
Azure : Microsoft Fabric Preview
Following the announcement of the preview release of Microsoft Fabric, I used the trial version to take a quick tour.
Note : Information is based on the state of the solution at the beginning of July 2023 in preview mode.
What is Microsoft Fabric
Overview
Microsoft Fabric is a solution proposed by Microsoft to bring together a coherent set of services based primarily on Azure services, covering all data-related analytical needs.
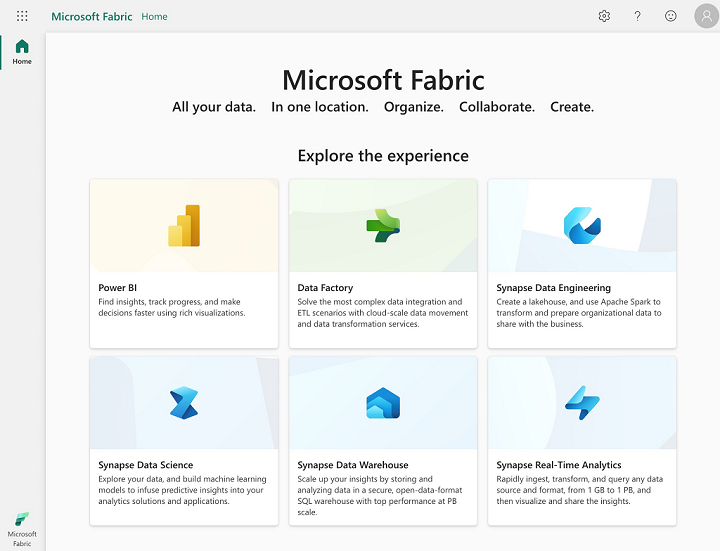
The foundations of Microsoft Fabric are based primarily on the following three elements :
- OneLake
- A package of SaaS (Software as a Service)
- Capacity Fabric
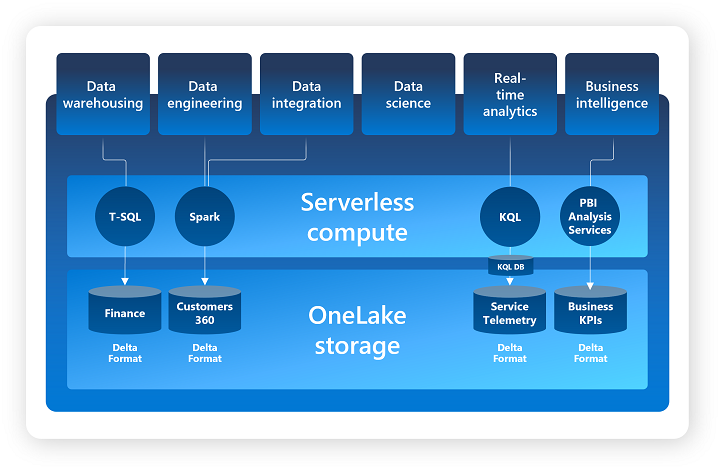
OneLake is a unified Data Lake for an entire Tenant (organization) based on Azure Data Lake Gen2, enabling centralized data governance and management.
On the SaaS side, we have the following elements (which will be enhanced in the future) :
- Data integration : Data Factory
- Dataflows (Gen2) and pipelines management
- Data engineering : Synapse Data Engineering
- Lakehouse, Notebooks and Apache Spark Job Definition management
- Data warehousing : Synapse Data Warehouse
- Warehouses management
- Data science : Synapse Data Science
- Models, Experiments and Notebooks management
- Real-time analytics : Synapse Real Time Analytics
- KQL Database, KQL Queryset and Eventstream management
- Business intelligence : Power BI
- Reports, Dashboards, Dataflow, Datamart and Dataset management
Note: we can see that Microsoft Fabric relies mainly on Azure Synapse and Power BI services.
Regarding the concept of Capacity Fabric :
- As all services are managed and serverless, the computing power/ressource available is defined by a Capacity Fabric.
- A Capacity Fabric is specific to a Tenant (organization) and there can be several per organization.
- Each Capacity Fabric represents a distinct set of resources allocated to Microsoft Fabric, and more specifically to the workspaces concerned.
- The configuration size for a Capacity Fabric will determine the computing power available, and consequently the managed services that can be used. You will find the list of configurations in the official documentation.
Hierarchy of elements:
- Level n°1 : OneLake is unique for the entire Tenant
- Level n°2 : Workspaces (with logical grouping by domain)
- Level n°3 : Ressources (Lakehouse, Warehouse, KQL Database, SQL Endpoint, …)
- Level n°4 : Objects (Files, Tables, Dashboard, Notebooks, …)
A workspace is assigned to a Capacity Fabric and all managed services use the resources of this Capacity Fabric to run.
Centralized rights management (by roles/users) makes it possible to manage access by workspace and to manage rights to elements of the various services in a simplified way.
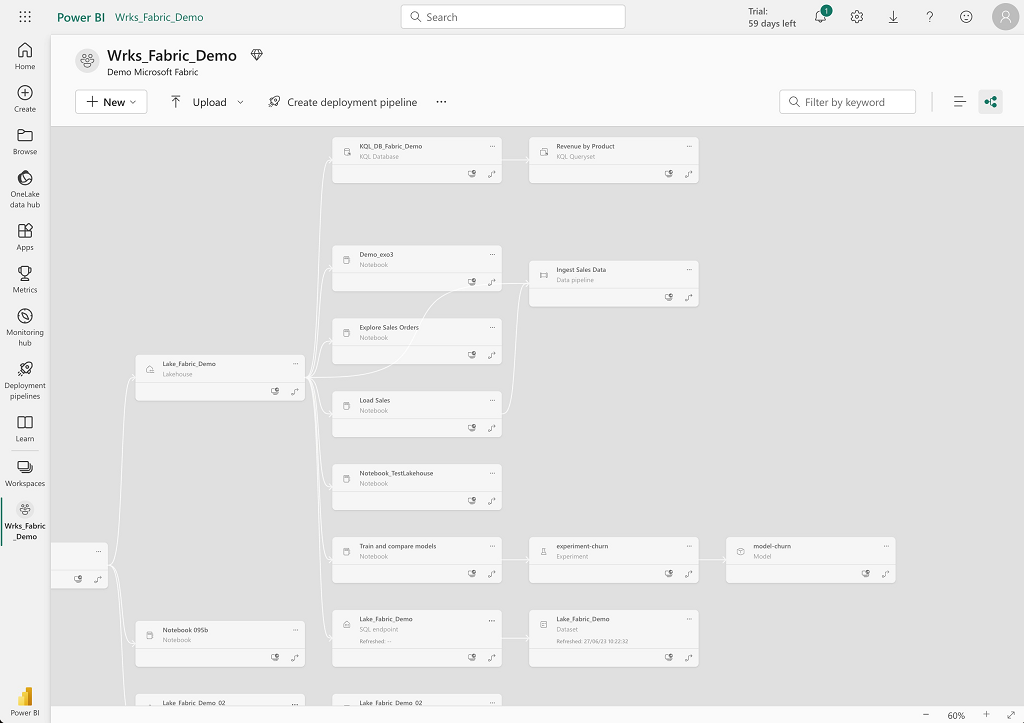
By default, Microsoft Fabric offers a visualization of the lineage of objects at workspace level.
About the Lakehouse part
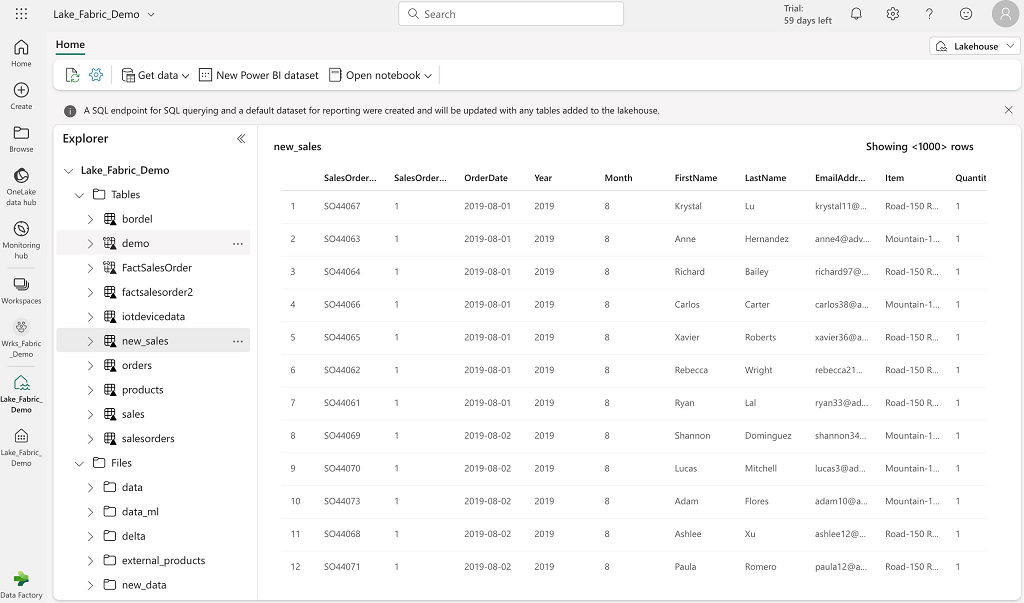
A Lakehouse will store data in the form of files or tables, using OneLake’s default storage space.
Example of the Lakehouse interface :
Two engines are used:
- Apache Spark to transform and manipulate data
- A SQL engine for reading data using T-SQL syntax
When creating a Lakehouse, Microsoft Fabric creates two additional elements by default (with the same name as the Lakehouse):
- SQL Endpoint (SQL Engine)
- Default Dataset (Data representation)
SQL Endpoint allows to access data from tables defined at the Lakehouse level in read-only mode with the T-SQL syntax. It also provides read-only access to tables in other Lakehouses and Warehouses in the same workspace.
The following actions can be performed with a SQL Endpoint:
- Query Lakehouse and Warehouse tables
- Create views and procedures to encapsulate T-SQL queries
- Manage object rights
The default dataset allows PowerBI to access Lakehouse table data. PowerBI reports can be created directly from Lakehouse data (Tables directory only) using the default dataset, or by creating a new dataset and defining an associated data model (object link).
The Lakehouse is composed of two root directories:
- The Tables directory represents data managed by the Lakehouse (Delta format whose storage and metadata are managed directly by the Lakehouse)
- The Files directory represents data not managed by Lakehouse (multiple user-managed data formats).
There are several ways to work with data in the Lakehouse:
- Upload: Download local files or directories to the Lakehouse (in the Files directory) and load data into the Tables directory.
- Dataflows (Gen2) : Import and transform data from many sources and load them directly into Lakehouse tables
- Data Factory pipelines : Copy data and orchestrate data transformation and loading activities in the Tables or Files directories of the Lakehouse
- Notebooks : Working interactively with data with Apache Spark (Scala, Java, Python, R …)
- Shortcuts : Connect to external storage (OneLake, Azure Data Lake Gen2, AWS S3)
- There are two types of Shortcuts :
- In the Files directory, this allows you to link to an external storage space so that you can work directly with the data in a secure manner.
- In the Tables directory, this allows you to synchronize a table with a table from another Lakehouse.
- There are two types of Shortcuts :
Comments :
- If you create several Lakehouses in the same workspace, you will have several SQL Endpoints but they will all have the same connection string.
- Deleting a Lakehouse automatically deletes the associated default dataset and SQL Endpoint.
Regarding the format of data that can be used in the Lakehouse :
- For the Files directory: PARQUET, CSV, AVRO, JSON and all formats compatible with Apache Hive
- For the Tables directory: the default format is Delta
In terms of storage, data are stored in the following spaces by default :
- Path with tables name :
<workspace name>@onelake.dfs.fabric.microsoft.com/<lakehouse name>.Lakehouse/Tables/* - Path with files name :
<workspace name>@onelake.dfs.fabric.microsoft.com/<lakehouse name>.Lakehouse/Files/* - Path with unique identifier (tables) :
<workspace id>@onelake.dfs.fabric.microsoft.com/<lakehouse id>/Tables/*
About the Warehouse part
This service is based on Synapse Warehouse Serverless, which uses T-SQL syntax to provide all database operations (insert, update, delete, select, grant, …) on the various objects managed.
Example of the Warehouse interface :
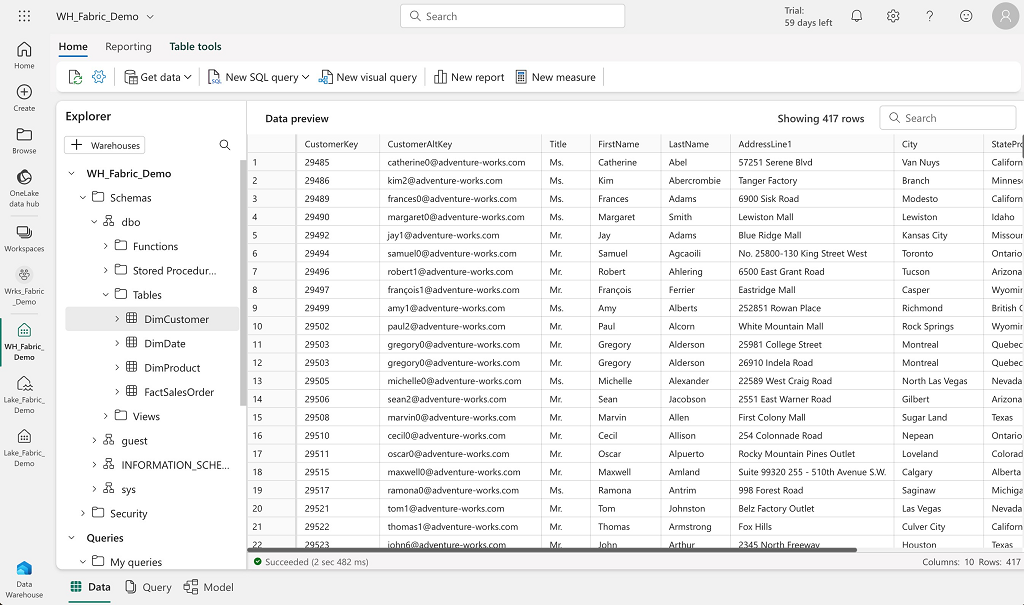
Data storage uses the OneLake storage and the Delta format (which should be the default format). Note: in the preview version, when you create a table without specifying the storage format, you end up with Hive’s default format (which is not Delta format).
This service makes it possible to implement a relational modeling layer on top of data storage in the Lakehouse, and to benefit from all the features of a Warehouse (ACID ownership, concurrency, rights management, schema organization, relational model…). Data can be easily explored using T-SQL queries or reporting tools such as PowerBI. The Synapse Warehouse interface also supports T-SQL queries management (create, save, modify, ….).
Creating a Warehouse in a workspace generates the following elements :
- Creation of default schemas: dbo, guest, INFORMATION_SCHEMA and sys
- Creation of a default dataset with the same name as the Warehouse for data access with PowerBI
Comments :
- From a Warehouse, you can access Lakehouse tables as if they were simply a different database whose objects are stored in a schema named dbo, but in read-only mode. It is not possible to perform DML queries on Lakehouse objects from a Warehouse.
- Lakehouse data must be copied (for example, using the Shortcut) to the Warehouse in order to be modified.
- A Shortcut will have the same functionality for a Warehouse table as for a Lakehouse table
In terms of storage, data is stored in the following space by default :
- Path with abfss format :
abfss://<workspace id>@onelake.dfs.fabric.microsoft.com/<warehouse id>/Tables/<schema name>/<table name> - Path with https format :
https://onelake.dfs.fabric.microsoft.com/<workspace id>/<warehouse id>/Tables/<schema name>/<table name>
Information on the difference between a SQL Endpoint and a Warehouse :
- A SQL Endpoint is used only to perform select queries on Lakehouse or Warehouse data.
- A Warehouse is used to have the full functionality of a serverless database (ACID transactions, DML operations, …). More information can be found in the official documentation.
About the KQL Database part
Synapse Real-Time Analytics is a managed and serverless service optimized for real-time data storage and analysis. This service relies on a KQL database based on Data Explorer Database and uses the Kusto Query (KQL) language, enabling only the reading of data to return a result.
Example of the KQL Database interface :
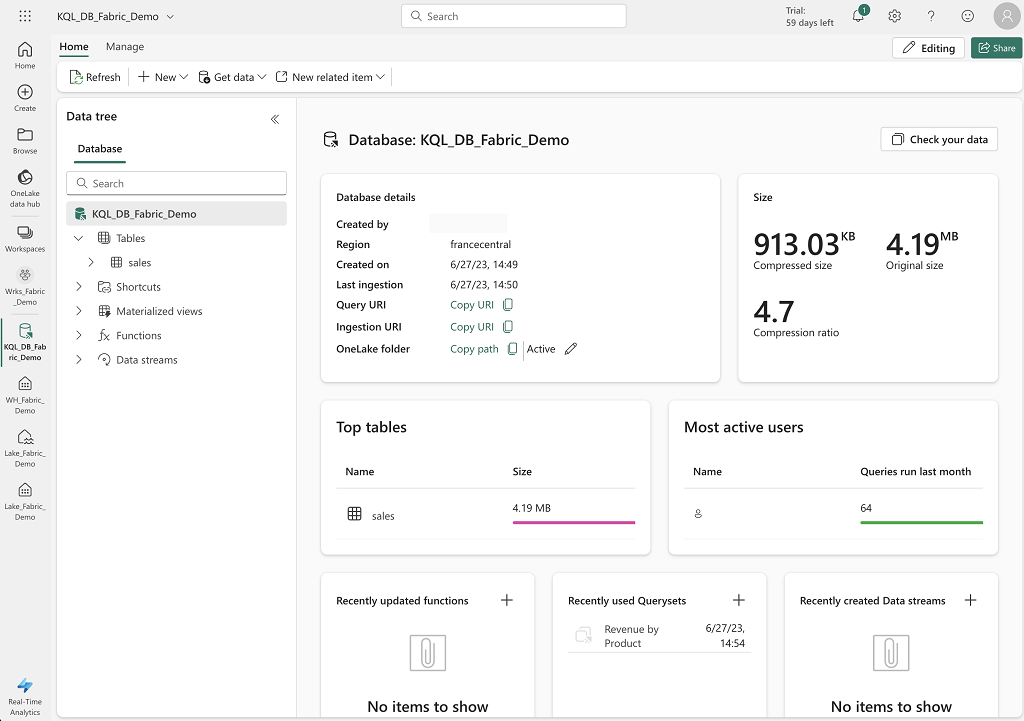
The service comprises the following elements:
- A Kusto database (KQL Database) for managing collections of objects such as tables, functions, materialized views and shortcuts.
- Data is read and manipulated using KQL Queryset, which can only be used to access and apply transformations to data, but not to modify table contents.
- The Eventstream functionality makes it easy to integrate data from sources such as Event Hubs.
KQL Database objects :
- A table stores data in tabular (columns and rows) and typed form.
- A function is used to define an encapsulated query that can be used in a KQL query and can have a list of parameters as input.
- A materialized view is used to pre-calculate the result of an encapsulated query to optimize data access times.
- A datastream is a set of KQL eventstreams connected to the KQL Database.
At the storage level :
- Path with https format :
https://francecentral-api.onelake.fabric.microsoft.com/<workspace id>/<KQL database id>/tables/<table name>
Additional information on KQL Database :
- By default, KQL Database stores data in a columnar format, so the engine only needs to access the columns concerned by queries, rather than scanning all the data in an object.
- KQL database is optimized for data that is only read, rarely deleted and never updated
- KQL database is designed to accelerate data ingestion by not applying any of the constraints found on relational databases (PK, FK, Check, Uniqueness, …).
- KQL database manages Shortcuts as external tables.
Note: KQL Database data cannot be read from SQL Endpoint or Warehouse engine.
You can find out more about the comparison between Synapse Real-Time Analytics and Azure Data Explorer in the official documentation.
About the PowerBI part
This is the service that is most prominently featured in the Microsoft Fabric solution.
All the resources and data managed by Microsoft Fabric (and stored in OneLake) can be accessed by PowerBI to quickly add value and set up the reports and analyses you need.
The key element for using PowerBI is the dataset. By default, when creating a Lakehouse or Warehouse, Microsoft Fabric automatically creates a default dataset, but it is possible to create your own datasets with the desired modeling to be able to use the data with PowerBI.
Regarding the concept of Dataset :
- A dataset is a semantic layer with metrics representing a set of objects stored in the various services and used to create reports and analyses.
- Datasets are automatically synchronized with the state of the data in the Lakehouse or Warehouse, so there’s no specific management or refreshing to do.
- New objects in a Lakehouse or Warehouse are automatically added to the corresponding default datasets
It’s very easy to access all objects via datasets on all Microsoft Fabric services (Lakehouse, Warehouse, KQL database) with PowerBI, and to share the various elements created with other users.
I wasn’t able to test the use of AI with Copilot for PowerBI, which is a feature put forward by Microsoft to facilitate the creation of reports and, in general, the analysis of data by people who aren’t PowerBI experts.
About the Data Science part
The Synapse Data Science service manages all the elements (Notebooks, Models, Experiments) based on the MLflow framework to work on all Machine Learning needs.
All these elements use MLflow, an open source framework for tracking and managing experiments.
About notebooks :
- They enable you to work interactively on data with Apache Spark (Python, Scala, SQL, R).
- They are automatically attached to an Apache Spark cluster
- They enable you to read Lakehouse data using Apache Spark or Pandas dataframes.
About experiments:
- An experiment consists of one or more executions of a notebook task.
- Experiments can be created from the user interface or directly with the MLflow framework.
About models :
- the MLflow framework enables models to be tracked and managed within Microsoft Fabric.
- From an experiment, it is possible to save all elements in the form of a new model, with all associated metadata.
Comments
Warning: to activate Microsoft Fabric (preview), you must be a member of an Azure Active Directory and have the Power BI Administrator role.
The PowerBI user experience is the foundation of the Microsoft Fabric user experience.
At workspace level:
- Use of Azure DevOps only to manage sources (no github or gitlab offered) at workspace level
- Lack of a hierarchy or directory system to organize the various elements within a workspace (to improve comprehension and readability).
- We need to rely on strict standardization of object naming to be able to filter and sort them efficiently.
- There is a messy effect when you start to have a certain number of elements in a workspace, as can be seen on the screens below
Visualization of OneLake elements :
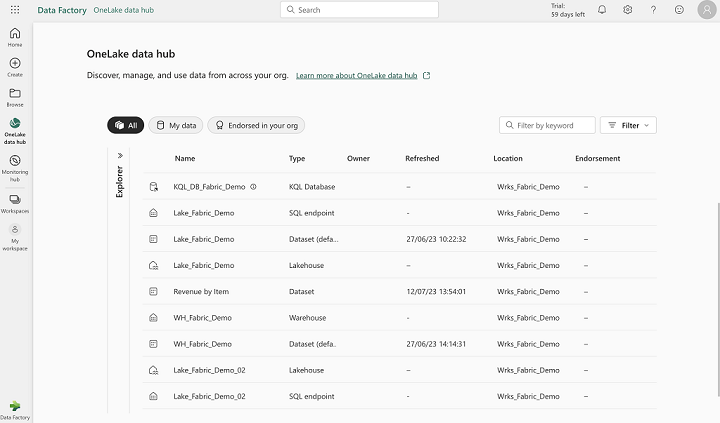 Note: This interface allows you to see the resources created (Lakehouse, Warehouse, KQL Database, SQL Endpoint, Dataset) but not directly the objects (files, tables, notebooks).
Note: This interface allows you to see the resources created (Lakehouse, Warehouse, KQL Database, SQL Endpoint, Dataset) but not directly the objects (files, tables, notebooks).
Visualization of workspace elements :
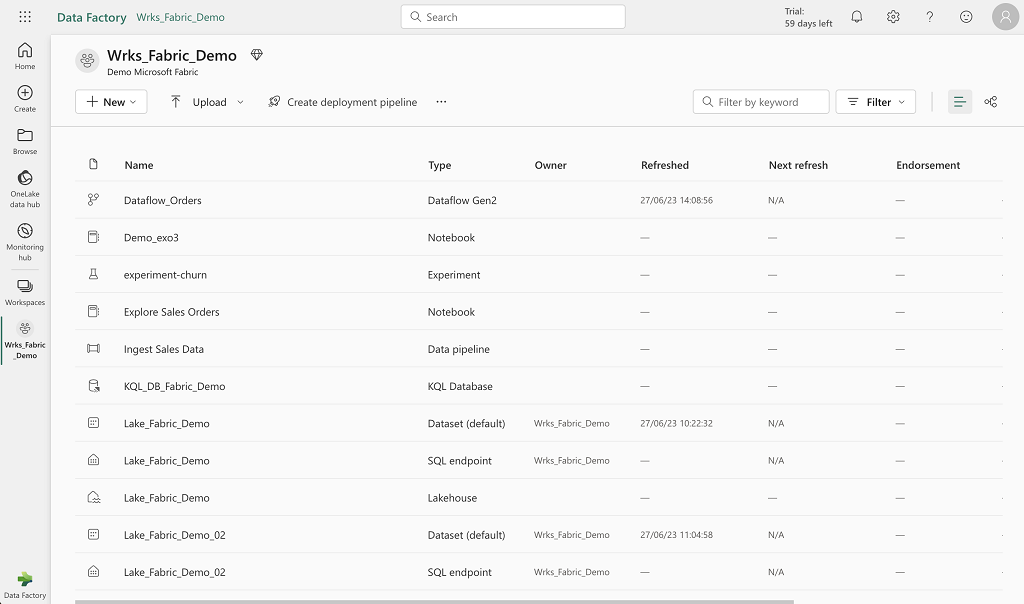 Note: This interface shows all workspace elements (resources and objects).
Note: This interface shows all workspace elements (resources and objects).
To help you navigate, you can filter by name or type of item :
Notebook management is similar to Databricks without automatic versioning. Using the explorer (on the left of the interface), it’s very easy to generate a minimal syntax for loading data (Tables or Files) with Apache Spark (automatic creation of a cell with minimal code).
Some limitations when configuring an Apache Spark job:
- Use of a python script only
- Possibility of downloading a local file or retrieving a file from ADLS Gen2 storage only
- Ability to add a command line
- Ability to add a reference Lakehouse to use relative paths (Files/…)
- Limited job cluster configuration:
- Choice of scheduling
- Choice of Apache runtime specific to Microsoft Fabric (see official documentation)
- No choice regarding worker configuration
- Retry configuration in case of error
Data sharing:
- Lakehouse data does not appear to be shared with the Warehouse by default, unlike the SQL Endpoint, which has direct access to Lakehouse tables in the default dbo schema (same default schema as the Warehouse).
- From a SQL Endpoint, you can add or remove the desired Warehouse and Lakehouse from the same workspace (in order to view them in the explorer)
- Definition of foreign keys between different objects in the Model tab for easier use of Visual Query (and for PowerBI)
- Very inefficient interface when making modifications in the Model tab
- As soon as you click on a column to make it invisible, you have to wait 1 to 2 seconds for all the objects in the interface to refresh, so when you want to perform this action several times, it’s extremely slow and unpleasant.
- When creating a report :
- In the Data panel, all objects (tables and views) are displayed, even those not belonging to the defined Model.
In a medallion architecture logic, we end up with two possibilities:
- Use of a single Lakehouse for all zones
- The Bronze and Silver Zones are located in two different sub-directories in the Files directory of the Lakehouse.
- The Gold Zone is located in the Lakehouse tables (no schema operation).
- This will make only the data in the Gold zone accessible to the greatest number of usages, through the use of a SQL Endpoint or a Warehouse.
- Use of one Lakehouse per zone
- Allows you to manage everything at the tables level in each zone (per Lakehouse), and take advantage of all the functionalities available in all zones.
- Additional cost in terms of resources and rights management
For data governance, it is possible to use Microsoft Purview with Microsoft Fabric and set up data lineage capture.
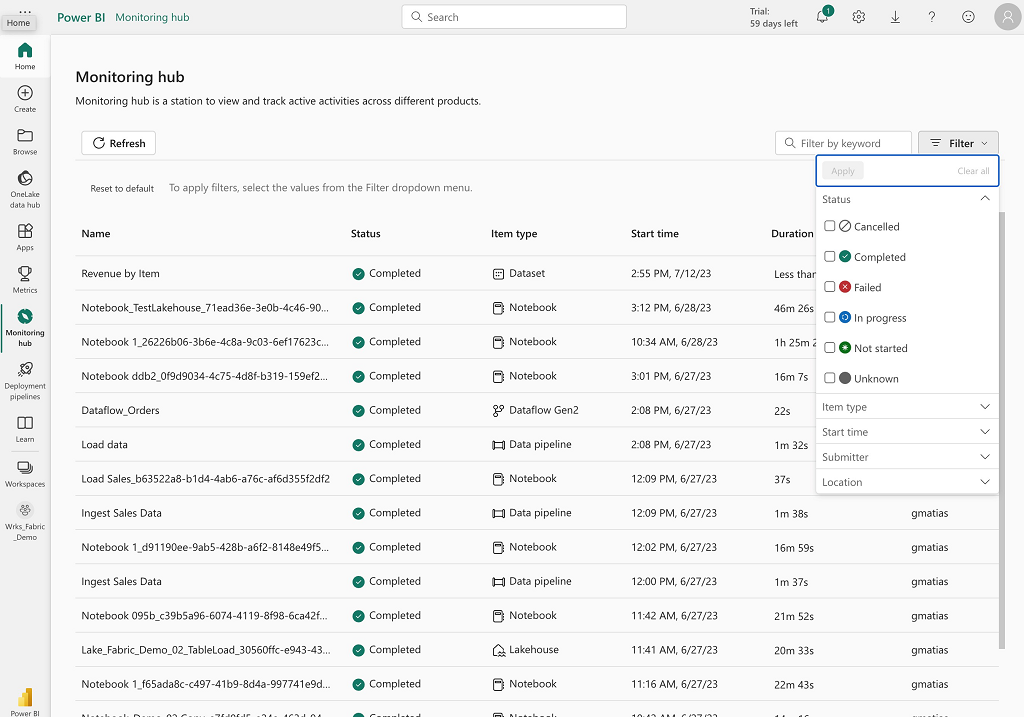
There’s a Monitoring section to track the execution of processes/activities at the tenant level, but not the execution of resources/services directly.
Conclusion
Clearly, this is a coherent offering that enables data to be used in a multiplicity of ways, while limiting the duplication of data on different storage spaces.
Centralized data management facilitates data governance and sharing.
There’s a real desire to push PowerBI as the single solution for data analysis.
This is a very interesting direction in data centralization, to limit the silo effect and facilitate data sharing and centralized governance (in a Data Mesh approach for example).
An important aspect of the development is the no-code (or low-code) principle, which enables to work on data without writing code (or minimal one), mainly using Synapse services. This is a good idea if you want users who are not Data Engineers to be able to manage/use the data for experimentation and demonstration purposes, but when you want to industrialize data management and processing efficiently, this becomes a constraint that can be very costly in terms of time and energy.
Add to this the fact that you can’t manage resource configuration, which is based directly on a Capacity Fabric, and you end up with ease of data use, but a loss of control over resources, and consequently costs. Note: A small exception is the Apache Spark Pool, which allows you to manage few parameters, such as the number and type of workers.
In conclusion, Microsoft Fabric is an all-in-one, ready for use solution that enables all types of users to manage and manipulate data in a unified space, but I think that a solution like Databricks or Snowflake is much more efficient (performance, cost, industrialization), while keeping the use of the PowerBI service for the Lakehouse, Warehouse, Data Science approach, centralized data governance and cost control, but won’t enable people with few technical skills to work properly with data.