 ,metrics.name
30 ,ts_start_pipeline
31order by flow_name
32 ,metrics.name
33 ,ts_start_pipeline
Result :

4/ Example query to retrieve the start and end timestamp of each run of the DLT pipeline :
1with updid (
2 select row_number() over (order by ts_start_pipeline desc) as num_exec_desc
3 ,update_id
4 ,ts_start_pipeline
5 from (
6 select origin.update_id as update_id,min(timestamp) as ts_start_pipeline
7 from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c')
8 where origin.update_id is not null
9 group by origin.update_id
10 )
11)
12select update_id
13,start_time
14,end_time
15,end_time - start_time as duration
16,last_state
17from (
18 select l.origin.update_id as update_id
19 ,min(l.timestamp) over (partition by l.origin.update_id) as start_time
20 ,max(l.timestamp) over (partition by l.origin.update_id) as end_time
21 ,row_number() over (partition by l.origin.update_id order by timestamp desc) as num
22 ,l.details:['update_progress']['state'] as last_state
23 from event_log('a64f295a-1655-43ca-9543-f1dd1e73009c') l
24 inner join updid u
25 on (l.origin.update_id = u.update_id)
26 and event_type = 'update_progress'
27) wrk
28where num = 1
29order by update_id
30,start_time asc
Result :

Clean environment
Delete the DLT pipeline
1dbx-api -X DELETE ${DBX_API_URL}/api/2.0/pipelines/${DBX_DLT_PIPELINE_ID}
Delete the Python script from the Databricks Workspace
1dbx-api -X POST ${DBX_API_URL}/api/2.0/workspace/delete -H 'Content-Type: application/json' -d "{
2 \"path\": \"${DBX_USER_NBK_PATH}/${LOC_SCRIPT_DLT}\",
3 \"recursive\": \"false\"
4}"
Delete CSV fils from Databricks Workspace DBFS storage
1dbx-api -X POST ${DBX_API_URL}/api/2.0/dbfs/delete -H 'Content-Type: application/json' -d "{
2 \"path\": \"${DBX_PATH_DATA}\",
3 \"recursive\": \"true\"
4}"
Delete the “CTG_DLT_DEMO” catalog from the Unity Catalog Metastore :
1-- Delete the Catalog with CASCADE option (to delete all objects)
2DROP CATALOG IF EXISTS CTG_DLT_DEMO CASCADE;
Warning:
- Deleting the DLT pipeline will delete all the objects in the target schema, but will not automatically delete the Delta tables (defined in the DLT pipeline) in the internal schema.
- In the event of an issue, Delta tables can be deleted from the internal schema using the following commands:
1# Get the list of tables (with full_name)
2export list_tables=(`dbx-api -X GET ${DBX_API_URL}/api/2.1/unity-catalog/tables -H 'Content-Type: application/json' -d "{
3 \"catalog_name\": \"__databricks_internal\",
4 \"schema_name\": \"__dlt_materialization_schema_$(echo ${DBX_DLT_PIPELINE_ID} | sed 's/-/_/g')\"
5}" | jq -r '.tables[]|.full_name'`)
6
7# Delete tables
8for table in ${list_tables}; do
9 dbx-api -X DELETE ${DBX_API_URL}/api/2.1/unity-catalog/tables/${table}
10done
Conclusion
The DLT framework makes it possible to be very efficient in the creation and execution of an ETL pipeline and to be able to easily add data quality management (subject to use the Advanced edition).
Being able to view the graph and metrics associated with objects of a specific DLT pipeline run is extremely convenient for quick analysis. In addition, access to event logs (stored in a Delta table) allows us to retrieve a lot of information and to be able to perform analyzes and dashboards very simply.
During POC or specific ETL ingestion processing, it is very practical to be able to rely on the DLT framework but in the context of a project requiring the management of numerous objects and schemas, we find ourselves much too limited to be able to use the DLT framework.
As it stands (public preview), the limitations are too important for us to recommend using the DLT framework with Unity Catalog for major projects:
- Lineage is incomplete if the object is not managed in the DLT pipeline, or if “View” objects are used.
- Only one target schema can be used for all elements of a DLT pipeline
- Some operations (SCD Type 1 and 2 management) have no metrics captured in event logs
- No aggregation of event logs for all pipelines by default if you wish to perform analyses on all DLT pipelines
In my humble opinion, it’s still a bit early to use the DLT framework relying on the Unity Catalog solution to manage all the ETL processes for managing a company’s data, but i can’t wait to see future improvements made by Databricks to make it a central and powerful tool for managing ETL processes while taking advantage of all the features of the Unity Catalog solution (Data Lineage, Delta Sharing, …).